













今天给大家分享一个知识点,是关于 MySQL 数据库架构演进的,因为很多兄弟天天基于 MySQL 做系统开发,但是写的系统都是那种低并发压力、小数据量的,所以哪怕上线了也就是这么正常跑着而已。
但是你知道你连接的这个 MySQL 数据库他到底能抗多大并发压力吗?如果 MySQL 数据库扛不住压力了,应该如何演进你知道吗?
一般业务系统运行流程图
首先,我们先来看一个最最基础的 Java 业务系统连接数据库运行的架构,其实简单来说,我们平时都是用 SpringBoot+SSM 技术栈开发一个 Java 业务系统的,用 Spring Boot 内嵌 Tomcat 就可以对外提供 Http 接口了。
然后最多现在会加上 Nacos+Dubbo 调用别的系统接口,数据全部靠连接 MySQL 数据库进行 crud 就可以了。
如下图:
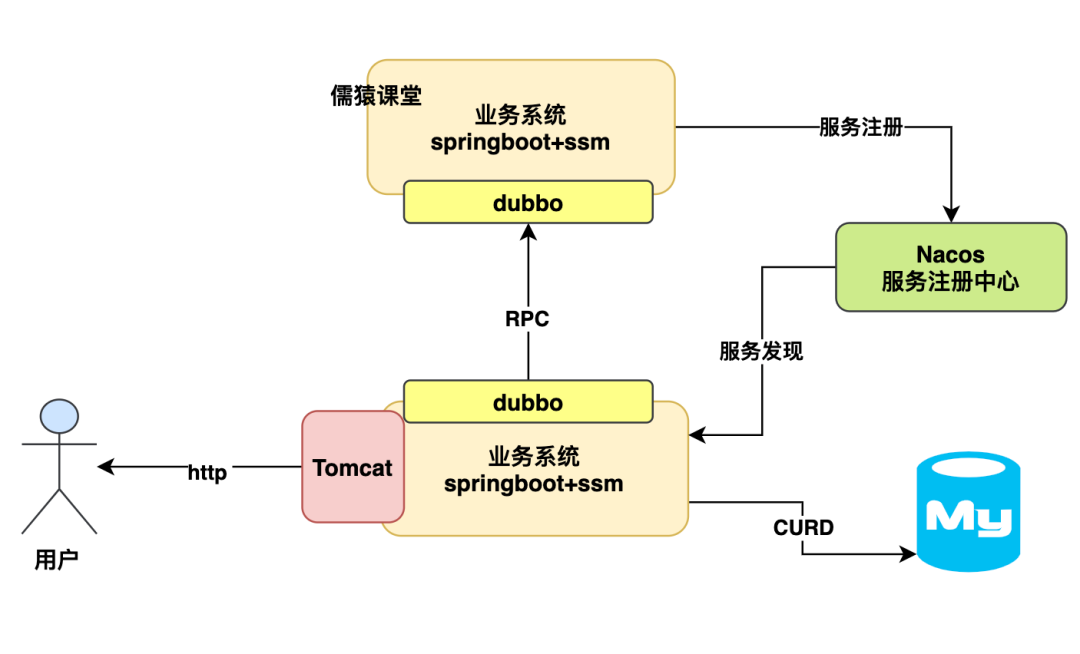
上面那种架构的系统,估计就是很多兄弟日常做的最多的系统架构了,有的兄弟稍微做的高大上一点,大概来说,可能就是会加入一些 ES、Redis、RocketMQ 一类的中间件简单使用一下。
但是大致来说也就这么回事了,那么还是回归主题,大家知道你上述那种系统下,他连接的数据库能抗多大压力吗?
一台 4 核 8G 的机器能扛多少并发量呢?
说实话,要解决这个问题,一般来说,不是先聊数据能抗多少压力,因为往往不是数据库先去抗高并发,而是你连接数据库的 Web 系统得先去抗高并发!也就是我们的 SpringBoot+SSM 那套业务系统能抗多高并发我们得先搞清楚!
所以要搞明白这个问题,就得先说一个主题,一般来说我们的 SpringBoot 应用系统大致就是部署在 2 核 4G 或者 4 核 8G 的机器上,这个机器配置其实是很关键的。
所以这里直接告诉大家一个经验值,即使说咱们如果部署的是一个 4 核 8G 的机器,然后 SpringBoot 内嵌的 Tomcat 默认开了 200 个线程来处理请求,接着每个请求都要读写多次数据库。
那么此时,大致来说你的一台机器可以抗大概 500~1000 这个并发量,具体多少得看你的接口复杂度。
如下图:
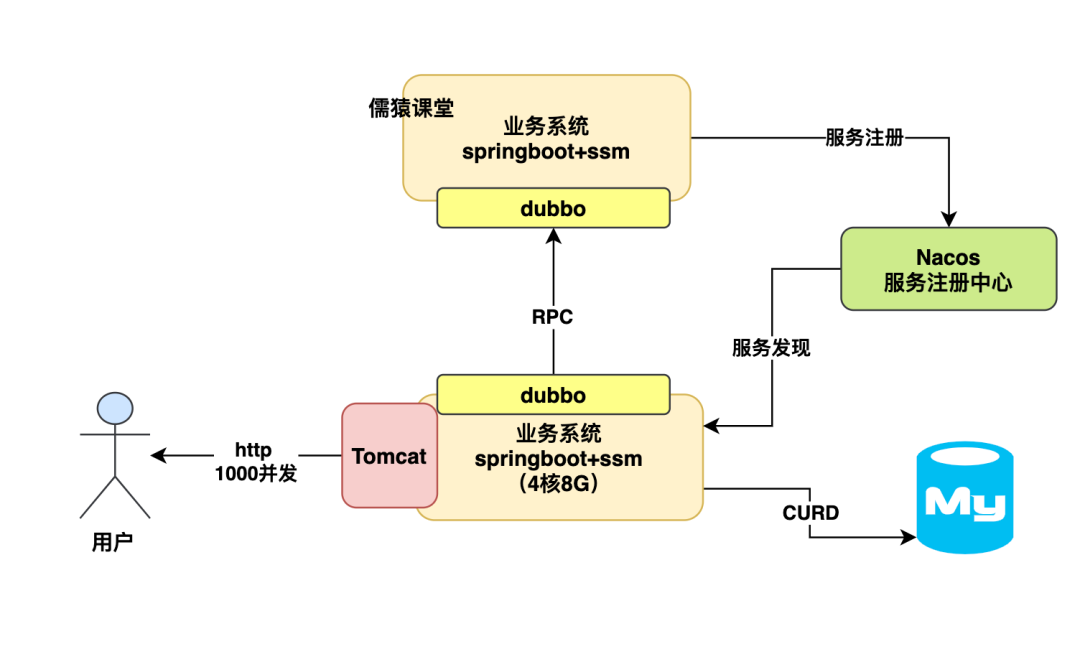
高并发来袭时数据库会先被打死吗?
所以其实一般来说,当你的高并发压力来袭的时候,通常不会是数据库先扛不住了,而是你的业务系统所在机器抗不住了。
比如你部署了 2 台机器,那么其实到每秒一两千并发的时候,这两台机器基本上 CPU 负载都得飙升到 90% 以上 ,压力很大,而且接口性能会开始往下掉很多了。
如下图:
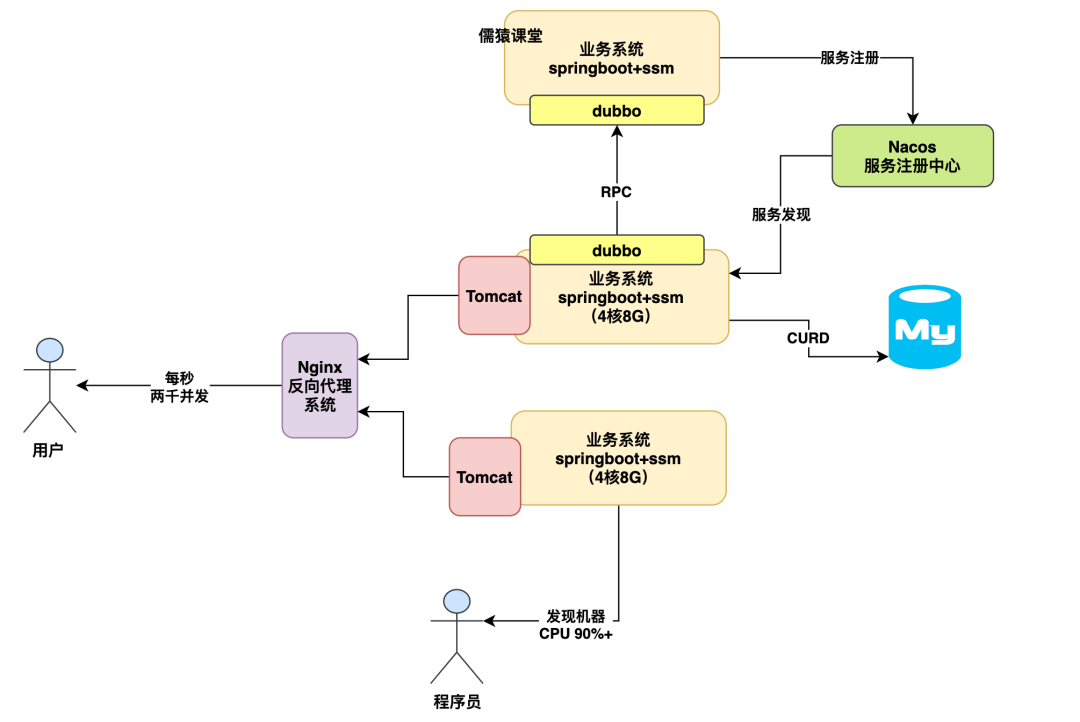
那么这个时候我们的数据库压力会如何呢?其实一般来说你的两台机器抗下每秒一两千的请求的时候后,数据库压力通常也会到一个小瓶颈,为什么呢?
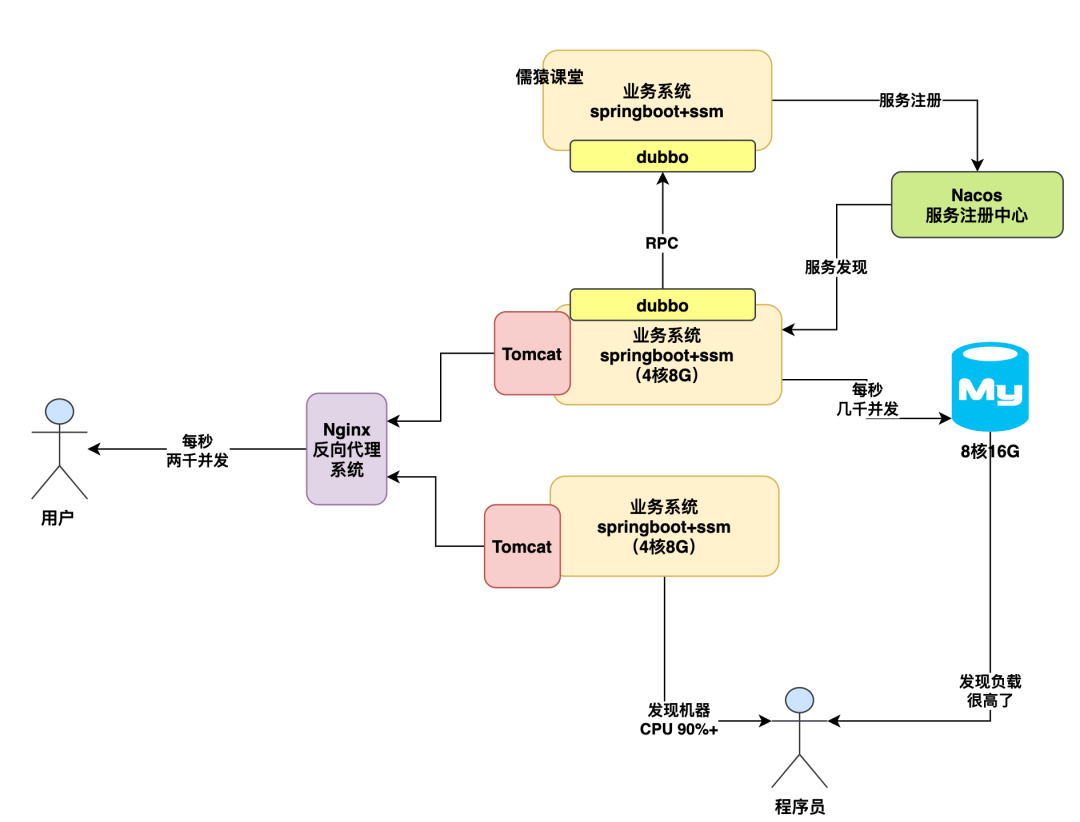
关键是你的业务系统处理每个业务请求的时候,他是会读写多次数据库的,所以业务系统的一次请求可能会导致数据库有多次请求,也正因为这样,所以此时可能你的数据库并发压力会到几千的样子。
8 核 16G 的数据库每秒大概可以抗多少并发压力?
那么所以下一个问题来了,你的数据库通常是部署在什么样配置的机器上?
一般来说给大家说,数据库的配置如果是那种特别低并发的场景,其实 2 核 4G 或者 4 核 8G 也是够了,但是如果是常规化一点的公司的生产环境数据库,通常会是 8 核 16G。
那么 8 核 16G 的数据库每秒大概可以抗多少并发压力?大体上来说,在几千这个数量级。
因为这个具体能抗多少并发也得看你数据库里的数据量以及你的 SQL 语句的复杂度,所以一般来说 8 核 16G 的机器,大概也就是抗到每秒几千并发就差不多了。
量再大基本就扛不住了,因为往往到这个量级下,数据库的 CPU、内存、网络、IO 的负载基本都很高了,尤其是 CPU,可能至少也在百分之七八十了。
如下图:
数据库架构可以从哪些方面优化?
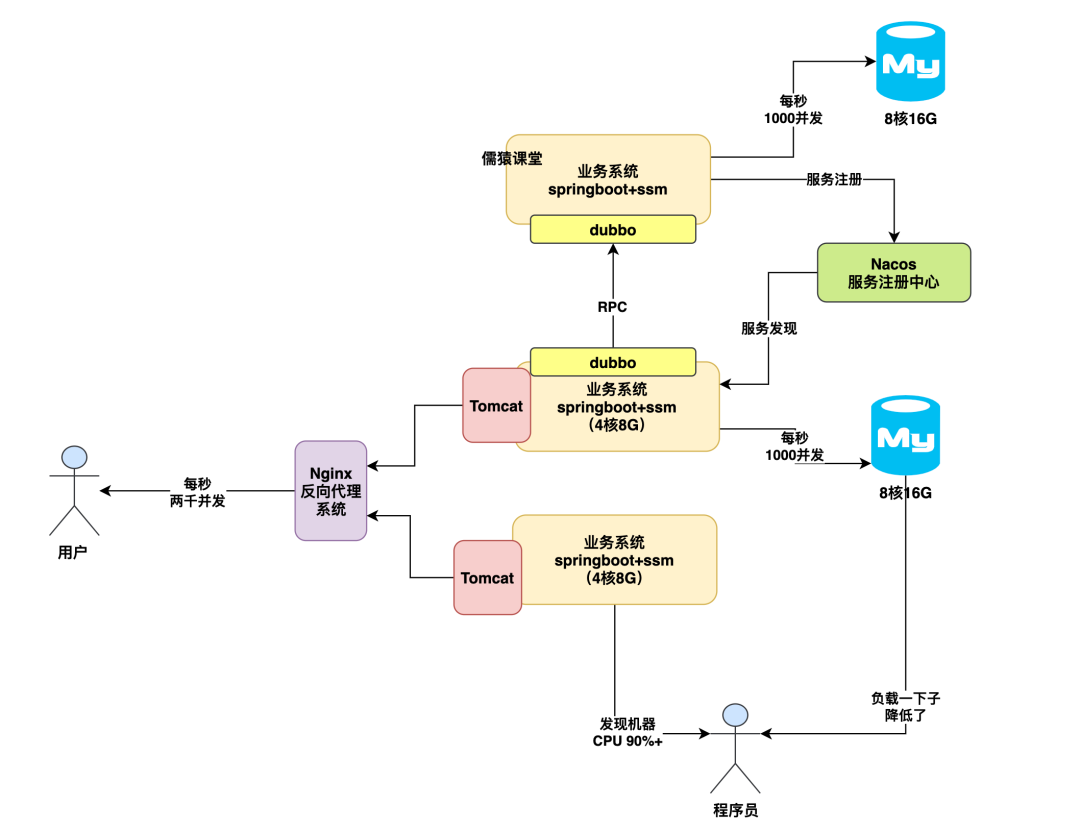
根据业务系统拆分多个数据库机器优化方案
那么接着说,如果到了这个并发压力之下,通常来说可以如何进行数据库架构的优化呢?
其实也简单,我们完全可以加机器,把数据库部署到多台机器上去。因为通常来说,我们的一个数据库里会放很多业务系统的 db 和 tables,所以首先就是可以按照业务系统来进行拆分。
比如说多加一台机器,再部署一个数据库,然后这里放一部分业务系统的 db 和 tables,老数据库机器放另外一部分业务系统的 db 和 tables,此时一下子就可以缓解老数据库机器的压力了。
如下图:
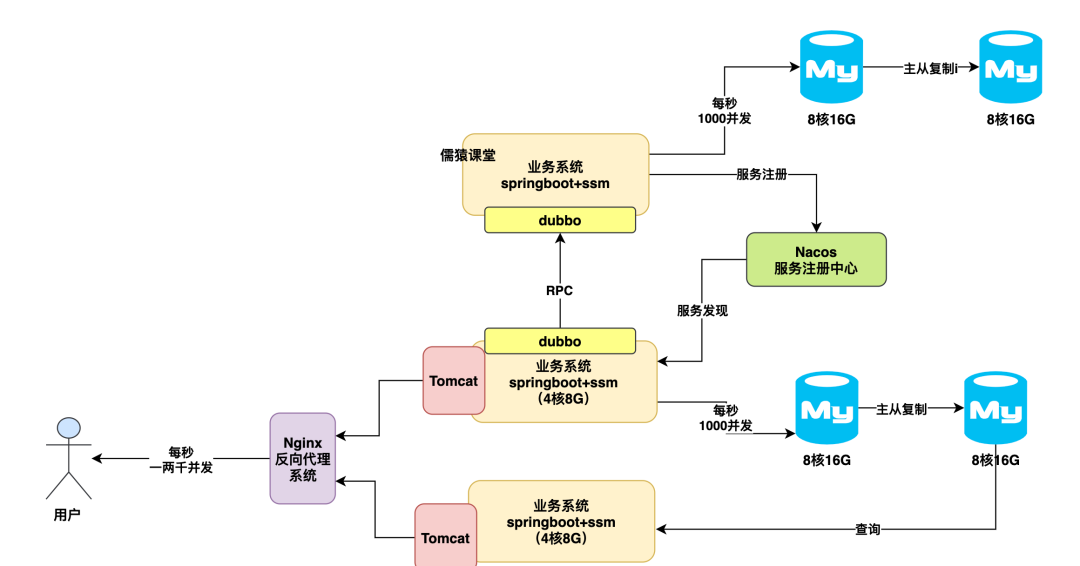
读写分离架构优化方案
那么接着问题来了,如果说并发压力继续提升,导致拆分出去的两台数据库压力越来越大了呢?
此时可以上一招,叫做读写分离,就是说给每个数据库挂一个从库,让主数据库基于 binlog 数据更新日志同步复制给从数据库,让主从数据库保持数据一致。
然后我们的系统其实可以往主库里写入,在从库里查询,此时就又可以缓解原来的主数据库的压力了。
如下图:
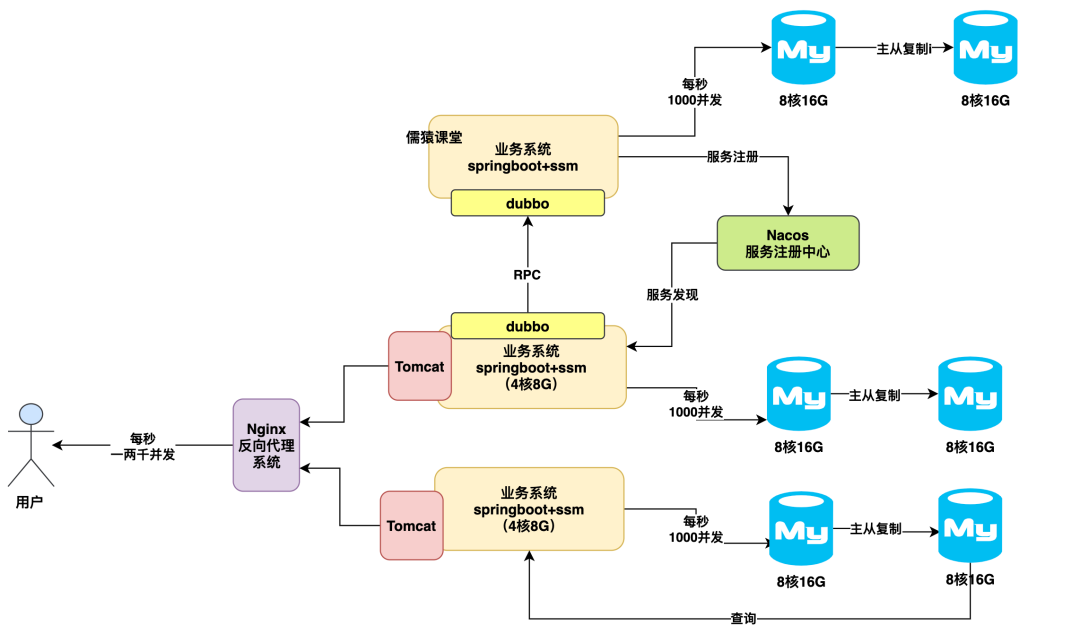
分库分表架构优化方案
再往下说,如果说即使是给主数据库挂了从库,然后接着并发压力继续提升,让我们的主数据库写入压力过大,每秒几千写入,又要扛不住了呢?
此时就只能上终极方案,分库分表了,就是把主库拆分为多个库,每个库里放一个表的部分数据,然后用多个主库抗高并发写入压力,这样就可以再次分散我们的压力了。
如下图所示:
总结
好了,今天分享的知识就到这里了,其实我们的数据库架构演进基本上就是按照今天说的这个顺序和思路逐步逐步的演进的。
刚开始你单台数据库机器抗几千并发扛不住了,就按照业务系统拆分多个数据库机器,然后再扛不住了,就上主从架构分摊读写压力,再扛不住了就分库分表,多个机器抗数据库写入压力,最后总是可以用数据库架构抗住高并发压力的。





















