













本文经AI新媒体量子位(公众号ID:QbitAI)授权转载,转载请联系出处。
扩散模型最近是真的有点火。
前有OpenAI用它打败霸榜多年的GAN,现在谷歌又紧随其后,提出了一个视频扩散模型。
和图像生成一样,初次尝试,它居然就表现出了不俗的性能。
比如输入“fireworks”,就能生成这样的效果:

满屏烟花盛放,肉眼看上去简直可以说是以假乱真了。
为了让生成视频更长、分辨率更高,作者还在这个扩散模型中引入了一种全新的采样方法。
最终,该模型在无条件视频生成任务中达到全新SOTA。
一起来看。
由图像扩散模型扩展而成
这个扩散视频模型,由标准的图像扩散模型UNet扩展而成。
UNet是一种神经网络架构,分为空间下采样通道和上采样通道,通过残差连接。
该网络由多层2D卷积残差块构建而成,每个卷积块后面跟着一个空间注意块。
通过固定帧数的块,以及在空间和时间上分解的3D U-Net,就可以将它扩展为视频模型。
具体来说:
先将每个二维卷积更改为三维卷积(space-only),比如将3x3卷积更改为1x3x3卷积(第一轴(axis)索引视频帧,第二轴和第三轴索引空间高度和宽度)。
每个空间注意块中的注意力仍然专注于空间维度。
然后,在每个空间注意块之后,插入一个时间注意块;该时间注意块在第一个轴上执行注意力,并将空间轴视为批处理轴(batch axes)。
众所周知,像这样在视频Transformer中分对时空注意力进行分解,会让计算效率更高。
由此一来,也就能在视频和图像上对模型进行联合训练,而这种联合训练对提高样本质量很有帮助。
此外,为了生成更长和更高分辨率的视频,作者还引入了一种新的调整技术:梯度法。
它主要修改模型的采样过程,使用基于梯度的优化来改善去噪数据的条件损失,将模型自回归扩展到更多的时间步(timestep)和更高的分辨率。
评估无条件和文本条件下的生成效果
对于无条件视频生成,训练和评估在现有基准上进行。
该模型最终获得了最高的FID分数和IS分数,大大超越了此前的SOTA模型。
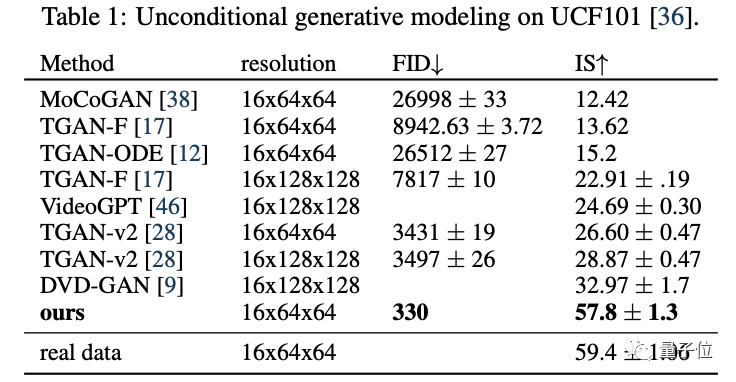
对于文本条件下的视频生成,作者在1000万个字幕视频的数据集上进行了训练,空间分辨率为64x64px;
在此之前,视频生成模型采用的都是各种GAN、VAE,以及基于流的模型以及自回归模型。
所以这也是他们首次报告扩散模型根据文本生成视频的结果。

下图则显示了无分类器引导对该模型生成质量的影响:与其他非扩散模型一致,添加引导会增加每个单独图像的保真度(右为该视频扩散模型,可以看到它的图片更加真实和清晰)。

△ 图片为随机截取的视频帧
最后,作者也验证发现,他们所提出的梯度法在生成长视频时,确实比此前的方法更具多样性,也就更能保证生成的样本与文本达成一致。

△ 右为梯度法
论文地址:https://arxiv.org/abs/2204.03458
项目主页:https://video-diffusion.github.io/



























