在上一篇中主要讲了对于文本语料的提取和预处理的过程,接下来就要进入到核心步骤,即对于处理模型的掌握,处理模型这块的篇幅会很长,对于不同的模型,其优缺点各不相同,因此有必要对这一块进行一个全方面的掌握。
在深度学习技术还未应用到自然语言处理领域中之前,在自然语言处理领域中最通用的模型都是基于概率统计的。而其中最为核心的模型就是HMM(隐马尔可夫模型)。下面就让本篇文章为读者揭开HMM的面纱吧,提前说明,对于这一块模型的掌握需要具备一定的概率论的基础知识,对于这一块内容,本文不再作过多的赘述,因为大学本科的高数基本都包含了概率论这门课程。
1.概率模型
在掌握HMM模型之前,首先需要对概率模型进行一个掌握。概率模型,顾名思义,就是将学习任务归结到计算变量的概率分布的模型。针对于自然语言处理领域,即通过概率分布的形式来表达不同词汇之间的关联和区别。概率模型的提出是基于生活中一些观察到的现象来推测和估计未知的事务这一任务的,在概率模型中这种推测和估计也叫推断。推断的本质也就是利用已经有的或者可观测到的变量,来推测未知变量的条件分布。
1.1.生成模型和判别模型
目前概率模型又可以分为两类,即生成模型和判别模型。由上文可知,概率模型是通过可观测变量来推断未知变量分布,因此为了更好的掌握生成模型和判别模型之间的差异,可以将可观测的变量命名为X,而需要推断的未知的变量命名为Y。那么对于生成模型,其需要学习的是X和Y之间的联合概率分布P(X,Y),而判别模型学习的是条件概率分布P(Y|X)。而对于联合概率分布和条件概率分布已经是概率论的基础理论知识,在这不再赘叙了,望不了解的读者自行查阅。
对于这两种不同概率分布的模型,其各自模型的能力不同。例如,对于某一个给定的观测值X,运用条件概率分布P(Y|X),即可以很容易的得出未知Y的值(P(Y)=P(X)*P(Y|X))。因此对于分类问题,就可以直接运用判别模型,即观测对于给定的X,得到的Y的概率哪一个最大,就可以判别为哪一个类别。因此判别模型更适用于分类任务,其在分类任务上具备显著的优势。而对于生成模型,直接用该模型来做分类任务是比较困难的,除非将联合概率分布转化为条件概率分布,即将生成模型转化为判别模型去做分类任务。但是,生成模型主要并不是处理分类问题的,其有专门的用途,之后讲的HMM就是一种生成模型,在这先卖个小关子。
1.2.概率图模型
在掌握生成模型和判别模型的主要过程和任务之后,还需要对概率图模型有个基本的掌握。它是一种用图结构作为表示工具,来表达变量之间的关系的概率模型。这里的图与数据结构中图的结构是类似的,即由节点和连接节点的边组成。在概率图模型中,一般会用节点来表示某一随机变量,而节点之间的边则表示不同变量之间的概率关系。同时类比于数据结构,边也是分为有方向和无方向的,从而也就分为有向图模型(贝叶斯网络)和无向图模型(马尔可夫网)。虽然HMM的名字里有“马尔可夫”,但是HMM模型是贝叶斯网络的一种,在这里不要弄混淆了。
HMM是最为普遍的动态贝叶斯网络,即对变量序列建模的贝叶斯网络,属于有向图模型。为了后续HMM模型更好的理解,在这里先对马尔可夫链进行介绍,马尔可夫链是一个随机过程模型,该模型描述了一系列可能的事件,而这一系列中的每一个事件的概率仅仅依赖于前一个事件。如下图所示:

该图就是一个简单的马尔可夫链,图中的两个节点就分别表示晴天和下雨两个事件,图中节点之间的边就表示事件之间的转移概率。即:晴天以后,有0.9的概率还是晴天,0.1的概率会下雨;而雨天以后,有0.4的概率是晴天,0.6的概率还会继续下雨。因此这个模型对于今天天气的预测,只与昨天天气有关,与前天以及更早的天气无关。因此由马尔可夫链可知,只要知道前一天的天气,即可以推测今天的天气的可能性了。
2.HMM——隐马尔可夫模型
在掌握了概率模型的基础上,进一步去掌握HMM模型将会加深读者对HMM这一模型的理解。HMM属于概率模型的一种,即时序的概率模型。
2.1.序列模型
HMM是一个时序的概率模型,其中的变量分为状态变量和观测变量两组,各自都是一个时间序列,每个状态或者观测值都和一个时刻相对应,如下图所示(其中箭头表示依赖关系):
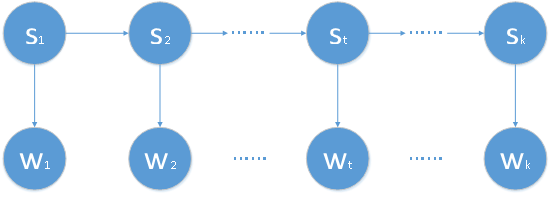
上图中,状态变量分别为 , …… ,观测变量分别为 , …… 。一般情况下,状态序列都是隐藏的,也就是不能被观测到的,所以状态变量是隐变量,即HMM中的Hidden的缘由。其中这个隐藏的、不可观测的状态序列就是由一个马尔可夫链随机生成的,即HMM中的第一个M即马尔可夫的含义。同时,一般的HMM的状态变量取值都是离散的,观测变量的取值可以是离散的,也可以是连续的。为了下文进行方便地阐述,仅讨论状态变量和观测变量都是离散的情况,并且这也是大多数应用中出现的情况。
2.2.基本假设
HMM模型是建立在两个基本假设之上的:
1. 假设隐藏的马尔可夫链在任意时刻t的状态只依赖于前一个时刻(t-1)的状态,而与其他时刻的状态和观测无关,这一假设也叫齐次马尔可夫假设,公式表示为:
P( …… )= P( ),t=1,2,……k
2. 假设任意时刻的观测只依赖于该时刻的马尔可夫链状态,而与其他观测和状态无关,这一假设也叫观测独立性假设,公式表示为:
P( …… …… )= P( )
2.3.HMM确定条件
确定一个HMM模型的条件为两个空间和三组参数,两个空间也就是上文提到的观测值和状态值空间,即观测空间W和状态空间S。确定这两个空间后,还需要三组参数,也就是三个概率矩阵。分别为:
- 初始状态概率:模型在初始时刻各个状态出现的概率,该概率矩阵即表示每个状态初始的概率值,通常定义为=(,……),其中就表示模型初始状态为的概率;
- 状态转移概率:即模型在不同状态之间切换的概率,通常将该概率矩阵定义为A=,矩阵中的就表示在任意时刻下,状态到下个时刻状态的概率;
- 输出观测概率:模型根据当前的状态来获得不同观测值的概率,通常将该概率矩阵定义为:B=,矩阵中的 就表示在任意时刻下,状态为时,观测值被获取的概率。(这个概率矩阵针对于有时候已知,而未知的情况)。
有了上述的状态空间S、观测空间O以及三组参数 =[A,B, ]后,一个HMM模型就可以被确定下来了。
2.4.HMM解决问题
确定好HMM模型后,就需要用该模型去解决一系列问题,其中主要包括概率计算问题、预测问题以及学习问题。
- 概率计算问题,即评价问题,对给定模型设置参数 后,给定观测序列,来求其与模型之间的匹配度。
- 预测问题,即解码问题,对给定模型设置参数 后,给定观测序列,求最有可能(概率值最大)与其对应的装填序列。
- 学习问题,即训练问题,给定观测序列及状态序列,来估计模型的参数,使得在该模型参数下,观测序列概率最大。即训练模型,来更好地用模型表示观测数据。
以上三个问题中,前两个问题都是已知模型参数(模型已经确定),如何使用该模型的问题,而第三个问题则是如何通过训练来得到模型参数(确定模型)的问题。
3.模型学习算法
HMM模型的学习算法可根据训练数据的不同,分为有监督学习和无监督学习两种。这两种学习方法在今后深度学习技术模型中也是应用最为广泛的。即对于模型来说,若训练数据既包括观测值(观测序列),又包括状态值(状态序列),并且两者之间的对应关系已经标注了(即训练之前确定了对应关系),那么采用的学习算法就是有监督学习。否则,对于只有观测序列而没有明确对应的状态序列,则使用的就是无监督学习算法进行训练。
3.1.有监督学习
在模型训练过程中,训练数据是由观测序列和对应的状态序列的样本对组成,即训练数据不仅包含观测序列,同时包含每个观测值对应的状态值,这些在训练前都是已知的。这样就可以频数来估计概率。首先通过统计训练数据中的状态值和观测值,分别得到状态空间( , …… ),观测变量分别为( , …… )。然后当样本在时刻t时处于状态 ,等到了t+1时刻,状态属于 的频数为 ,则可以用该频数来表达估计状态转移概率 为:
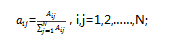
当样本状态为 ,观测为 的频数为 ,则可以用该频数来表示观测概率 为:
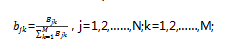
而初始状态概率 即为训练数据中所有初始状态为 的样本的频率。所以,有监督学习通过对训练数据进行统计估计就可以得到模型的相应参数 =[A,B, ]。
3.2.无监督学习
无监督学习即训练数据仅仅只有观测值(观测序列),而没有与其对应的状态序列,因此状态序列S实际上是处于隐藏状态,也就无法通过频数来直接估计概率了。对于这一算法有专门的类似前向-后向算法的Baum-Welch算法来学习。该算法与聚类算法中用到的EM算法类似,即运用迭代思想解决数据缺失情况下的参数估计问题,其基本过程是根据已经给出的观测数据,估计出模型参数的值;然后再依据上一步估计出的参数值来估计缺失数据的值,再根据估计出的缺失数据加上之前己经观测到的数据重新再对参数值进行估计,然后反复迭代,直至最后收敛,迭代结束。
4.总结
在深度学习模型运用在自然语言处理之前,对于自然语言领域的序列数据进行处理是采用概率统计模型,具体的概率统计模型有HMM和CRF两种,其中最为核心的是HMM模型,CRF也是是类似HMM的一个模型。
该篇文章主要针对HMM模型进行阐述,有助于读者更为全面地掌握HMM模型,由于篇幅缘故,CRF模型将在后续进行阐述。该模型也是在HMM基础上进行延申的,适用性低于HMM模型。因此,对于HMM模型的掌握至关重要,同时目前针对于自然语言处理领域深度学习技术的瓶颈问题(难以取得较大改善的结果),不妨考虑换个思维,使用下概率统计模型HMM来处理,也许能取得不错的效果。
作者介绍
稀饭,51CTO社区编辑,曾任职某电商人工智能研发中心大数据技术部门,做推荐算法。目前攻读智能网络与大数据方向的研究生,主要擅长领域有推荐算法、NLP、CV,使用代码语言有Java、Python、Scala。