













人工智能(AI)基准为模型提供了衡量和比较的路径,超越基准,达到SOTA,经常成为顶会论文的标配。同时,有些基准确实推动了AI的发展,例如ImageNet 基准测试对近几年的热潮功不可没。
如今,ImageNet 基准仍然在研究中发挥核心作用,一些新模型,例如谷歌的Vision Transformer在论文中仍然与ImageNet方法进行比较。
但,如果某一基准的分数一直占据榜首,后续没有高质量基准引入,那么这种依靠基准推动发展的“路子”就有问题。

近日,维也纳医科大学和牛津大学的研究人员对AI基准图谱进行了调查,共统计了2013年以来CV和NLP领域的406项任务的1688项基准。发现:很大一部分基准迅速趋于接近饱和,还有一部分基准被搁置;同时,在NLP领域,从2020年开始,新基准的建立减少,方向转向推理或推理相关的高级任务上。
在文中,作者呼吁,未来的工作应该着重于大规模的社区合作,以及将基准性能与现实世界效用和影响相联系。
1.33%的AI基准被“搁置”
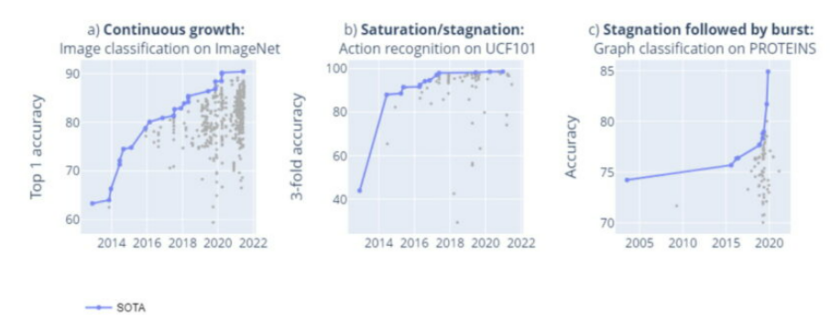
从单个基准出发,如上图可以看出基准上的SOTA有三种状态:稳定增长,停滞或饱和,以及停滞后的飞跃。其中,稳定增长代表技术稳定;停滞背后代表缺乏技术进步的能力;而爆发是指技术出现突破。
事实上,近年来,关键领域,如NLP,有相当一部分新基准迅速趋于饱和,或者设计针对特定基准特征过度优化的模型,而这些模型往往无法泛化到其他数据中。
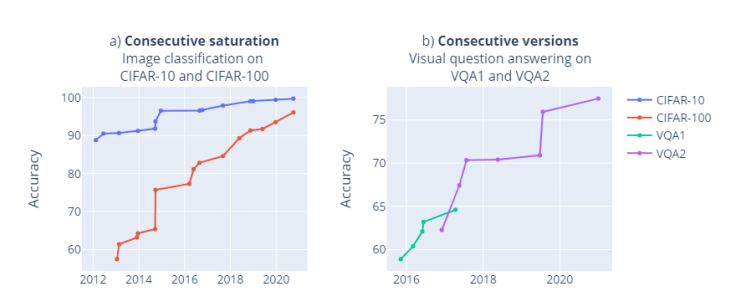
目前,这些现象已经蔓延到相同领域的不同基准中,例如上图,CIFAR-10和CIFAR-100的状态。
同时,数量方面也出现了尴尬的局面,例如《2021年的人工智能指数报告》指出,CV基准数量或许能满足日益增长的任务需求;而NLP模型的增长速度正在超过现有的问答和自然语言理解基准。
Martínez-Plumed等学者分析了 CIFAR-100 和 SQuAD1.1 等 25 个流行 AI 基准背后“故事”,他们发现“SOTA 前沿”由某些长期协作的社区主导,例如美国或亚洲大学与科技公司共同合作的组织。
此外,其他学者分析了大量 AI 基准测试工作中数据集使用和再利用的趋势,他们发现,很大一部分“知名”数据集是由少数高知名度的组织提出,其中一些数据集被越来越多地重新用于新的任务。NLP是个例外,它对新的、特定任务的基准的引入和使用超过了平均水平。
在这项研究中,维也纳医科大学和牛津大学的研究人员表明:饱和和搁置非常常见。总体看来有以下几个趋势:
1.缺乏研究兴趣是导致停滞不前的原因之一;
2.所有基准中的大多数很快就会达到技术停滞或饱和;
3.在某些情况下,会出现持续增长,例如在 ImageNet 基准测试中;
4.性能改进的动态变化并不遵循一个清晰可辨的模式:在某些情况下,停滞阶段之后是不可预测的飞跃。
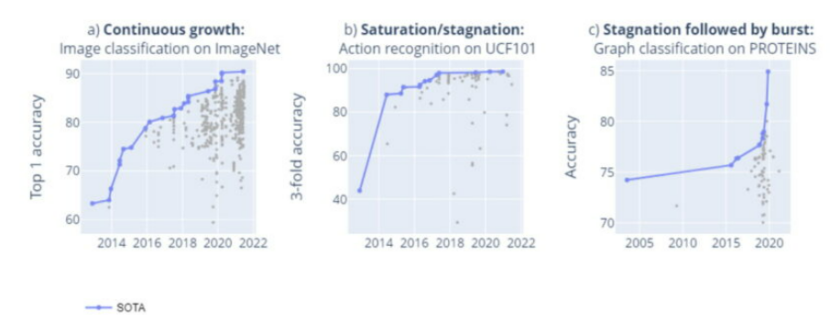
图注:基准有三种发展趋势:稳定增长,停滞或饱和,以及停滞后的飞跃。
此外,在1688个基准中,只有66%的基准充分被利用,换言之33%的基准被搁置。同时,基准测试的另一个趋势是:被某些既定机构和公司的数据集主导。
2.NLP基准正面向高难度的任务
过去几年,CV领域的基准占据主导地位,但NLP也开始了蓬勃发展。2020年,新基准的数量有所下降,越来越多地集中在难度较高的任务上,例如测试推理的任务,例如BIG-bench和NetHack,前者属于谷歌,后者来自Facebook。
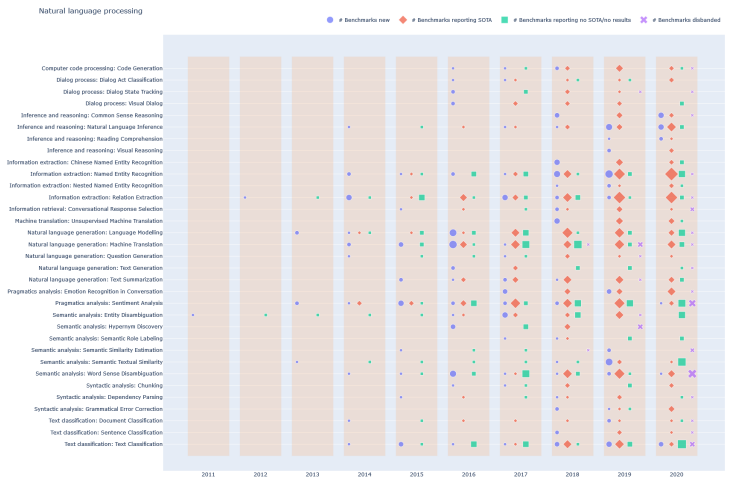
上图是NLP的基准生命周期展示,可以清晰看出,大多数任务的几个主流基准是在2011~2015年间建立的,这期间,也只有少数几个SOTA出现。2016年之后,新基准的建立速度大大加快,在翻译和自然语言建模方面表现最为突出;2018和2019年,分别都针对各种任务建立了大量的基准;2020年是个转折点,新基准的建立减少,方向转向推理或推理相关的高级任务上。
整体来说,当前AI基准的趋势是:来自既定机构(包括工业界)的基准的趋势引起了人们对基准的偏见和代表性的关注;许多基准并不能完全将AI性能与现实世界相匹配,因此,开发少量但有质量保证,涵盖多种AI能力、场景的基准可能是可取的。
最后,研究人员展望,在未来,新的基准应该由来自许多机构、知识领域的大型合作团队开发,如此才能确保建立高质量的基准。

























