当前 Vision Transformers (ViT)领域有两个主要的痛点:1、缺少对 ViT 进行设计和扩展的有效方法;2、训练 ViT 的计算成本比卷积网络要大得多。
为了解决这两个问题,来自得克萨斯大学奥斯汀分校、悉尼科技大学和谷歌的研究者提出了 As-ViT(Auto-scaling Vision Transformers),这是一个无需训练的 ViT 自动扩展框架,它能以高效且有原则的方式自动设计和扩展 ViT。

论文链接:https://arxiv.org/abs/2202.11921
具体来说,研究人员首先利用无训练搜索过程设计了 ViT 拓扑的「种子」,这种极快的搜索是通过对 ViT 网络复杂性的全面研究来实现的,从而产生了与真实准确度的强 Kendall-tau 相关性。其次,从「种子」拓扑开始,通过将宽度 / 深度增加到不同的 ViT 层来自动化 ViT 的扩展规则,实现了在一次运行中具有不同数量参数的一系列架构。最后,基于 ViT 在早期训练阶段可以容忍粗粒度 tokenization 的经验,该研究提出了一种渐进式 tokenization 策略来更快、更节约地训练 ViT。
作为统一的框架,As-ViT 在分类(ImageNet-1k 上 83.5% 的 top1)和检测(COCO 上 52.7% 的 mAP)任务上实现了强大的性能,无需任何手动调整或扩展 ViT 架构,端到端模型设计和扩展过程在一块 V100 GPU 上只需 12 小时。
具有网络复杂度的 ViT 自动设计和扩展
为加快 ViT 设计并避免繁琐的手动工作,该研究希望以高效、自动化和有原则的 ViT 搜索和扩展为目标。具体来说有两个问题需要解决:1)在训练成本最小甚至为零的情况下,如何高效地找到最优的 ViT 架构拓扑?2)如何扩大 ViT 拓扑的深度和宽度以满足模型尺寸的不同需求?
扩展 ViT 的拓扑空间
在设计和扩展之前,首先是为 As-ViT 扩展的拓扑搜索空间:首先将输入图像嵌入到 1/4 尺度分辨率的块中,并采用逐级空间缩减和通道加倍策略。这是为了方便密集预测任务,例如需要多尺度特征的检测。
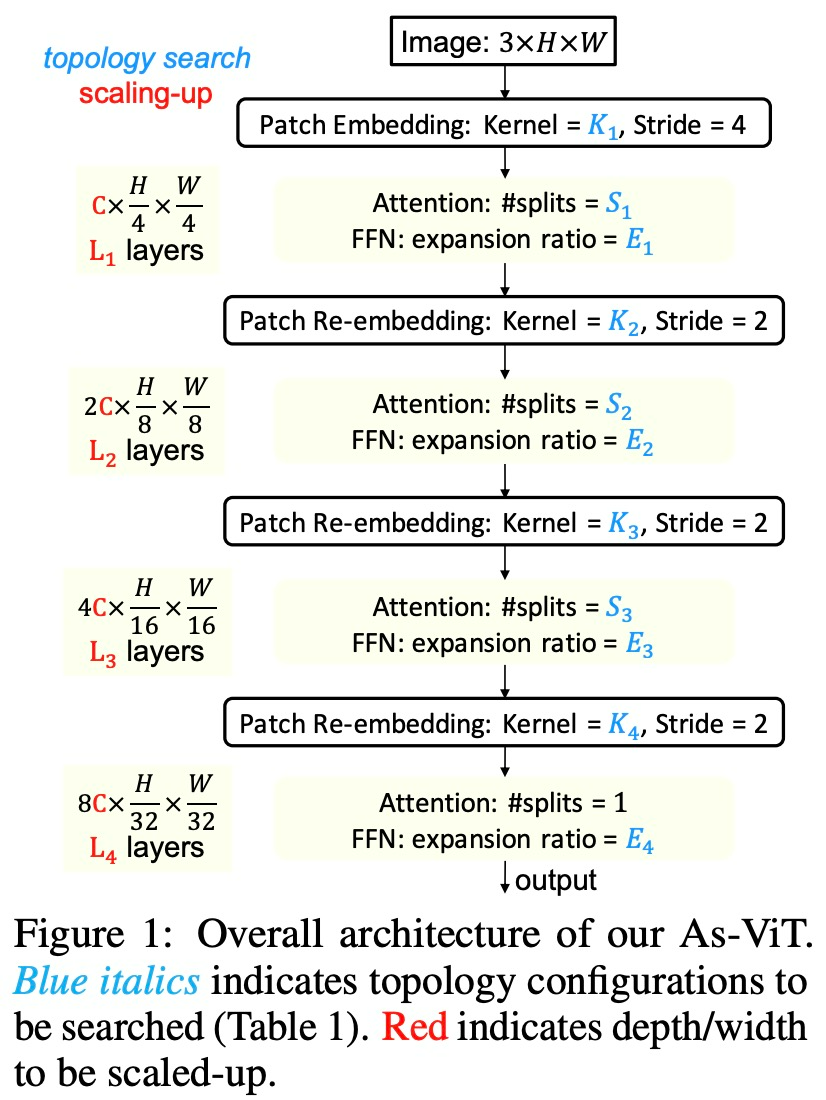
通过流形传播评估初始化时的 ViT 复杂性
ViT 训练速度很慢,因此,通过评估训练模型的准确率来进行架构搜索的成本将高得让人难以承受。最近学界出现很多用基于 ReLU 的 CNN 的免训练神经架构搜索方法,利用局部线性图 (Mellor et al., 2020)、梯度敏感性 (Abdelfattah et al., 2021)、线性区域数量 (Chen et al., 2021e;f) 或网络拓扑(Bhardwaj et al., 2021)等方式。
然而 ViT 配备了更复杂的非线性函数如 self-attention、softmax 和 GeLU。因此需要以更一般的方式衡量其学习能力。在新研究中,研究者考虑通过 ViT 测量流形传播的复杂性,以估计复杂函数可以如何被 ViT 逼近。直观地说,一个复杂的网络可以在其输出层将一个简单的输入传播到一个复杂的流形中,因此可能具有很强的学习能力。在 UT Austin 的工作中,他们通过 ViT 映射简单圆输入的多种复杂性:h(θ) = √ N [u^0 cos(θ) + u^1 sin(θ)]。这里,N 是 ViT 输入的维度(例如,对于 ImageNet 图像,N = 3 × 224 × 224),u^0 和 u^1 形成了圆所在的 R^N 的二维子空间的标准正交基。
搜索 ViT 拓扑奖励
研究者提出了基于 L^E 的免训练搜索(算法 1),大多数 NAS(神经架构搜索)方法将单路径或超级网络的准确率或损失值评估为代理推理。当应用于 ViT 时,这种基于训练的搜索将需要更多的计算成本。对于采样的每个架构,这里不是训练 ViT,而是计算 L^E 并将其视为指导搜索过程的奖励。
除了 L^E,还包括 NTK 条件数 κΘ = λ_max/λ_min ,以指示 ViT 的可训练性(Chen et al., 2021e; Xiao et al., 2019; Yang, 2020; Hron et al., 2020)。λ_max 和 λ_min 是 NTK 矩阵 Θ 的最大和最小特征值。

搜索使用强化学习方法,策略被定为联合分类分布,并通过策略梯度进行更新,该研究将策略更新为 500 step,观察到足以使策略收敛(熵从 15.3 下降到 5.7)。搜索过程非常快:在 ImageNet-1k 数据集上只有七个 GPU 小时 (V100),这要归功于绕过 ViT 训练的 L^E 的简单计算。为了解决 L^E 和 κΘ 的不同大小,该研究通过它们的相对值范围对它们进行归一化(算法 1 中的第 5 行)。
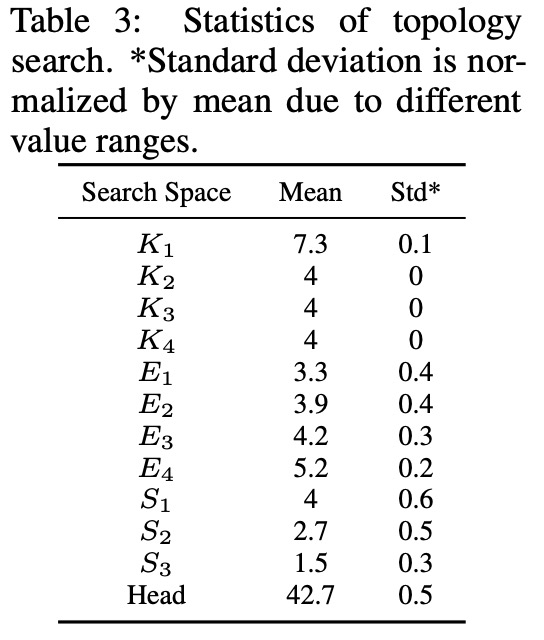
表 3 总结了新搜索方法的 ViT 拓扑统计数据。我们可以看到 L^E 和 κΘ 高度偏好:(1)具有重叠的 token (K_1∼K_4 都大于 stride ),以及(2)在更深层中更大的 FFN 扩展率(E_1 < E_2 < E_3 < E_4)。在注意力分裂和正面数量上没有发现 L^E 和 κΘ 的明显偏好。
ViT 自主的原则型扩展
得到最优拓扑后,接下来要解决的一个问题是:如何平衡网络的深度和宽度?
目前,对于 ViT 扩展没有这样的经验法则。最近的工作试图扩大或增长不同大小的卷积网络以满足各种资源限制(Liu et al., 2019a; Tan & Le, 2019)。然而,为了自动找到一个有原则的扩展规则,训练 ViT 将花费巨大的计算成本。也可以搜索不同的 ViT 变体(如第 3.3 节中所述),但这需要多次运行。相反,「向上扩展,scaling-up」是在一个实验中生成多个模型变体的更自然的方式。因此,该研究试图以一种免训练且有原则的有效方法将搜索到的基本「种子」ViT 扩展到更大的模型。算法 2 中描述了这种自动扩展方法:

初始架构的每个阶段都有一个注意力块,初始隐藏维度 C = 32。每次迭代找出最佳深度和宽度,以进行进一步向上扩展。对于深度,该研究尝试找出要加深哪个阶段(即,在哪个阶段添加一个注意力块);对于宽度,该研究尝试发现最佳扩展比(即,将通道数扩大到什么程度)。

扩展轨迹如下图 3 所示。比较自主扩展和随机扩展,研究者发现扩展原则更喜欢舍弃深度来换取更多宽度,使用更浅但更宽的网络。这种扩展更类似于 Zhai et al. (2021) 开发的规则。相比之下,ResNet 和 Swin Transformer (Liu et al., 2021) 选择更窄更深。

通过渐进灵活的 re-tokenization 进行高效的 ViT 训练
该研究通过提出渐进灵活的 re-tokenization 训练策略来提供肯定的答案。为了在训练期间更新 token 的数量而不影响线性投影中权重的形状,该研究在第一个线性投影层中采用不同的采样粒度。以第一个投影核 K_1 = 4 且 stride = 4 为例:训练时研究者逐渐将第一个投影核的 (stride, dilation) 对逐渐变为 (16, 5), (8, 2) 和 (4 , 1),保持权重的形状和架构不变。
这种 re-tokenization 的策略激发了 ViT 的课程学习(curriculum learning):训练开始时引入粗采样以显着减少 token 的数量。换句话说,As-ViT 在早期训练阶段以极低的计算成本(仅全分辨率训练的 13.2% FLOPs)快速从图像中学习粗略信息。在训练的后期阶段,该研究逐渐切换到细粒度采样,恢复完整的 token 分辨率,并保持有竞争力的准确率。如图 4 所示,当在早期训练阶段使用粗采样训练 ViT 时,它仍然可以获得很高的准确率,同时需要极低的计算成本。不同采样粒度之间的转换引入了性能的跳跃,最终网络恢复了具有竞争力的最终性能。
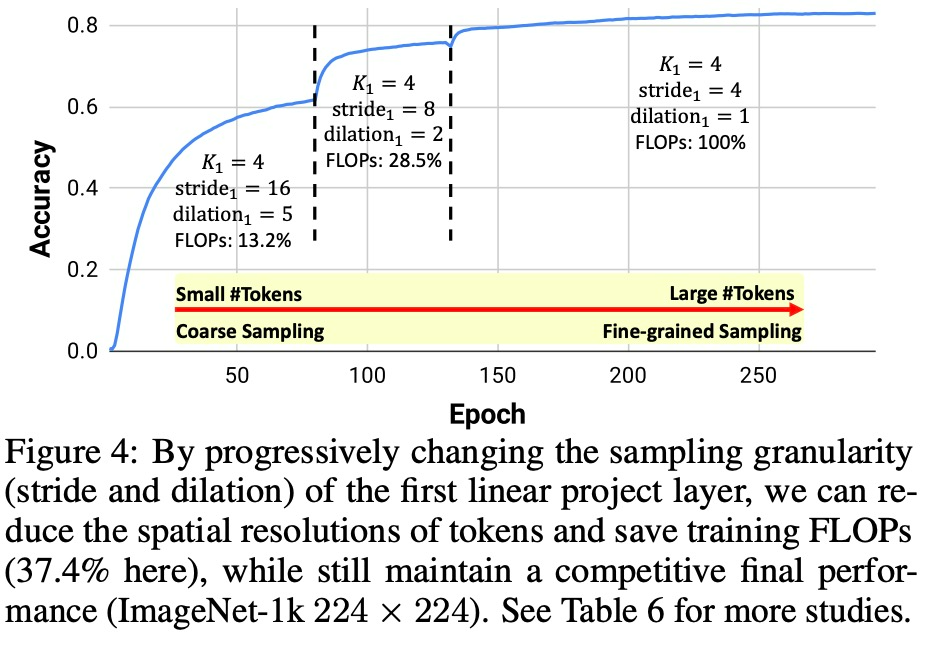
如图 4 所示,当 ViT 在早期训练阶段使用粗采样训练 ViT 时,它仍然可以获得很高的准确率,同时需要极低的计算成本。不同采样粒度之间的转换引入了性能的跳跃,最终网络恢复了具有竞争力的最终性能。
实验
AS-VIT:自动扩展 VIT
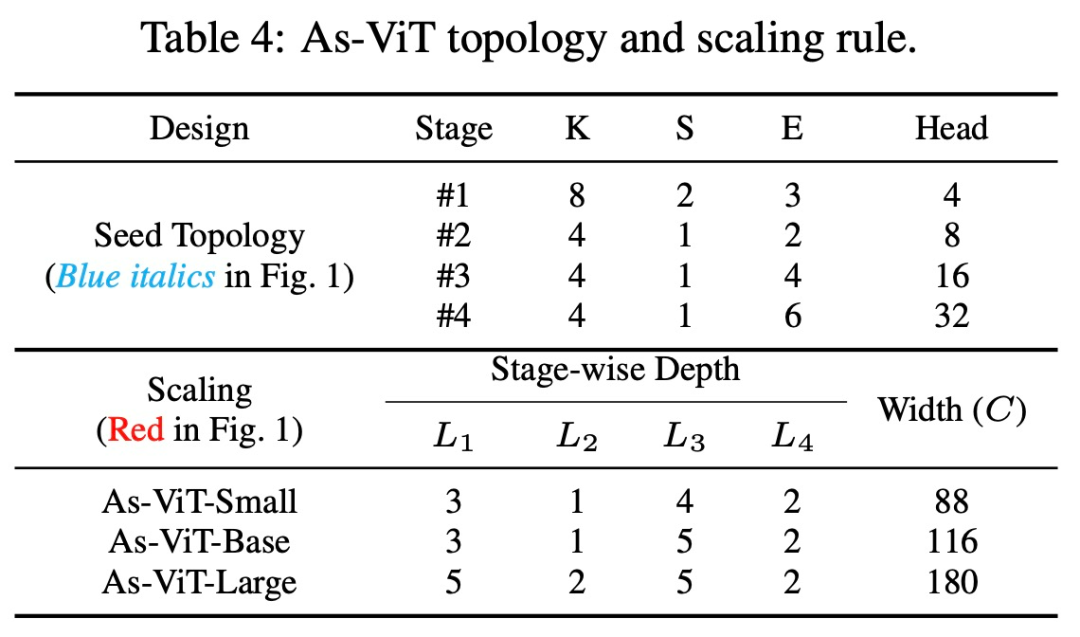
该研究在表 4 中展示了搜索到的 As-ViT 拓扑。这种架构在第一个投影(tokenization)step 和三个重新嵌入 step 中,促进了 token 之间的强烈重叠。FFN 扩展比首先变窄,然后在更深的层变宽。利用少量注意力拆分来更好地聚合全局信息。
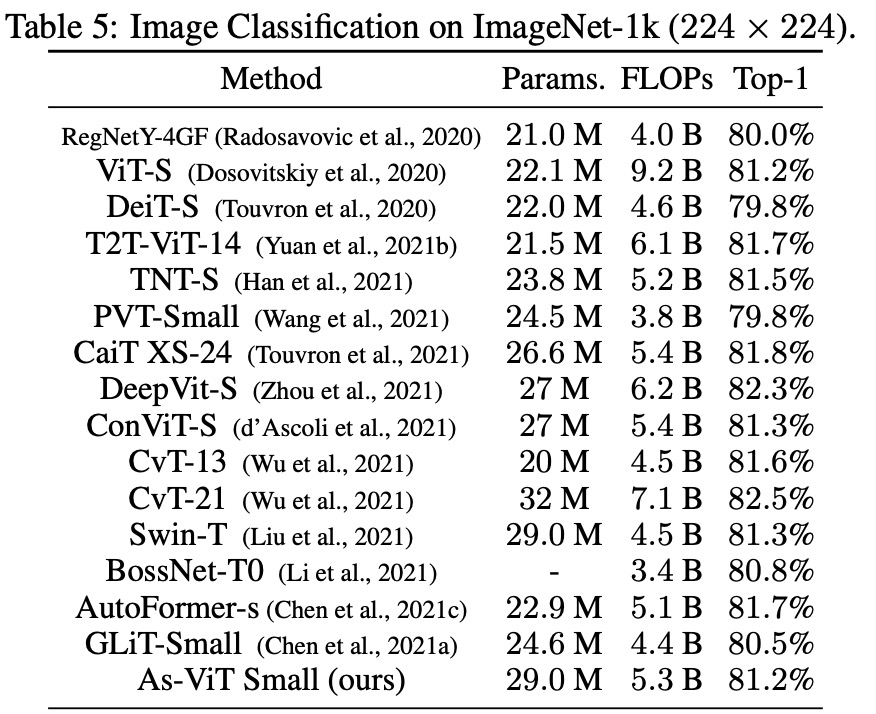
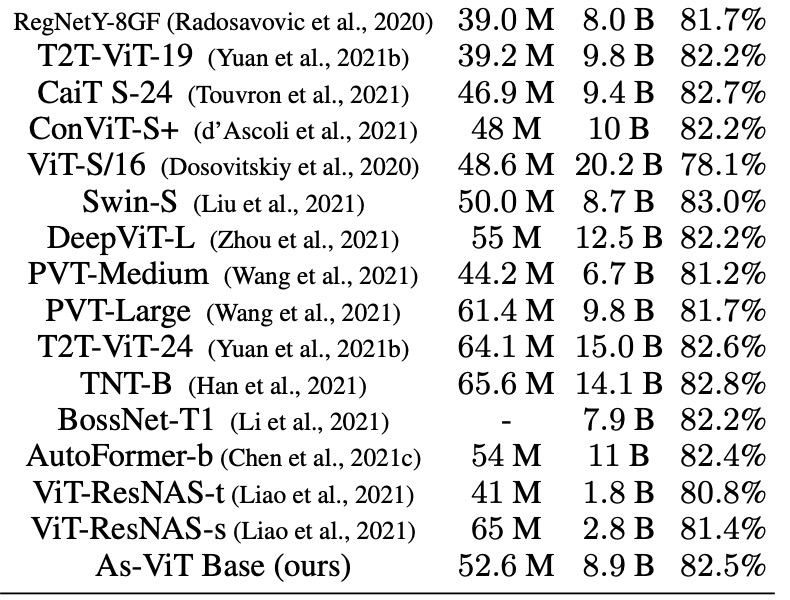
图像分类
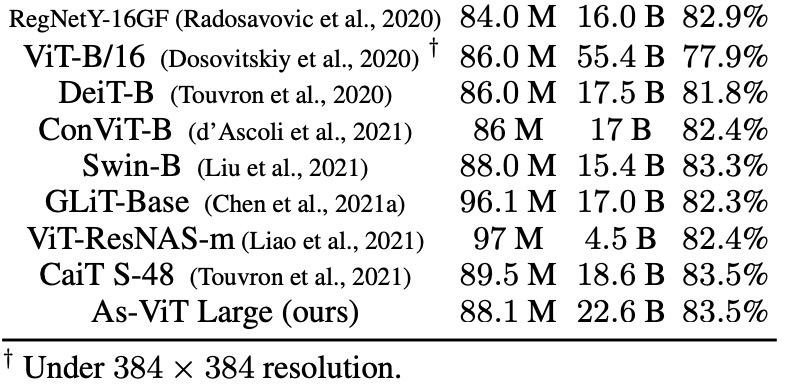
下表 5 展示了 As-ViT 与其他模型的比较。与之前基于 Transformer 和基于 CNN 的架构相比,As-ViT 以相当数量的参数和 FLOP 实现了 SOTA 性能。
高效训练
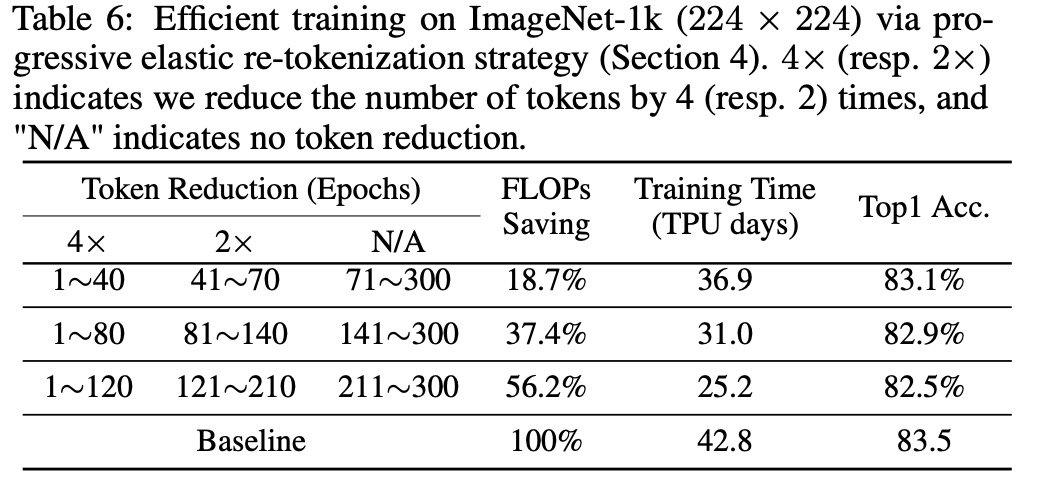
研究者调整了表 6 中为每个 token 减少阶段的时期,并将结果显示在表 6 中。标准训练需要 42.8 TPU 天,而高效训练可节省高达 56.2% 的训练 FLOP 和 41.1% 的训练 TPU 天,仍然达到很高的准确率。
拓扑和扩展的贡献
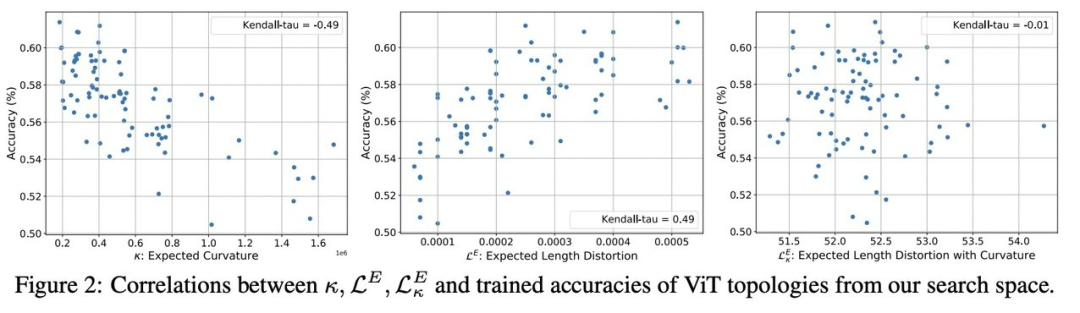
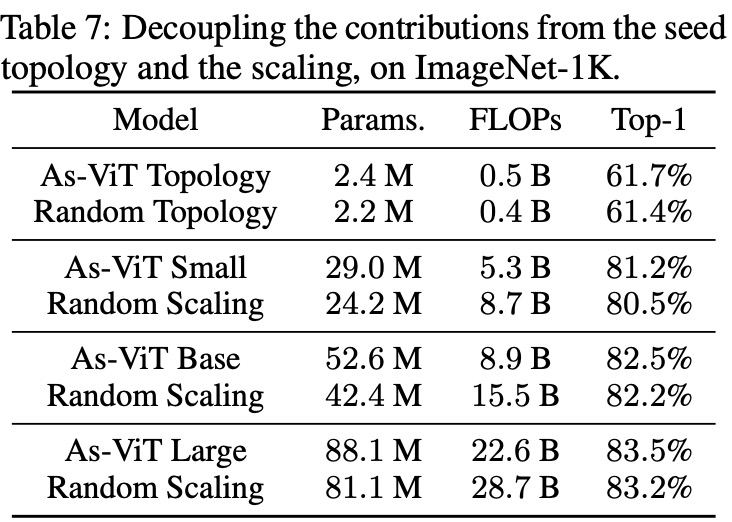
为了更好地验证搜索型拓扑和扩展规则的贡献,该研究进行了更多的消融研究(表 7)。首先,在扩展之前直接训练搜索到的拓扑。该研究搜索的种子拓扑优于图 2 中 87 个随机拓扑中的最佳拓扑。
第二,该研究将基于复杂度的规则与「随机扩展 + As-ViT 拓扑」进行比较。在不同的扩展下,该研究的自动扩展也优于随机扩展。
COCO 数据集上的目标检测
该研究将 As-ViT 与标准 CNN 和之前的 Transformer 网络进行了比较。比较是通过仅更改主干而其他设置未更改来进行的。从下表 8 的结果可以看出,As-ViT 也可以捕获多尺度特征并实现最先进的检测性能,尽管它是在 ImageNet 上设计的,并且它的复杂性是为分类而测量的。