












数据处理和分析是基础和普遍的。算法在数据处理和分析中发挥着至关重要的作用,许多算法设计都结合了启发式和人类知识和经验的一般规则,以提高其有效性。
近年来,强化学习,特别是深度强化学习(DRL)在许多领域得到了越来越多的探索和利用,因为与静态设计的算法相比,它可以在复杂的交互环境中学习更好的策略。受这一趋势的推动,我们对最近的工作进行了全面的回顾,重点是利用DRL改进数据处理和分析。
首先,我们介绍了DRL中的关键概念、理论和方法。接下来,我们将讨论DRL在数据库系统上的部署,在各个方面促进数据处理和分析,包括数据组织、调度、调优和索引。
然后,我们调查了DRL在数据处理和分析中的应用,从数据准备、自然语言处理到医疗保健、金融科技等。
最后,我们讨论了在数据处理和分析中使用DRL所面临的重要挑战和未来的研究方向。

论文链接:https://arxiv.org/abs/2108.04526
在大数据时代,数据处理和分析是基础的、无处不在的,对于许多组织来说是至关重要的,这些组织正在进行数字化之旅,以改善和转变其业务和运营。在提取洞察力之前,数据分析通常需要其他关键操作,如数据采集、数据清理、数据集成、建模等。
大数据可以在医疗保健和零售等许多行业释放出巨大的价值创造。然而,数据的复杂性(例如,高容量、高速度和高多样性)给数据分析带来了许多挑战,因此很难得出有意义的见解。为了应对这一挑战,促进数据处理和分析的高效和有效,研究人员和实践人员设计了大量的算法和技术,也开发了大量的学习系统,如Spark MLlib和Rafiki。
为了支持快速的数据处理和准确的数据分析,大量的算法依赖于基于人类知识和经验开发的规则。例如,「最短作业优先」是一种调度算法,它选择执行时间最短的作业进行下一次执行。但在没有充分利用工作负载特性的情况下,与基于学习的调度算法相比,其性能较差。另一个例子是计算机网络中的包分类,它将一个包与一组规则中的一条规则进行匹配。一种解决方案是使用手工调整的启发式分类来构造决策树。具体来说,启发式算法是为一组特定的规则设计的,因此可能不能很好地工作于具有不同特征的其他工作负载。
我们观察到现有算法的三个局限性:
首先,算法是次优的。诸如数据分布之类的有用信息可能会被忽略或未被规则充分利用。其次,算法缺乏自适应能力。为特定工作负载设计的算法不能在另一个不同的工作负载中很好地执行。第三,算法设计是一个耗时的过程。开发人员必须花很多时间尝试很多规则,以找到一个经验有效的规则。
基于学习的算法也被用于数据处理和分析。经常使用的学习方法有两种:监督学习和强化学习。它们通过直接优化性能目标来实现更好的性能。监督学习通常需要一组丰富的高质量标注训练数据,这可能是很难和具有挑战性的获取。例如,配置调优对于优化数据库管理系统(DBMS)的整体性能非常重要。在离散和连续的空间中,可能有数百个调谐旋钮相互关联。此外,不同的数据库实例、查询工作负载和硬件特性使得数据收集变得不可用,尤其是在云环境中。
与监督学习相比,强化学习具有较好的性能,因为它采用了试错搜索,并且需要更少的训练样本来找到云数据库的良好配置。
另一个具体的例子是查询处理中的查询优化。数据库系统优化器的任务是为查询找到最佳的执行计划,以降低查询成本。传统的优化器通常枚举许多候选计划,并使用成本模型来找到成本最小的计划。优化过程可能是缓慢且不准确的。
在不依赖于不准确的成本模型的情况下,深度强化学习(DRL)方法通过与数据库交互来改进执行计划(例如,更改表连接顺序)。
当查询发送给agent(即DRL优化器)时,代理通过对基本信息(如访问的关系和表)进行特征化,生成状态向量。agent以状态为输入,利用神经网络生成一个动作集的概率分布,动作集可以包含所有可能的作为潜在动作的join操作。
每个操作表示一对表上的部分连接计划,一旦执行操作,状态将被更新。在采取可能的行动之后,生成一个完整的计划,然后由DBMS执行该计划以获得奖励。
在这个查询优化问题中,奖励可以根据实际延迟计算。在有奖励信号的训练过程中,agent可以改进策略,产生更高奖励的更好的连接排序(即延迟更少)。
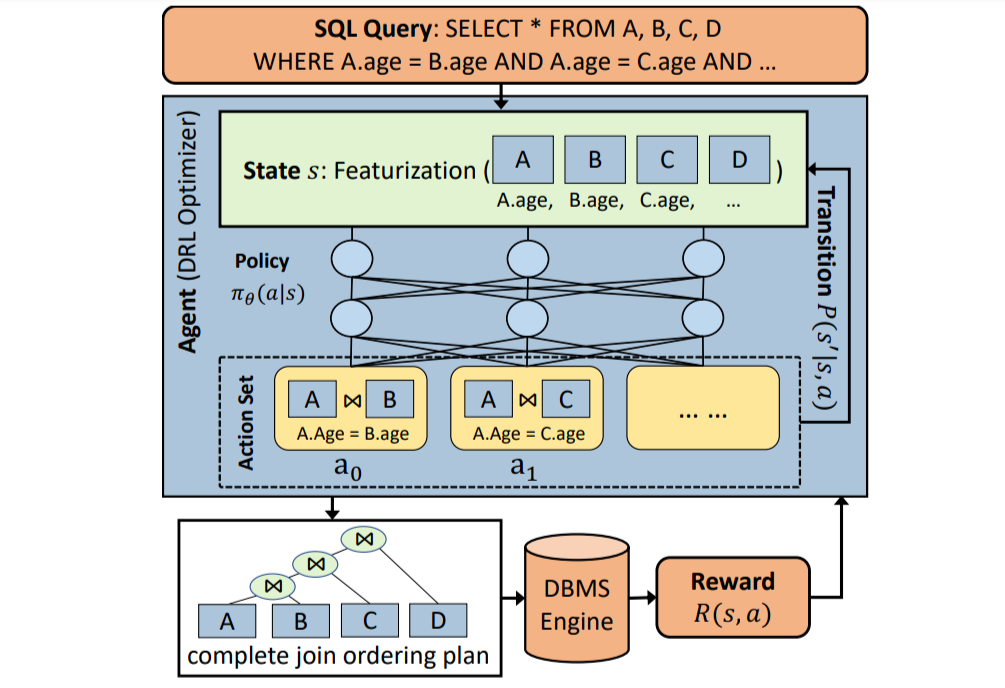
查询优化的DRL工作流程
强化学习(RL)专注于学习在环境中做出智能的行动。RL算法在探索和开发的基础上,通过环境反馈来改进自身。在过去的几十年里,RL在理论和技术方面都取得了巨大的进步。
值得注意的是,DRL结合了深度学习(DL)技术来处理复杂的非结构化数据,并被设计用于从历史数据中学习和自我探索,以解决众所周知的困难和大规模问题(如AlphaGo)。
近年来,来自不同社区的研究人员提出了DRL解决方案,以解决数据处理和分析中的问题。我们将现有的使用DRL的作品从系统和应用两个角度进行分类。
从系统的角度来看,我们专注于基础研究课题,从一般的,如调度,到系统特定的,如数据库的查询优化。我们还应当强调它是如何制定的马尔可夫决策过程,并讨论如何更有效地解决DRL问题与传统方法相比。由于实际系统中的工作负载执行和数据采集时间比较长,因此采用了采样、仿真等技术来提高DRL训练效率。
从应用的角度来看,我们将涵盖数据处理和数据分析中的各种关键应用,以提供对DRL的可用性和适应性的全面理解。许多领域通过采用DRL进行转换,这有助于学习有关应用的领域特定知识。
在这次综述中,我们的目标是提供一个广泛和系统的回顾,在解决数据系统、数据处理和分析问题中使用DRL的最新进展。
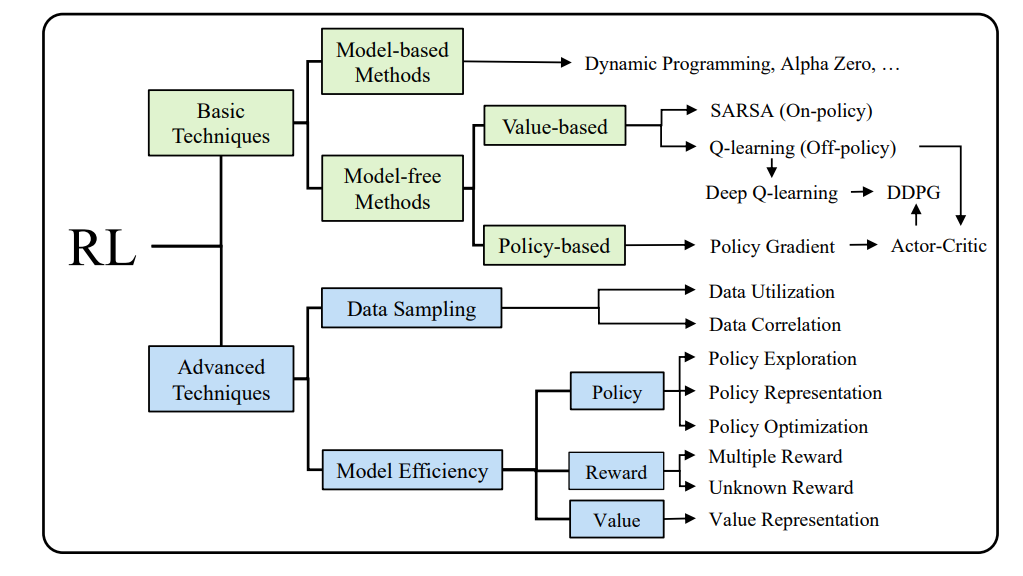
RL技术分类
























