一、为什么要做前端监控
- 更快地发现问题。
- 做产品决策依据。
- 提升前端开发的技术深度和广度。
- 为业务扩展提供更多可能性。
二、前端数据分类
前端的数据其实有很多,从大众普遍关注的 PV、UV、广告点击量,到客户端的网络环境、登陆状态,再到浏览器、操作系统信息,最后到页面性能、JS 异常,这些数据都可以在前端收集到。
2.1 访问相关的数据
- PV/UV:最基础的 PV(页面访问量)、UV(独立访问用户数据量)。
- 页面来源:页面的 referer,可以定位页面的入口。
- 操作系统:了解用户的 OS 情况,帮助分析用户群体的特征,特别是移动端、iOS 和 Android 的分布就更有意义了。
- 浏览器:可以统计到各种浏览器的占比,对于是否继续兼容 IE6、新技术(HTML5、CSS3 等)的运用等调研提供参考价值。
- 分辨率:对页面设计提供参考,特别是响应式设计。
- 登录率:登陆用户具有更高的分析价值,引导用户登陆是非常重要的。
- 地域分布:访问用户在地理位置上的分布,可以针对不同地域做运营、活动等。
- 网络类型:wifi/3G/2G,为产品是否需要适配不同网络环境做决策。
- 访问时段:掌握用户访问时间的分布,引导削峰填谷、节省带宽。
- 停留时长:判断页面内容是否具有吸引力,对于需要长时间阅读的页面比较有意义。
- 到达深度:和停留时长类似,例如百度百科,用户浏览时的页面到达深度直接反映词条的质量。
2.2 性能相关的数据
- 白屏时间:用户从打开页面开始到页面开始有东西呈现为止,这过程中占用的时间就是白屏时间。
- 首屏时间:用户浏览器首屏内所有内容都呈现出来所花费的时间。
- 用户可选择操作时间:用户可以进行正常的点击、输入等操作。
- 页面总下载时间:页面所有资源都加载完成并呈现出来所花的时间,即页面 onload 的时间。
- 自定义的时间点:对于开发人员来说,完全可以自定义一些时间点,例如:某个组件 init 完成的时间、某个重要模块加载的时间等等。
2.3 点击相关的数据
- 页面总点击量。
- 人均点击量:对于导航类的网页,这项指标是非常重要的。
- 流出 url:同样,导航类的网页,直接了解网页导流的去向。
- 点击时间:用户的所有点击行为,在时间上的分布,反映了用户点击操作的习惯。
- 首次点击时间:同上,但是只统计用户的第一次点击,如果该时间偏大,是否就表明页面很卡导致用户长时间不能点击呢?
- 点击热力图:根据用户点击的位置,我们可以画出整个页面的点击热力图,可以很直观地了解到页面的热点区域。
2.4 异常相关的数据
这里的异常是指 JS 的异常,用户的浏览器上报 JS 的 bug,这会极大地降低用户体验
- 异常的提示信息:这是识别一个异常的最重要依据,如:e.src 为空或不是对象
- JS 文件名。
- 异常所在行。
- 发生异常的浏览器。
- 堆栈信息:必要的时候需要函数调用的堆栈信息,但是注意堆栈信息可能会比较大,需要截取。
2.5 其它数据
除了上面提到的 4 类基本的数据统计需求,我们当然还可以根据实际情况来定义一些其他的统计需求,如用户浏览器对 canvas 的支持程度, 再比如比较特殊的-用户进行轮播图翻页的次数,这些数据统计需求都是前端能够满足的,每一项统计的结果都体现了前端数据的价值。
三、性能指标
- FP(First Paint):首次绘制时间,包括了任何用户自定义的背景绘制,它是首先将像素绘制到屏幕的时刻。
- FCP(First Content Paint):首次内容绘制。浏览器将第一个 DOM 渲染到屏幕的时间,可能是文本、图像、SVG 等。这其实就是白屏时间。
- FMP(First Meaningful Paint):首次有意义绘制。页面有意义的内容渲染的时间
- LCP(Largest Contentful Paint)。最大内容渲染。代表在 viewport 中最大的页面元素加载的时间。
- DCL(DomContentLoaded):DOM 加载完成。当 HTML 文档被完全加载和解析完成之后,DOMContentLoaded 事件被触发。无需等待样式表,图像和子框架的完成加载。
- L(onload):当依赖的资源全部加载完毕之后才会触发。
- TTI(Time to Interactive):可交互时间。用于标记应用已进行视觉渲染并能可靠响应用户输入的时间点。
- FID(First Input Delay):首次输入延迟。用户首次和页面交互(单击链接、点击按钮等)到页面响应交互的时间。
四、前端监控目标(监控分类)
4.1 稳定性(stability)
- JS 错误,JS 执行错误或者 Promise 异常。
- 资源异常,script、link 等资源加载异常。
- 接口错误,ajax 或 fetch 请求接口异常。
- 白屏,页面空白。
4.2 用户体验(experience)
- 加载时间,各个阶段的加载时间。
- TTFB(Time To First Byte 。 首字节时间)。是指浏览器发起第一个请求到数据返回第一个字节所消耗的时间,这个时间包含了网络请求时间、后端处理时间。
- FP(First Paint 首次绘制)。首次绘制包括了任何用户自定义的背景绘制,它是将第一个像素点绘制到屏幕的时间。
- FCP(First Content Paint 首次内容绘制)。首次内容绘制是浏览器将第一个 DOM 渲染到屏幕的时间,可以是任何文本、图像、SVG 等的时间。
- FMP(First Meaningful Paint 首次有意义绘制)。 首次有意义绘制是页面可用性的量度标准。
- FID(First Input Delay 首次输入延迟)。用户首次和页面交互到页面响应交互的时间。
- 卡顿。 超过 50ms 的任务。
4.3 业务
- PV:page view 即页面浏览量或点击量。
- UV:指访问某个站点的不同 IP 地址的人数。
- 页面停留时间:用户在每一个页面的停留时间。
五、前端监控流程
- 数据埋点。
- 数据上报。
- 分析和计算,将采集到的数据进行加工总结。
- 可视化展示,将数据按照各种维度进行展示。
- 监控报警,发现问题后按一定的条件触发报警。
六、常见的埋点方案
6.1 代码埋点
代码埋点,就是以嵌入代码的形式进行埋点,比如要监控用户的点击事件,会选择在用户点击时插入一段代码,保存这个监听行为或者直接将监听行为 以某一种数据格式直接传递给服务器端。
优点是可以在任意时刻,精确的发送或保存所需要的数据信息。
缺点就是工作量大。
6.2 可视化埋点
通过可视化交互的手段,代替代码埋点。
将业务代码和埋点代码分离,提供一个可视化交互的页面,输入为业务代码,通过这个可视化系统,可以在业务代码中自定义 的增加埋点事件等等。最后输出的代码耦合了业务代码和埋点代码。
可视化埋点其实是用系统来代替手工插入埋点代码。
6.3 无痕埋点
前端的任意一个事件都被绑定一个标识,所有的事件都被记录下来。
通过定期上传记录文件,配合文件解析,解析出来我们想要的数据,并生成可视化报告供专业人员分析。
无痕埋点的优点是采集全量数据,不会出现漏埋和误埋等现象。
缺点是给数据传输和服务器增加压力,也无法灵活定制数据结构。
七、编写监控采集脚本
7.1 监控错误
- 错误分类JS 错误Promise 异常。
- 资源异常监听 error。
7.2 数据结构设计
- jsError
let info = {
title: "前端监控系统", // 页面标题
url: "http://localhost:8080", // 页面url
timestamp: "1212121212121212", // 访问时间戳
userAgent: "chrome", // 用户浏览器类型
kind: "stability", // 大类
type: "error", // 小类
errorType: "jsError", // 错误类型
message: "uncaught TypeError:blablabla", // 错误详情
filename: "http://localhost:8080/", // 访问的文件名
position: "0:0", // 行列信息
stack: "btn Click (http://localhost:8080)", // 堆栈信息
selector: "HTML BODY #container .content INPUT", // 选择器
};- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 接口异常数据结构设置
let info = {
title: "前端监控系统", // 页面标题
url: "http://localhost:8080", // 页面url
timestamp: "1212121212121212", // 访问时间戳
userAgent: "chrome", // 用户浏览器类型
kind: "stability", // 大类
type: "xhr", // 小类
eventType: "load", // 事件类型
pathname: "/success",
status: "200-0k",
duration: "5", // 持续时间
response: "hahah", // 响应内容
params: "参数", // 参数
};- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 白屏 screen 返回当前 window 的 screen 对象,返回当前渲染窗口中和屏幕有关的属性innerWidth 只读的 window 属性。innerWidth 返回以像素为单位的窗口的内部宽度innerHeight 窗口的内部高度(布局视口)的高度layout_viewportelementsFromPoint 方法可以获取到当前视口内指定坐标处,由里到外排列的所有元素。
let info = {
title: "前端监控系统",
url: "http://localhost:8080/",
timestamp: "1239404040404044",
userAgent: "chorme",
kind: "stability",
type: "blank",
emptyPoints: "0", // 空白点
screen: "2049 * 1152", // 分辨率
viewPoint: "2048 * 994", // 视口
selector: "HTML BODY #container", // 选择器
};- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
整体大致可以分四个阶段:信息采集、存储、分析、监控。
采集阶段:收集异常日志,先在本地做一定的处理,采取一定的方案上报到服务器。
存储阶段:后端接收前端上报的异常日志,经过一定处理,按照一定的存储方案存储。
分析阶段:分为机器自动分析和人工分析。机器自动分析,通过预设的条件和算法,对存储的日志信息进行统计和筛选,发现问题,触发报警。人工分析,通过提供一个可视化的数据面板,让系统用户可以看到具体的日志数据,根据信息,发现异常问题根源。
报警阶段:分为告警和预警。告警按照一定的级别自动报警,通过设定的渠道,按照一定的触发规则进行。预警则在异常发生前,提前预判,给出警告。
性能监控: 使用 Resource Timing API 和 Performance Timing API,可以计算许多重要的指标,比如页面性能统计的起始点时间、首屏时间等。
异常监控: 前端捕获异常分为全局捕获和局部捕获。局部捕获作为补充,对某些特殊情况进行捕获,但分散,不利于管理。所以,我会选择全局捕获的方式,即通过全局的接口,将捕获代码集中写在一个地方。具体在实现项目中,我应该会采用 badjs-report,它重写了 window.onerror 进行上报异常,无需编写任何捕获错误的代码。
前端埋点: 埋点的方案有手动埋点,即在需要监控的地方插入监控逻辑,但是工作量可能会很大;还有无埋点,前端自动采集全部事件,上报埋点数据,但是缺点是服务器压力会很大。我可能倾向于采用声明式埋点,将埋点代码和具体的业务逻辑解耦,只用关心需要埋点的控件,并且为这些控件声明需要的埋点数据即可,主要是为了降低埋点的成本吧。在 dom 元素上增添埋点信息,比如:
// key表示埋点的唯一标识;act表示埋点方式
<button data-stat="{key:'buttonKey', act: 'click'}">埋点</button>- 1.
- 2.
埋点
监控告警: 这里我认为最便捷、高效的方式,就是接入内部的告警组了吧,尤其是在阿里,似乎什么轮子都有,那可能需要考虑就是触发告警的阈值和时机了。
性能:使用 Performance API,可以得到许多重要的指标,如页面性能统计的起始点时间、首屏时间等。
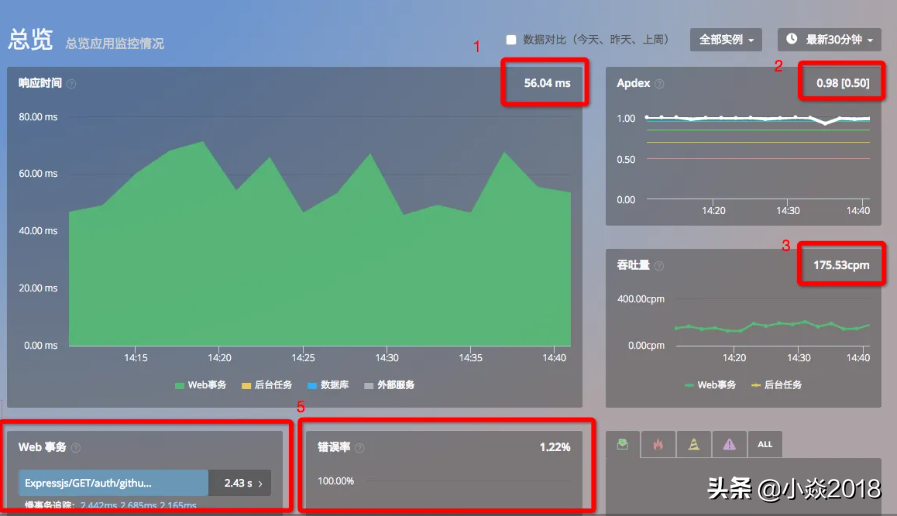
报错:使用 onerror 和 onunhandledrejection,甚至是 try catch。
操作行为:对事件触发函数做 patch,或者添加特定的事件监听。
PV/UV:利用浏览器存储方法或 Cookie、IP 等储存相应用户信息,随请求发送。
设备信息:获取 navigator.userAgent。
PV、UV 属于增长数字类型,可以用 Redis 等记录,如果有需要,定时入库。其他属于大量文字信息,可以用成熟的消息队列来消费。因为有大量写,所以可以考虑做读写分离。
技术难点:
可能整个系统比较复杂的就是如何高效合理的进行监控数据上传。除了异常报错信息本身,还需要记录用户操作日志,如果任何日志都立即上报,这无异于自造的 DDOS 攻击。那就需要考虑前端日志的存储,日志如何上传,上传前如何整理日志等问题。
前端在收集的过程中可能会影响用户体验。
后端对于收到的日志要使用合适的工具进行收集,数据量大时选择如何取舍。
可能会采取的方案:
- indexDB 存储日志,因为容量大、异步!不用考虑阻塞页面问题。
- 在一个 webworker 中对日志进行整理,比如对每一条日志打上标签,进行分类等操作。
- 上报日志也在 webworker 中进行,可以按照重要紧急度区分,判断是否延时或者立即上报。