前端监控现状
近年来,前端监控是越来越火,目前已经有很多成熟的产品供我们选择使用,如下图所示

有这么多监控平台,那为什么还要学习自研前端监控?
- 一方面人家是要钱的。
- 另一方面自己的项目需要定制化的功能。
前端监控的目的
- 提升用户体验。
- 更快的发现发现异常、定位异常、解决异常。
- 了解业务数据,指导产品升级——数据驱动的思想。
前端监控的流程
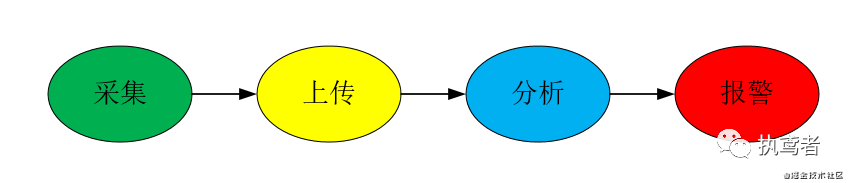
采集
前端监控的第一个步骤就是数据采集,采集的信息包含环境信息、性能信息、异常信息、业务信息。
环境信息
环境信息是每个监控系统必备的内容,毕竟排查问题的时候需要知道来自哪个页面、浏览器是谁、操作用户是谁……,这样才能快速定位问题,解决问题。一般这些常见的环境信息主要包含:
- url:正在监控的页面,该页面可能会出现性能、异常问题。获取方式为:
- window.location.href.
- ua:访问该页面时该用户的userAgent信息,包含操作系统和浏览器的类型、版本等。获取方式为:
- window.navigator.userAgent
- token:记录当前用户是谁。通过记录该用户是谁。
- 一方面方便将该用户的所有监控信息建立联系,方便数据分析;
- 另一方面通过该标识可以查看该用户的所有操作,方便复现问题。
性能信息
页面的性能直接影响了用户留存率,,Google DoubleClick 研究表明:如果一个移动端页面加载时长超过 3 秒,用户就会放弃而离开。BBC 发现网页加载时长每增加 1 秒,用户就会流失 10%。,Google DoubleClick 研究表明:如果一个移动端页面加载时长超过 3 秒,用户就会放弃而离开。BBC 发现网页加载时长每增加 1 秒,用户就会流失 10%。所以我们的追求就是提高页面的性能,为了提高性能需要监控哪些指标呢?
指标分类
指标有很多,我总结为以下两个方面:网络层面和页面展示层面。
网络层面
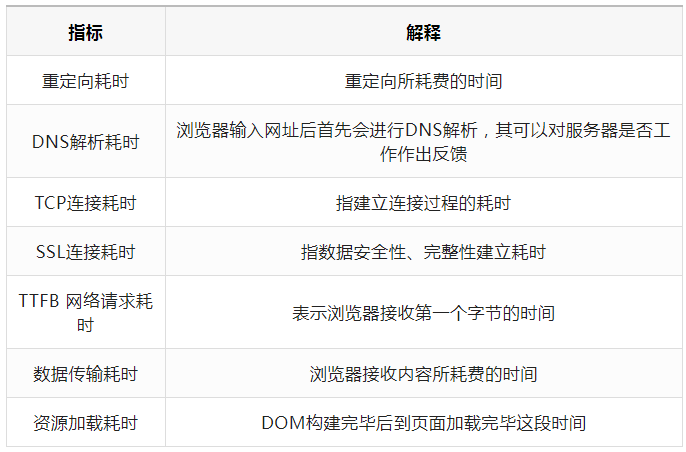
从网络层面来看涉及的指标有:重定向耗时、DNS解析耗时、TCP连接耗时、SSL耗时、TTFB网络请求耗时、数据传输耗时、资源加载耗时……,各个指标的解释如下表所示:
页面展示层面
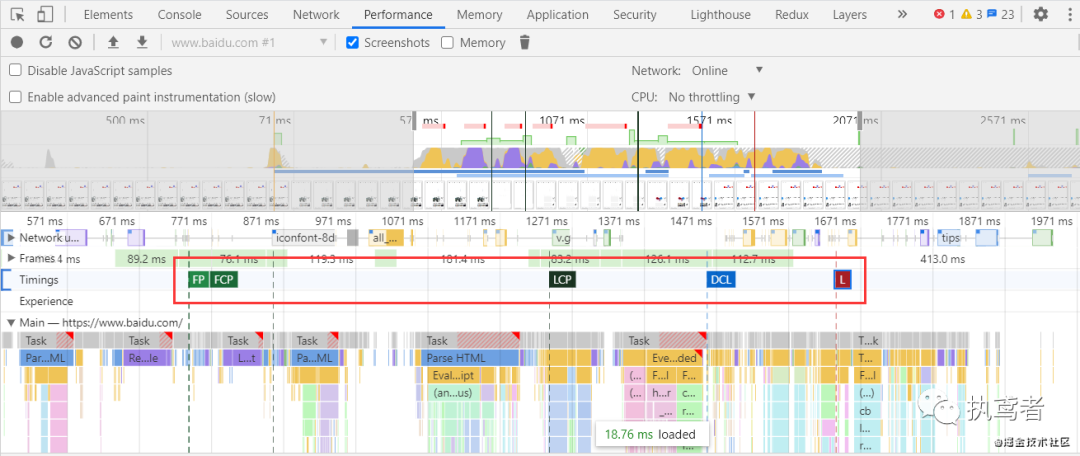
页面展示层面的指标是针对用户体验提出的几个指标,包含FP、FCP、LCP、FMP、DCL、L等,这几个指标其实就是chrome浏览器中performance模块的指标(如图所示)。
各个指标的解释如下表所示。

指标求解
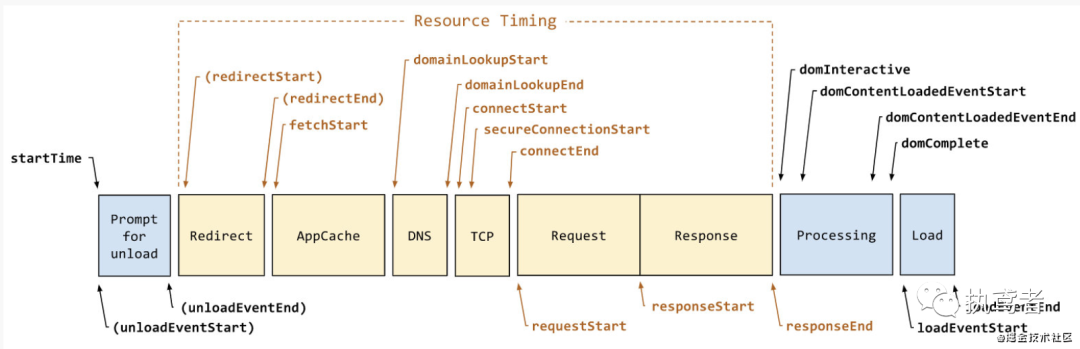
上述这么多指标该怎么获取呢?浏览器给我们留了相应的接口——神奇的window.performance,通过该接口可以获取一些列与性能相关的参数,下面以https://baidu.com 为例来看一下与这些指标相关的参数:

window.performance中的timing属性中的内容不就是为了求解上述指标所需要的值吗?看着上面的属性值再对应下面的performance访问流程图,整个过程是不是一目了然。
有了上面的值我们就一起求解上述的指标:
网络层面

页面展示层面
Google工程师一直在推动以用户为中心的性能指标,所以页面展示层面的变化较大,求解方式稍有不同:
FP和FCP
通过window.performance.getEntriesByType(‘paint’)的方式获取。
const paint = window.performance.getEntriesByType('paint');
const FP = paint[0].startTime,
const FCP = paint[1].startTime,- 1.
- 2.
- 3.
LCP
function getLCP() {
// 增加一个性能条目的观察者
new PerformanceObserver((entryList, observer) => {
let entries = entryList.getEntries();
const lastEntry = entries[entries.length - 1];
observer.disconnect();
console.log('LCP', lastEntry.renderTime || lastEntry.loadTime);
}).observe({entryTypes: ['largest-contentful-paint']});
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
FMP
function getFMP() {
let FMP;
new PerformanceObserver((entryList, observer) => {
let entries = entryList.getEntries();
observer.disconnect();
console.log('FMP', entries);
}).observe({entryTypes: ['element']});
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
DCL
domContentLoadEventEnd – fetchStart- 1.
L
loadEventStart – fetchStart- 1.
TTI
domInteractive – fetchStart- 1.
FID
function getFID() {
new PerformanceObserver((entryList, observer) => {
let firstInput = entryList.getEntries()[0];
if (firstInput) {
const FID = firstInput.processingStart - firstInput.startTime;
console.log('FID', FID);
}
observer.disconnect();
}).observe({type: 'first-input', buffered: true});
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
异常信息
对于网站来说,异常信息是最致命、最影响用户体验的问题,需要重点监控。对于异常信息可以分为两类:运行时错误、接口错误。下面就分别来唠一唠这两类错误。
运行时错误
当JavaScript运行时有可能会发生错误,可归类为七种:语法错误、类型错误、范围错误、引用错误、eval错误、URL错误、资源加载错误。为了捕获代码错误,需要考虑两类场景:非Promise场景和Promise场景,因为两种场景捕获错误的策略不同。
非Promise场景
非Promise场景可通过监听error事件来捕获错误。对于error事件捕获的错误分为两类:资源错误和代码错误。资源错误指的就是js、css、img等未加载,该错误只能在捕获阶段获取到,且为资源错误时event.target.localName存在值(用此区分资源错误与代码错误);代码错误指的就是语法错误、类型错误等这一类错误,可以获取代码错误的信息、堆栈等,用于排查错误。
export function listenerError() {
window.addEventListener('error', (event) => {
if (event.target.localName) {
console.log('这是资源错误', event);
}
else {
console.log('这是代码错误', event);
}
}, true)
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
Promise场景
Promise场景的处理方式有所不同,当Promise被reject且没有reject处理器的时候,会触发unhandlerejection事件,所以通过监听unhandlerejection的事件来捕获错误。
export function listenerPromiseError() {
window.addEventListener('unhandledrejection', (event) => {
console.log('这是Promise场景中错误', event);
})
}- 1.
- 2.
- 3.
- 4.
- 5.
接口错误
对于浏览器来说,所有的接口均是基于XHR和Fetch实现的,为了捕获接口中的错误,可以通过重写该方法,然后通过接口返回的信息来判断当前接口的状况,下面以XHR为例来展示封装过程。
function newXHR() {
const XMLHttpRequest = window.XMLHttpRequest;
const oldXHROpen = XMLHttpRequest.prototype.open;
XMLHttpRequest.prototype.open = (method, url, async) => {
// 做一些自己的数据上报操作
return oldXHROpen.apply(this, arguments);
}
const oldXHRSend = XMLHttpRequest.prototype.send;
XMLHttpRequest.prototype.send = (body) => {
// 做一些自己的数据上报操作
return oldXHRSend.apply(this, arguments);
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
业务信息
每个产品都会有自己的业务信息,例如用户在线时长、pv、uv、用户分布等,通过获取这些业务信息才能更加清楚的了解目前产品的状况,以便产品经理更好的去规划产品的未来方向。由于每个产品业务信息多种多样,小伙伴本可以按照自己的需求进行撰写代码,此处我就不再赘述。
上报
对于上报的方式无外乎两种:一种是Ajax的方式上报;另一种是通过Image的形式进行上报。目前很多大厂采用的上报方式均是通过一个1*1像素的的gif图片进行上报,既然人家都采用该种策略,那我们就来唠一唠下面两个问题。
为什么采用Image的方式上报?
- 没有跨域问题。因为数据服务器和后端服务器大概率是不同的域名,若采用Ajax的方式进行处理还要处理跨域问题,否则数据会被浏览器拦截。
- 不会阻塞页面加载,只需new Image对象即可。
图片类型很多,为什么采用gif这种格式进行上报?
其实归结为一个字——小。对于1*1px的图片,BMP结构的文件需要74字节,PNG结构的文件需要67字节,GIF结构的文件只需要43字节。同样的响应,GIF可以比BMP节约41%的流量,比PNG节约35%的流量,所以选择gif进行上报。
分析
日志上报之后需要进行清洗,获取自己所需要内容,并将分析内容进行存储。根据数据量的大小可分为两种方式:单机和集群。
单机
访问量小、日志少的网站可以采用单机的方式对数据进行分析,例如用node读取日志文件,然后通过日志文件中获取所需要的信息,最终将处理的信息存储到数据库中。
集群
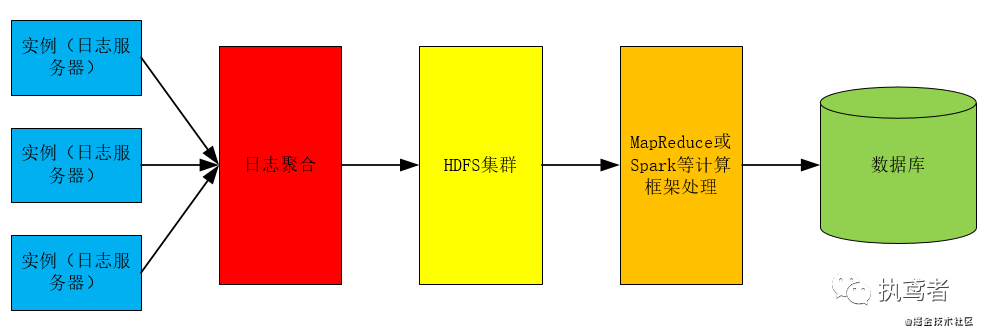
很多产品的访问量很大,日志很多,此时就需要利用Hadoop进行分布式处理,获取最终处理结果,其处理流程图如下所示:
根据自己的日志量级决定自己的分析方式,合适的就是最好的,不用一味追求最优的、最先进的处理方式。
报警
当异常类型超多一定阈值之后需要进行报警通知,让对应的工作人员去处理问题,及时止损。根据报警的级别不同,可以选择不同的报警方式。
- 邮件——普通报警。
- 短信——严重报警,已影响部分业务。
- 电话——特别严重,例如系统已宕机。