












众所周知,Kubernetes QOS 分为三个级别:
- Guaranteed:Pod 里的每个容器都必须有内存/CPU 限制和请求,而且值必须相等。如果一个容器只指明limit而未设定request,则request的值等于limit值。
- Burstable:Pod 里至少有一个容器有内存或者 CPU 请求且不满足 Guarantee 等级的要求,即内存/CPU 的值设置的不同。
- BestEffort:容器必须没有任何内存或者 CPU 的限制或请求。
谷歌的最佳实践告诉你,重要服务一定要配置 Guaranteed 的,这样在资源不足的时候可以保证你的重要服务不被驱逐。
最佳实践要求你这样配置是从运维和后期运营的角度来说的,团队刚起步,不设置资源请求和限制的情况下基本可以正常工作,但随着团队和项目的增长,您将开始遇到稳定性问题。服务之间相互影响,这时候可能需要为服务添加限制,并且可以让您免于遇到许多令人头疼的问题。
这里我们应该已经清楚,通过遵循最佳实践,使整个集群具有更大的灵活性和可靠性。
但是当涉及到 CPU 限制时,事情就变得有趣了。CPU 是可压缩资源。如果您的应用开始达到 CPU 限制,Kubernetes 就会开始限制您的容器。这意味着 CPU 将受到人为限制,使您的应用程序性能可能更差!
1. 为什么会这样呢?
因为当你在容器编排器中设置硬 CPU 限制时,内核使用完全公平调度程序 (CFS) Cgroup来强制执行这些限制。CFS Cgroup 机制使用两个设置来管理 CPU 分配:配额和周期。当应用程序在给定时间段内使用超过其分配的 CPU 配额时,它会受到限制,直到下一个时间段。
cgroup 的所有 CPU 指标都位于/sys/fs/cgroup/cpu,cpuacct/<container>. 配额和期间设置位于cpu.cfs_quota_us和中cpu.cfs_period_us。

您还可以查看限制指标 cpu.stat。在里面 cpu.stat 你会发现:
- nr_periods– cgroup 任何线程可运行的周期数
- nr_throttled– 应用程序使用其全部配额并受到限制的可运行周期数
- throttled_time– 控制 cgroup 中各个线程的总时间
2. 举个简单的例子
单线程应用程序在具有 cgroup 约束的 CPU 上运行。此应用程序需要 200 毫秒的处理时间来完成一个请求。不受约束,它的响应看起来如下图。
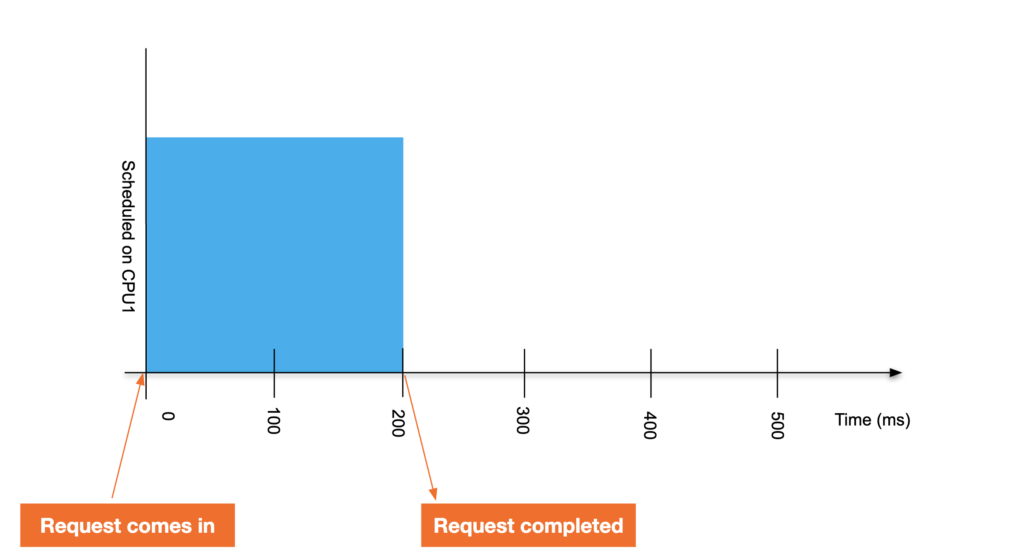 没有配置限制的请求
没有配置限制的请求
现在,假设我们为应用程序分配了 0.4 CPU 的 CPU 限制。这意味着应用程序每 100 毫秒周期获得 40 毫秒的运行时间——即使这些时间 CPU 没有其他工作要做。200 毫秒的请求现在需要 440 毫秒才能完成。
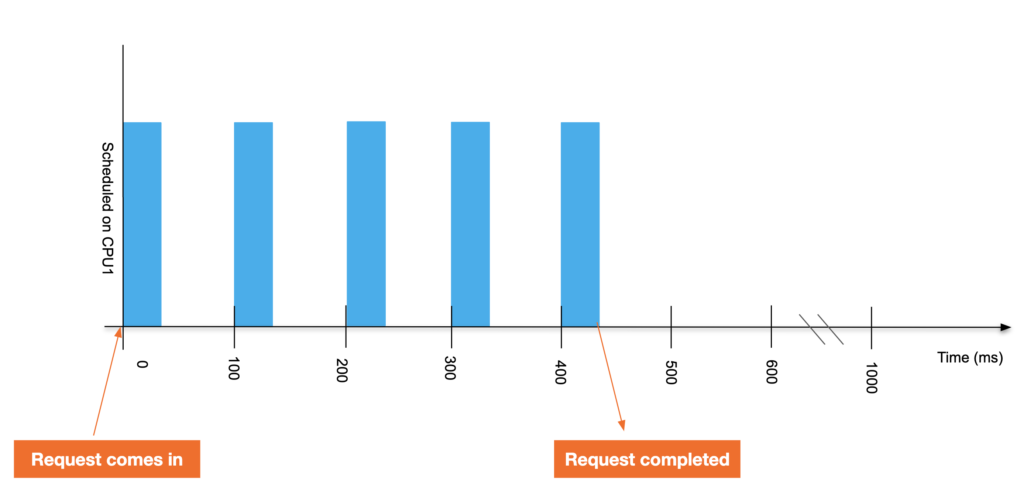 配置限制的请求
配置限制的请求
这个时候你查看下所在容器路径下的 cpu.stat throttled_time 你会发现被限制了 240ms(对于每 100 毫秒的周期,应用程序只能运行 40 毫秒,并被限制 60 毫秒。它已被限制了 4 个周期,因此 4 * 60 = 240 毫秒。)
换一个通俗点的说法,当您要求 1 个 CPU 时,这意味着您的应用程序每秒可以使用 1 个 CPU 内核。如果它是一个单线程,它将能够一直使用一个内核。但是,如果它有 2 个线程,则每秒可以无限制地使用 2 个核心秒。因此,有了这个限制,它可以在 1/2 秒内完全使用 2 个核心,然后会受到限制。(虽然这并不是真正以秒为单位来衡量的,实际是us,但我发现这样更容易理解)。
看到这里,你可能会说,这只是一种约束,超出范围的资源,就是不能使用,否则将被限制。
3. 是否存在不必要的限制
并没有这么简单,很多人反馈遭到了不必要的 cgroup 限制,甚至还没有 CPU 上限,这里有激烈的讨论:
-
https://github.com/kubernetes/kubernetes/issues/67577 -
https://github.com/kubernetes/kubernetes/issues/51135 -
https://github.com/kubernetes/kubernetes/issues/70585 -
https://github.com/kubernetes/kubernetes/pull/75682
运行容器时要检查的关键指标是throttling. 这表明您的容器被限制的次数。我们发现很多容器无论 CPU 使用率是否接近极限都会受到限制。如下一个热心网友反馈的案例:
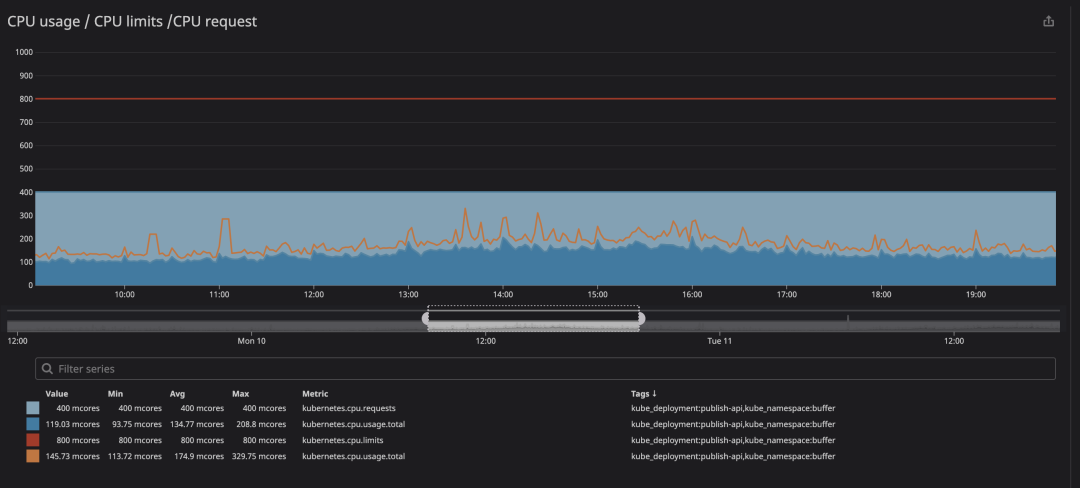
在动画中可以看到 CPU 限制设置为800m(0.8 个核心,80% 的核心),峰值使用率最高为200m(20% 的核心)。看到之后,我们可能会认为我们有足够的 CPU 让服务在它节流之前运行,对吧?. 现在看看这个:
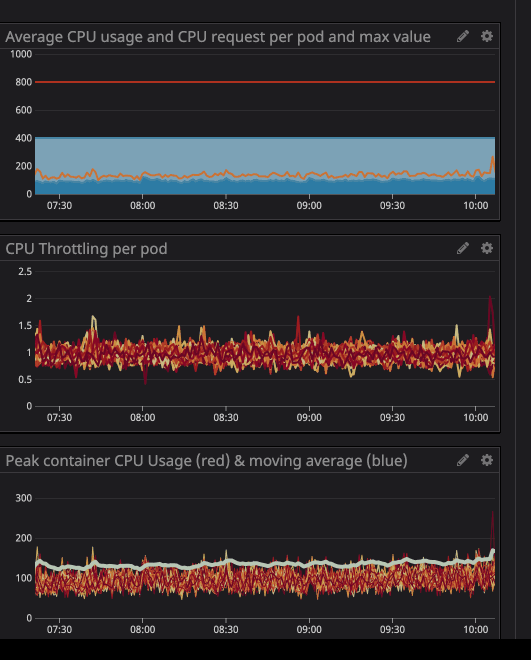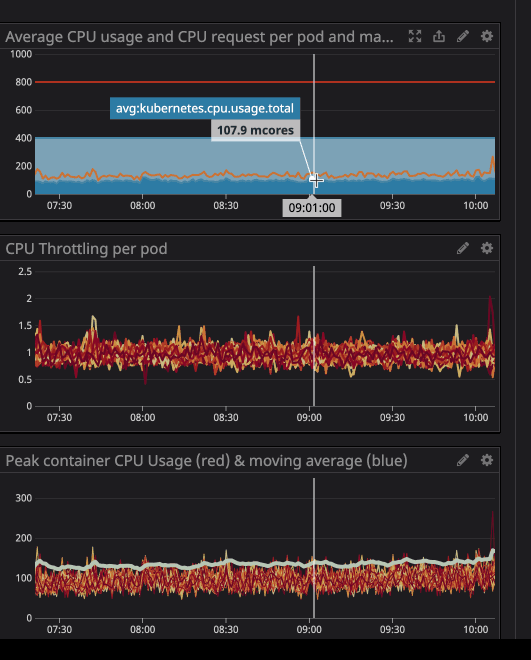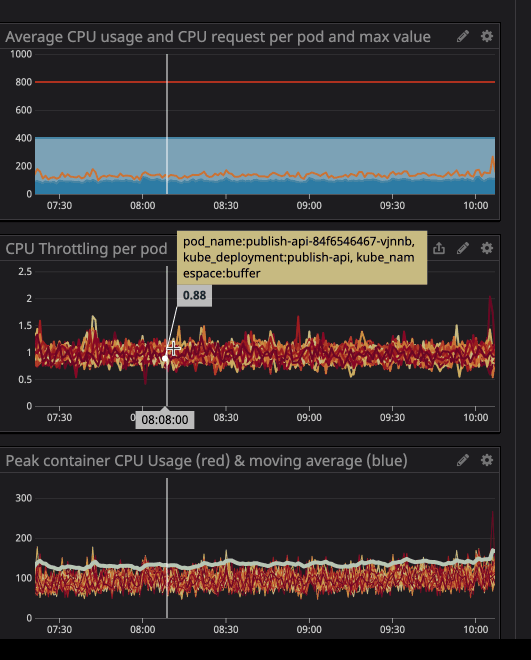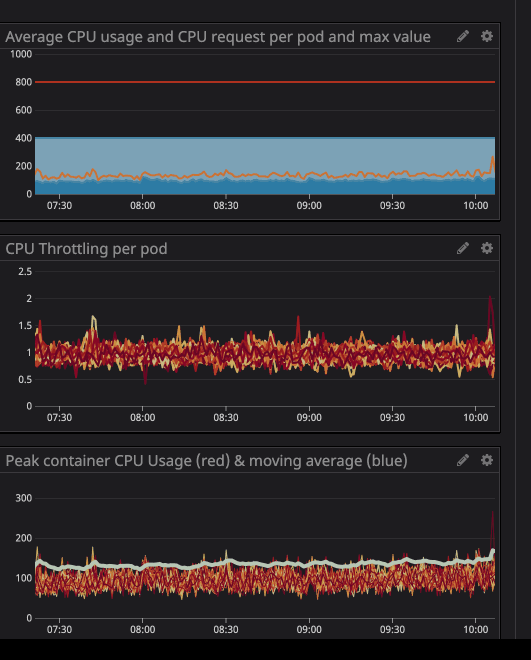
即使 CPU 使用率低于 CPU 限制,您也会注意到发生了 CPU 限制。最大 CPU 使用率甚至没有接近 CPU 限制。
限制就意味着服务性能下降和延迟增高。
4. 什么原因导致的呢?
本质上来说,这个问题是 linux 内核导致,具体可以看下这个视频:https://www.youtube.com/watch?v=UE7QX98-kO0
这个视频大概意思是这样的。
这里有一个多线程守护进程的例子,它有两个工作线程,每个工作线程都固定在自己的核心上。如下图,第一个图显示了 cgroup 在一段时间内的全局配额。这从 20ms 的配额开始,这与 0.2 CPU 相关。中间的图表显示分配给每个 CPU 队列的配额,底部的图表显示实际工作线程在其 CPU 上运行的时间。
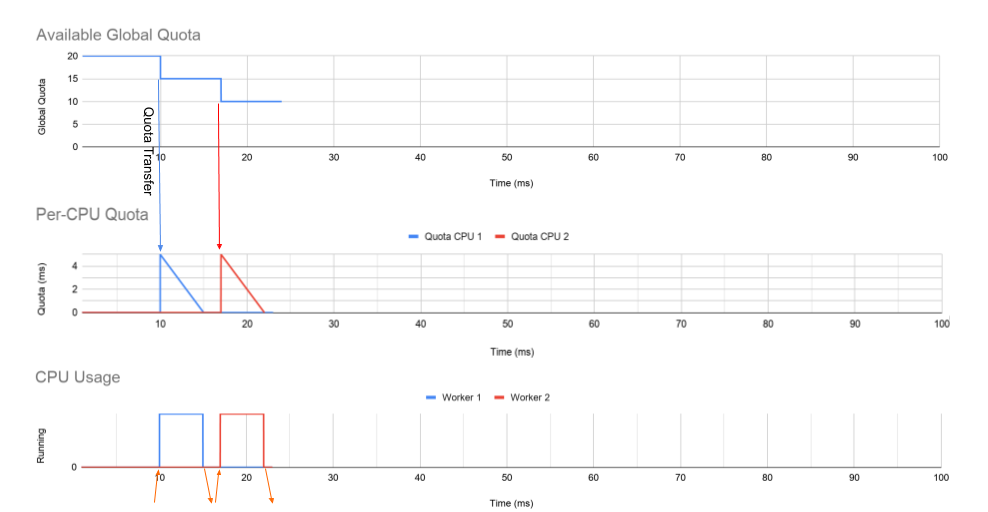
在 10 毫秒:
- Worker 1 收到了一个请求。
- 一部分配额从全局配额转移到 CPU 1 的每个 CPU 队列。
- Worker 1 需要 5ms 来处理和响应请求。
在 17 毫秒:
- Worker 2 收到了一个请求。
- 一部分配额从全局配额转移到 CPU 2 的每个 CPU 队列。
Worker 1 需要精确 5 毫秒来响应请求的机会是非常不现实的。如果请求需要其他一些处理时间会发生什么?
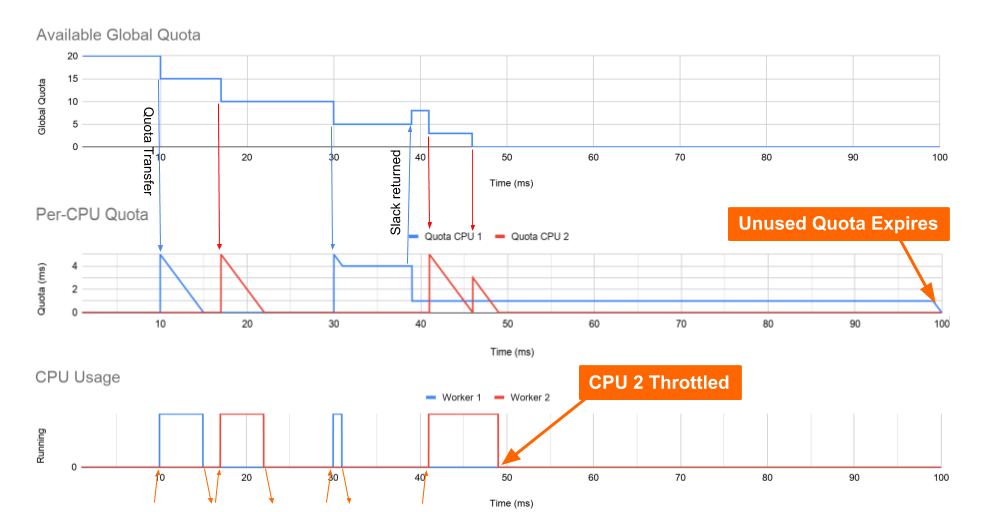
在 30 毫秒:
- Worker 1 收到了一个请求。
- Worker 1 只需要 1 毫秒来处理请求,而 CPU 1 的每个 CPU 存储桶上还剩下 4 毫秒。
- 由于每个 CPU 运行队列上还有剩余时间,但 CPU 1 上没有更多可运行线程,因此设置了一个计时器以将 slack 配额返回给全局存储桶。这个定时器在worker 1停止运行后设置为7ms。
在 38 毫秒:
- CPU 1 上设置的 slack 计时器触发并将除 1 ms 之外的所有配额返回到全局配额池。
- 这会在 CPU 1 上留下 1 毫秒的配额。
在 41 毫秒:
- Worker 2 收到一个长请求。
- 所有剩余时间都从全局存储桶转移到 CPU 2 的 per-CPU 存储桶,Worker 2 使用所有时间。
在 49 毫秒:
- CPU 2 上的 Worker 2 现在在未完成请求的情况下受到限制。
- 尽管 CPU 1 仍有 1ms 的配额,但仍会发生这种情况。
虽然 1 毫秒可能对双核机器没有太大影响,但这些毫秒在高核数机器上加起来。如果我们在 88 核 (n) 机器上遇到此行为,我们可能会在每个周期内耗费 87 (n-1) 毫秒。那可能无法使用的 87 毫秒或 0.87 CPU(每个Container)。这就是我们通过过度节流来达到低配额使用的方式。在最好的情况下,如果修复,使受影响的应用程序的每个实例的可用 CPU 增加 0.87,或者所需的 CPU 配额相应减少。这些优势将在我们的集群中提高应用程序密度并缩短应用程序响应时间。
当 8 核和 10 核机器这个问题基本上没有引起注意。现在核心数量风靡一时,这个问题变得更加明显。这就是为什么我们注意到在更高核心数的机器上运行同一应用程序时会增加限制。
总结来说,时钟偏差限制问题,这导致每个时期的配额都受到严格限制。这个问题一直是存在的,至少自提交 512ac999 和内核 v4.18 以来,它就是这样工作的。
5. linux 内核是如何解决这个问题
当且仅当每个 CPU 的过期时间与全局过期时间匹配时,预补丁代码才会在运行时过期cfs_rq->runtime_expires != cfs_b->runtime_expires。通过检测内核,我证明了这种情况在我的节点上几乎从未出现过。因此,那 1 毫秒永不过期。该补丁将此逻辑从基于时钟时间更改为周期序列计数,解决了内核中长期存在的错误。代码如下:
- if (cfs_rq->runtime_expires != cfs_b->runtime_expires) {
+ if (cfs_rq->expires_seq == cfs_b->expires_seq) {
/* 延长本地期限,漂移以 2 个滴答为界 */
cfs_rq->runtime_expires + = TICK_NSEC;
} else {
/* 全局截止日期提前,过期已过 */
cfs_rq->runtime_remaining = 0;
}
修改问题 5.4+ 主线内核的一部分。它们已被反向移植到许多可用的内核中:
- RHEL 7: 3.10.0–1062.8.1.el7+
- RHEL 8: 4.18.0–147.2.1.el8_1+
- Linux-stable: 4.14.154+, 4.19.84+, 5.3.9+
- Ubuntu: 4.15.0–67+, 5.3.0–24+
- Redhat Enterprise Linux:
- CoreOS: v4.19.84+
该错误https://git.kernel.org/pub/scm/linux/kernel/git/torvalds/linux.git/commit/?id=763a9ec06c4已被修复并合并到运行 4.19 或更高版本的 Linux 发行版的内核中。
但是,在阅读kubernetes issue时https://github.com/kubernetes/kubernetes/issues/67577,我们可以看到各种 Linux 项目一直在引用这个 issue,所以我猜一些 Linux 发行版仍然存在这个 bug,并且正在努力整合修复。
如果你的 Linux 发行版的内核版本低于 4.19,我建议你为你的节点升级到最新的 Linux 发行版,但无论如何,你应该尝试移除 CPU 限制并查看是否有任何限制.
6. 总结
监控你的容器,是否因为 throttle 而导致的性能不佳,如果确实发生了,最好通过分批升级内核版本解决,如果无法升级,可以通过方式解决:
解除限制(个人觉得这个并不是一个好主意)
- 有性能要求的 Pod 调度到带特定污点的节点;
- 对这些 Pod 删除 CPU 限制,可以考虑在 namespace 级别添加限制。
增加资源
另外 CPU throttle 节流主要是因为 CPU 限制较低。它的限制影响 Cgroup 的行为。因此,一个快速解决该问题的方法是根据监控将限值提高 10-25%,以确保降低峰值或完全避免峰值。
自动扩容
因为将 CPU 请求和限制设置为相同的值通常会给人们他们所期望的行为,解决此问题的简单方法是将 CPU 请求和限制设置为相同的值并添加 HPA。让 Pod 根据负载进行自动扩缩容。























