













译者 | 张怡
审校 | 梁策 孙淑娟
就像国际汽车工程师学会(SAE)对自动驾驶汽车分级一样,为了预测人工智能系统的成本,给它们分个“级别”想必也是不错的选择。采用分级系统可以帮助组织计划和准备AI系统,且随着时间的推移,AI系统的复杂性也会不断增加。

Photo by Hitesh Choudhary on Unsplash
设计和构建人工智能系统不是件容易事。传统软件的大部分成本都在部署前的开发过程中,而AI系统的大部分成本都在部署后。人工智能系统的行为不断学习,且很可能会从最初的部署中改变。如果不持续投资数据和进行参数调整,机器学习模型会随着时间的推移而“退化”。设计决策直接影响人工智能系统的扩展能力,其难点就是理解AI系统如何随着时间的推移而发生变化。
在构建AI系统时,分级可以为不同AI系统的行为提供参考。进行分级并根据级别进行权衡可以帮助简化部署后的差异。
理解系统可能会发生何种行为变化,并将其纳入系统设计中是非常重要的。以下的分级框架概述了各级系统随时间变化的主要差异,我们可以在设计和操作系统时对这些差异加以利用。不同的系统可以处于不同的级别,而对其差异有一个整体的认知可以帮助组织更好的规划和执行。
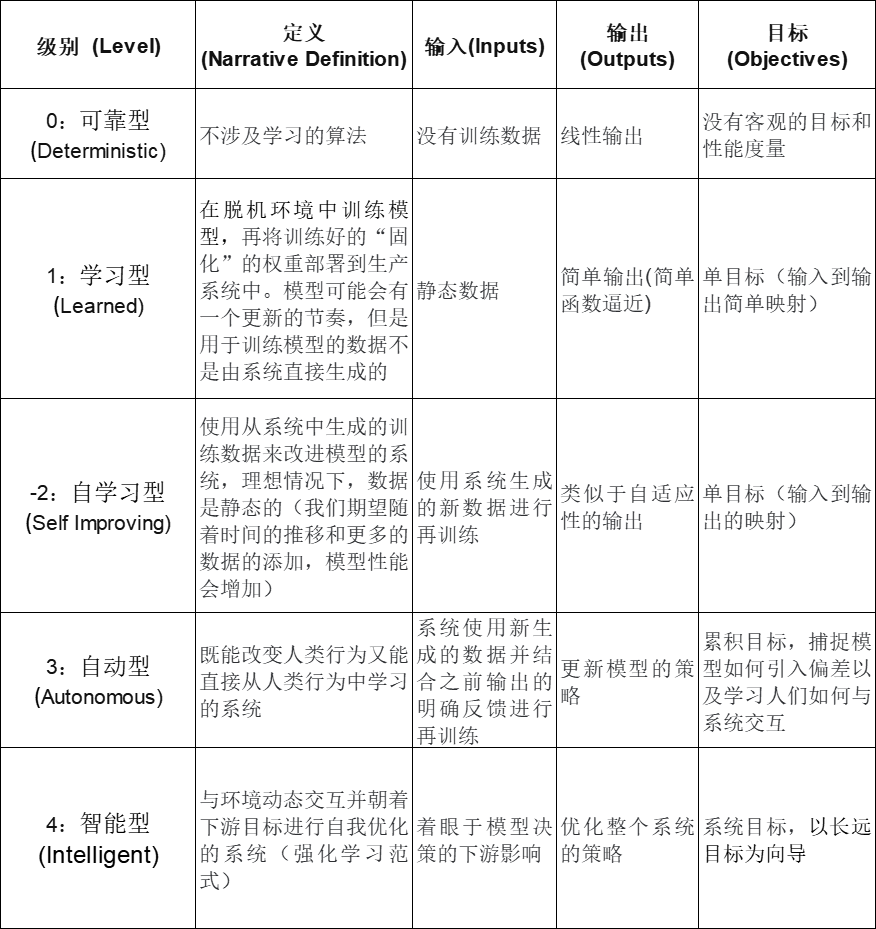
系统的复杂性可以由其输入(a)、输出(b)和目标(c)的范围来定义。
AI级别
一般来说,随着级别的上升,成本也会增加。比如我们设想将一个运行在1级的系统提升到2级,但是系统构建的复杂性和成本也会随着级别的上升而增加。显然,我们的新功能应该先从一个系统行为容易理解的“低”级别开始,再逐渐增加级别——随着级别的增加,系统的失败案例变得越难理解。
随着我们从传统软件(0级)升级到完全智能软件(4级),不同级别的AI系统差异明显,极大地影响了系统成本。级别4的系统基本上可以自行维护和改进,无需内部开发团队的任何工作。
升级是需要权衡的。例如,从1级到2级减少了持续的数据需求和定制工作,但引入了一个自我强化的偏差问题。选择升级需要认识到新的挑战,以及在设计AI系统时需要采取那些措施。
在系统升级过程中,其可扩展性、通用性、稳健性等均发挥关键作用。在第N级的项目上工作时,我们应该考虑达到第N+1级的工作成本和收益,同时应该根据自己的目标设定合适的分级,并意识到何时需要升级现有的AI系统。
0级:可靠型(传统型)Deterministic
不需要训练数据,不需要测试数据,不涉及学习的算法处于0级。
0级(计算机科学中的传统算法)的最大好处是非常可靠,只要解决了问题就是最优解。在某种程度上,很多的算法(比如二分搜索)都是对数据的“自适应”。我们通常不认为排序算法是“学习”的。学习涉及到记忆——系统在过去学习的基础上改变未来的行为。
然而,有些问题采用预先指定的算法很难解决。对于那些人类难以诠释的问题(如语音到文本、翻译、图像识别、语言提示等),它很难执行。
示例:
- 用于信用卡验证的Luhn算法
- 基于正则表达式的系统
- 信息检索算法,如TFIDF检索或BM25
- 基于字典的(Dictionary-based)拼写校正
注意:在某些情况下,可能会有少量参数需要调优。例如,ElasticSearch提供了修改BM25参数的能力(例如一键设置set and forget)。
Level 1:学习型Learned
静态训练数据,静态测试数据。
您可以在脱机环境中训练模型,再将训练好的“固化”的权重部署到生产系统中。模型可能会有一个更新的节奏,但是模型运行的环境不会影响模型。
Level 1可以让你尝试学习和部署任何功能,但训练数据是有限的。这是一个尝试不同类型解决方案的演练场。此外,对一些常见的问题(如语音识别),你可以从边际成本递减中获益。
Level 1的缺点是对单个用例的定制化学习:你需要为每个用例管理训练数据,而用例可能会随着时间的推移而改变,因此需要不断地添加训练数据以保持模型的性能。这个成本是难以承受的。
示例:
- 自定义文本分类模型
- 语音到文本(声学模型)
Level 2:自学习型Self-learning
动态+静态训练数据,静态测试数据。
Level 2是使用由系统生成的训练数据对模型进行改进的系统。在某些情况下,数据的生成是独立于模型的。所以我们希望随着时间的推移以及更多的数据加入模型,性能会增加;在其他情况下,模型干预会增强模型偏差,并且随着时间的推移,表现会变得更糟。为了消除模型偏差,我们需要静态数据集重新评估模型。
这样来看,Level 2性能似乎可以随着时间的推移而自动提高。但是如果不加以管理,系统可能会随着数据的增加变得更糟。因为本质上依赖于静态数据集(一开始生成自己模型的训练数据),处于Level 2的系统改进能力有限,而要解决这种模型偏差很有挑战性。
示例:
- Naive垃圾邮件过滤器
- 语音-文本模型(语言模型)
Level 3:自动型Autonomous (or self-correcting)
动态训练数据,动态测试数据。
Level 3系统既能改变人类的行为(例如建议一个操作并让用户选择),又能直接从该用户行为中学习(例如用户的选择偏好)。从2级升级到3级意味着系统的可靠性和总体可实现性能将大幅提高。
相较于Level 2,Level 3,系统可以随着时间的推移而改善。当然,它也更加复杂。它可能需要真正惊人的数据量,或者非常精心的设计,才能比简单的系统做得更好;但是它适应环境的能力也使测试非常困难,甚至可能出现灾难性的恶性循环。例如,测试人员纠正一个垃圾邮件过滤器——虽然人类只纠正了系统所做的错误分类,但是系统意识到其所有预测可能都是错误的(过于敏感),并将自己的预测整个颠倒过来。
Level 4:智能型Intelligent (or globally optimizing)
动态训练数据,动态测试数据,动态目标。
Level 4是既能与环境动态交互又能全局优化的系统。例如,AutoSuggest模型并不优化当前方法,而是优化一系列事件以达到最佳的对话框的目标。
虽然如何实现还有漫长的探索之路要走,Level 4的前景确实一片光明。精准定位问题,引入奖励与惩罚机制,评估模型的行为,这些都是重大而艰巨的任务。
附录:
原文链接:https://www.kdnuggets.com/2022/03/level-system-help-forecast-ai-costs.html
译者介绍
张怡,51CTO社区编辑,中级工程师。主要研究人工智能算法实现以及场景应用,对机器学习算法和自动控制算法有所了解和掌握,并将持续关注国内外人工智能技术的发展动态,特别是人工智能技术在智能网联汽车、智能家居等领域的具体实现及其应用。



















