大家好,欢迎来到Tlog4J课堂,我是Jensen。
分布式CAP定理大家也耳熟能详了,CAP指的是分布式系统中的三个特性:
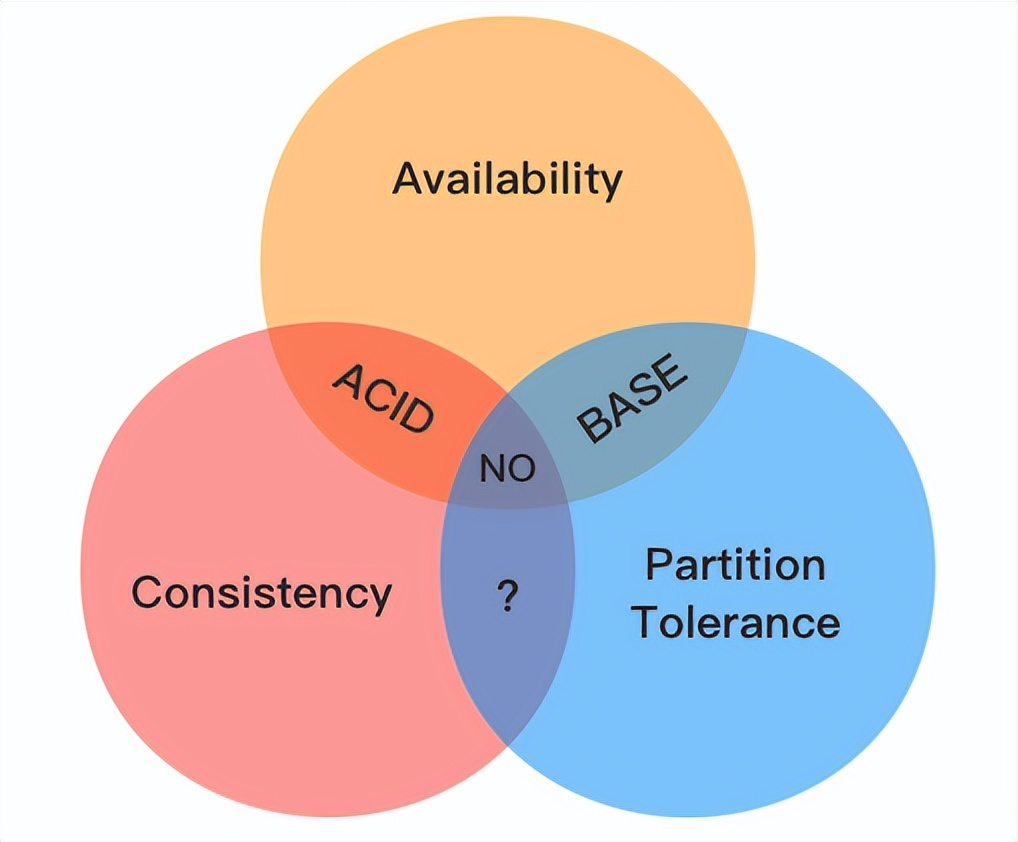
在我之前的文章也有提到过——CAP是分布式系统中三个维度的“客户承诺”:
- 一致性(Consistency):要么我给你返回一个错误,要么我给你返回绝对一致的最新数据,强调数据正确。
- 可用性(Availibility):我一定会给你返回数据,不会给你返回错误,但不保证数据最新,强调的是服务不出错。
- 分区容错性(Partition Tolerance):我会一直运行,不管我的内部出现何种数据同步问题,强调的是不挂掉。
在Jeff Hodges精彩的博文笔记中,他建议我们用 CAP 定理来评论分布式系统,并且很多人都听取了这个建议,描述他们的系统为“CP” (有一致性但在网络分区的时候不可用),“AP”(可用但是在网络分区的时候不一致) 或者有时候 “CA”。
那这次咱们再深入探讨一下,不同的系统按CP/AP来划分,到底合不合理。
回过头来看一致性
首先我们要了解,数据的一致性问题存在于计算机软硬件层面的任意一个数据拷贝的环节,如CPU与内存的数据拷贝、内存间的数据拷贝、内存与磁盘的数据拷贝、计算机之间的网络通讯等等。
而分布式系统是基于软件系统的,系统分布在不同的计算机必然会产生网络通讯延迟或网络分区的情况,以我们现在的计算机技术是无法100%解决一致性问题的。
CAP中的一致性是可线性化的意思,它是非常特殊、非常强的一致性,虽然说ACID中的C也是一致性,但和CAP的一致性没有任何关系。
那什么是可线性化呢?
举个例子:如果B操作在完成A操作成功之后,那么整个系统对B操作来说必须表现为A操作已经完成了或者更新的状态。
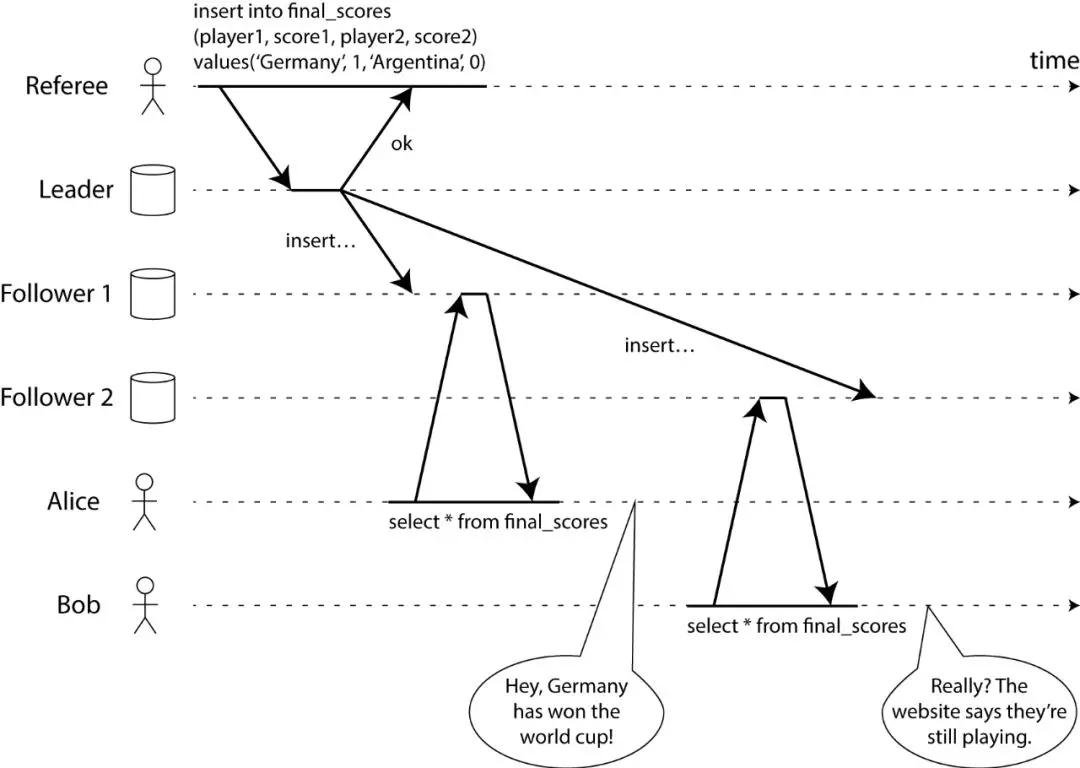
这张图展示了 Alice 还有 Bob, 他们在同一个房间,都在用他们的手机查询 2014 年世界杯的决赛结果。
就在最终结果刚发布之后,Alice 刷新了页面,看到了宣布冠军的消息,而且很兴奋地告诉了 Bob。
Bob 马上也重新加载了他手机上的页面,但是他的请求被送到了一个数据库的拷贝,还没有拿到产生结果的数据,结果他的手机上显示决赛还正在进行。
如果 Alice 和 Bob 同时刷新,拿到了不一样的结果,并不会太让人意外,因为他们不知道具体服务器到底是先处理了他们中哪一个请求。
但是 Bob 知道他刷新页面是在 Alice 告诉了他最终结果之后的,所以他预期他查询的结果一定比 Alice 的更新,但事实是他却拿到了旧的结果,这就违反了可线性化。
只有 Bob 通过另外一个沟通渠道从 Alice 那里知道了结果, Bob 才能知道他的请求一定在 Alice 之后。
如果 Bob 没有从 Alice 那里听到比赛已经结束了,他就不会知道他看到的结果是旧的。
如果你在建一个数据库,你不知道用户们会有什么另外的沟通渠道,所以,如果你想提供可线性化访问,你就需要让你的数据库看起来就好像只有一个拷贝,虽然实际上可能有多个备份在多个地方。
这是一个非常昂贵的属性,因为它要求你做很多协调工作,甚至你电脑上的CPU都不提供本地内存的可线性化访问!
在现代的CPU上,你需要用Memory Barrier指令来达到可线性化访问,甚至测试一个系统是不是可线性化的也是非常困难的。
所以说,脱离了关注点,讨论一致性没有多大意义。
回过头来看可用性
可用性在CAP中是定义为“每一个请求如果被一个工作中的[数据库]节点收到,那一定要返回[非错误的]结果”。
注意到,这里一部分节点可以处理这个请求是不充分的,任意一个工作中的节点都要可以处理这个请求,所以很多自称高可用的系统通常并没有满足这里的可用性的定义,它们只是做了故障转移或者是熔断降级而已。
CAP中根本没有提到延迟,而我们其实对延迟比可用性更关心,事实上,满足CAP可用性的系统可以花任意长的时间来回复一个请求,而且同时保持可用性这个属性。
但如果你的系统要花两分钟来加载一个页面,你的用户绝对不会认为它是“可用的”,这也是为什么现在互联网项目大多只允许2~10秒的请求延迟。
CP和AP的取舍
CAP定理只考虑了网络分区这一种故障情况(比如所有节点还在运行,但是他们之间的网络已经不工作了),这种故障绝对会发生,但是这不是唯一会出故障的地方。
节点可以整个崩溃或者重启,你可能没有足够的磁盘空间,你可能会遇到一个软件故障(bug),等等,在建分布式系统的时候,你需要考虑到更多得多的问题,如果太关注CAP就容易导致忽略了其他重要的问题。
那为什么在网络分区的情况下,我们要放弃可用性和一致性中的一个呢?
举个例子:你的数据库有两个拷贝在两个不同的数据中心,具体怎么做备份并不重要,可以是Single-Master,或者多个Leader,或者基于Quorum的备份,要求是当数据被写到一个数据中心的时候,它也一定要被写到另一个数据中心。
假设Client只连接到其中一个数据中心,而且连接两个数据中心的网络故障了,网络中断了就是我们所说的网络分区的意思,接下来会怎样呢?
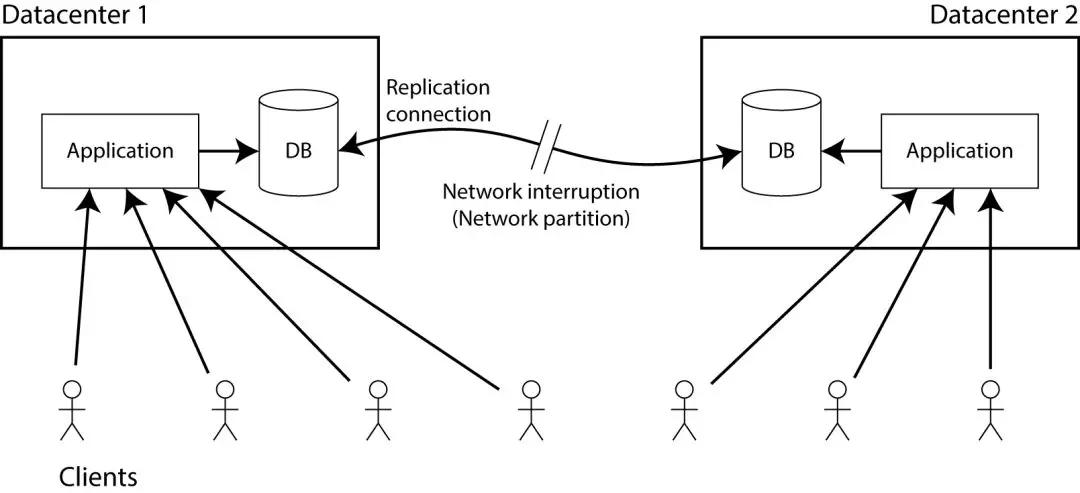
我们有两个选择:
- 应用还是被允许写到数据库,两边的数据库还是完全可用的。但是一旦两个数据库之间的网络中断了,任何一个数据中心的写操作就不会同步到另一个数据中心。这违反了可线性化(用之前的例子,Alice 可能链接到了一号数据中心,而 Bob 连接到了二号数据中心)。
- 如果你不想失去可线性化,就必须保证你的读写操作都在同一个数据中心,你可能叫它 Leader,另一个数据中心,因为网络故障不能被更新,就必须停止接收读写操作,直到网络恢复,两边数据库又进行同步。所以虽然非Leader数据库正常运行,但是他却不能处理请求,这就违反了 CAP 的可用性定义。
这个其实就是 CAP 定理的证明,咱们这里的例子用到了两个数据中心,但对于一个数据中心内的网络故障也同样适用,之所以这里用两个数据中心是因为更容易考虑这个问题。
当一个系统选择了可线性化,也就是说不是 CAP 可用的,并不意味着网络分区一定会造成应用停运。
如果你可以把用户的流量转移到Leader数据库,那么用户根本就不会注意到任何问题。
实际应用中的可用性和CAP可用性并不相同,咱们应用的可用性多数是通过SLA来衡量的,比如99.9%正确的请求一定要在一秒钟之内返回成功,这实际上是一种整体的衡量。
但是一个系统无论是否满足CAP可用性其实都可以满足这样的SLA,在实际操作中,跨多个数据中心的系统经常是通过异步备份的,所以不是可线性化的。
但是做出这个选择的原因经常是因为远距离网络的延迟,而不是仅仅为了处理数据中心的网络故障。
写在最后
CAP定理其实是一个被简化了的理论,以致于被大众广泛地误解了,实际上CAP是一个非常精确的定义。
其实大部分软件都不在CP/AP这两类中,但人们还是强行把软件分为这两类,这导致为了适用,不可避免地改变对“一致性”或者“可用性”的定义,如果用词的定义改变了,CAP定理自己也不适用了,那CP/AP划分也就完全没有意义了。
所以,在技术面试的时候,我再也不会问“哪些框架是CP的,哪些框架是AP的”这个问题了,这么问其实没多大意义。
从另一方面看,CAP也是被广泛接受的分布式基础理论,很多框架也可以通过不同的配置实现广义上的CP/AP,与其花时间跟别人解释一堆按CP/AP来划分系统是怎么不合理的,不如坦然接受现状,但是别忘了,心中也要有自己的答案。
独立思考,保持好奇心和耐心。