













应用场景
说起计数器,大多数人都不陌生,毕竟计数器的应该实在是太多太多了。小到一个博客系统的文章数目,大到抖音视频点赞数、评论数,淘宝中商品库存数量等等。
可以说计数的目的就是为一个对象打上一个数字,这个数字用于表征某种业务含义。通常情况下,我们不一定需要显示地去创建一个计数器,比如我们要统计店铺的宝贝数量,只要写一个 SQL 语句把剩余的商品数量实时统计出来,这样实现的精确度最高,但是缺陷就是如果流水数量很大,会出现明显的性能瓶颈。比如说,我们以抖音的点赞数为例,对于一个火热的视频,有百万级的点赞流水,显然每次都有count如此大的数量是不可能的。
所以,这个时候计数器的需求就横空出世了,计数器,简单理解就是帮助我们快速获取 count 结果的机制。
计数器使用案例:高性能获取计数值
分布式计数器的实现
单机计数器的实现没什么好说的,每种编程语言都提供了对应的数据结构,这里我们来分析下分布式计数器的实现方法。通常,我们有两种选择:MySQL 计数器、Redis 计数器。
① 基于 MySQL 实现计数器
使用 MySQL 来实现计数器,我们可以单独创建一张表,这个表主要有一个业务主键列,用于表示业务id(比如视频id),同时需要有个计数列,用于记录当前的计数值。
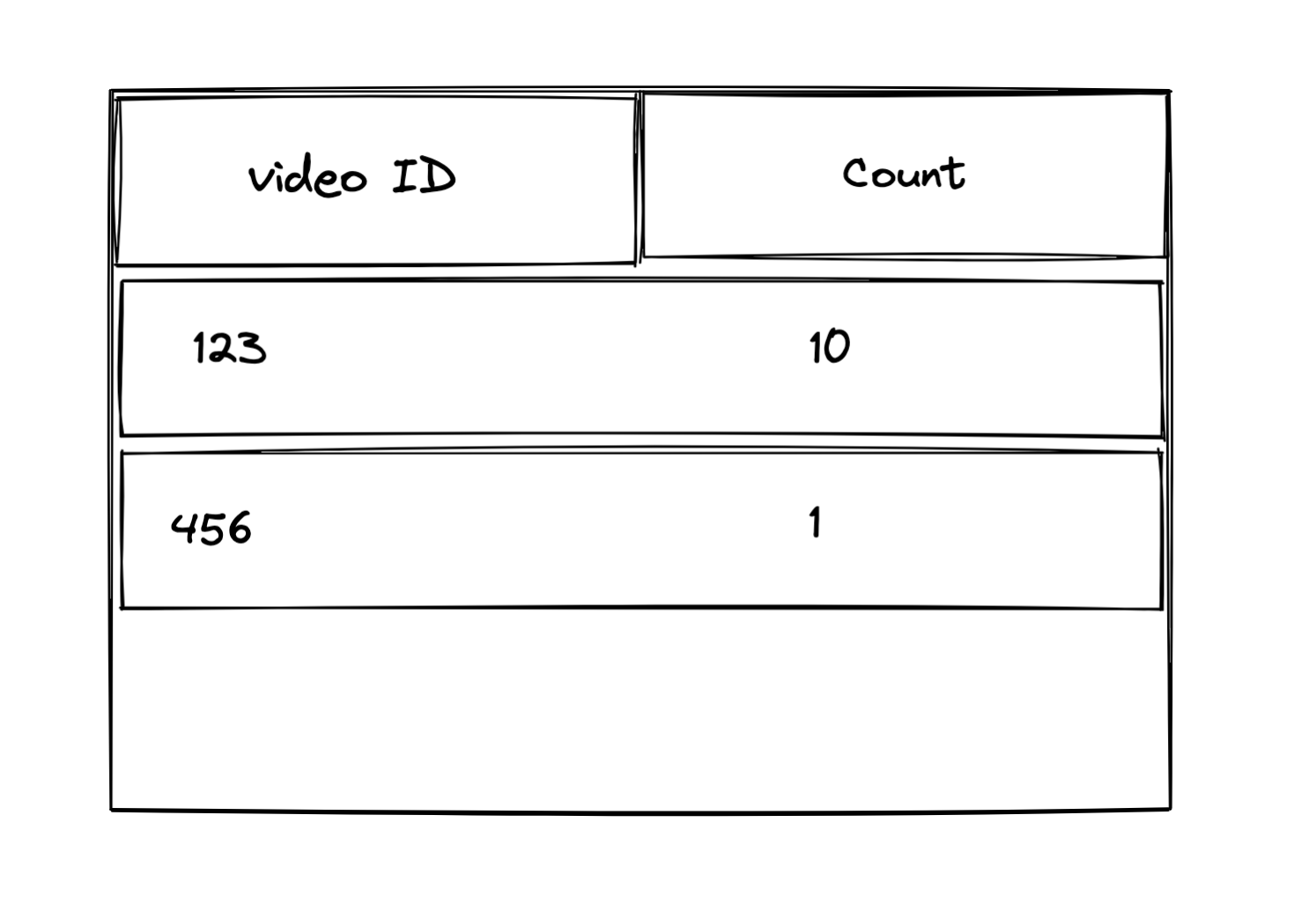
一张简单的 MySQL 表
当有数据增加时,可以使用乐观锁保证幂等性,如果执行失败自旋重试即可。
// 先 select 出当前 current_count
select count as current_count from xxx where id = 'xxx'
// 更新计数值
update xxx set count = current_count + 1 where id = 'xxx' and count = current_count
用 MySQL 实现计数器很简单,而且如果业务数据也在 MySQL 中,那么可以很方便地做跨表事务,保证整体数据的一致性。但是缺陷也很明显,因为 `update` 语句存在行锁(甚至如果id不是主键,可能是间隙锁),那么在竞争激烈的情况下,可能存在严重的性能退化。
这个时候,可以考虑做一下性能优化:减小锁粒度。
实现也很简单,就是相同业务 ID 可以用 X 条数据,每次更新的时候随机更新一条,这样锁冲突的概率就降低到 1 / X 了,查询计数值的时候需要修改为对相同业务 ID 求 Sum(count)。
② 基于 Redis 实现计数器
使用 Redis 来作为分布式计数器也是一种常见的手段,相比于 MySQL,Redis 几乎不存在性能问题(单机可支持10w qps+),并且 Redis 内置了 `IncrBy` 操作,可以原子的实现计数的累加。
但是,使用 Redis 作为计数器有个困扰之一就是操作是非幂等的,比如你调用了 `IncrBy` 命令后,收到网络错误,你无法确定服务端到底是执行成功了,还是执行失败了。这导致你无法确定是否应该重试,最终导致计数结果的偏差,典型的两军问题。
为了解决这个问题,最常见的方法是使用 LUA 脚本,在每次要执行 INCR 的时候,同时使用 `SETNX` 设置一个值,LUA 脚本保证 SETNX 和 INCR 操作同时成功或者同时失败(原子性),这样当你收到错误的返回信息时,是否要重试仅是判断对应的 KEY 是否已经设置成功了。
举个栗子:某个视频收到一个点赞,假设点赞的业务id=1000,那么 LUA 脚本的执行逻辑是 `SETNX 1000 true` + `IncrBy countKey` 同时成功。
最后,使用 Redis 计数器,要防止热 KEY。虽然 Redis 能承受的请求量很大, 但是毕竟是单点存储(读写分离),所有写请求还是都打在同个节点上,需要评估对单个节点的写入 QPS,务必防止超热的 KEY 出现。
权衡:一致性与可用性
通常情况下,计数器和流水单独计算,由于是异构存储,可能存在一定的不一致性。
这个时候,我们需要权衡业务对不一致性的容忍情况,一般需要权衡的是可用性以及一致性的冲突。
如果一致性很重要,可以考虑使用 MySQL 模式,将业务数据与计数器做在同个事务中,保证强一致,或者引入分布式事务,来保证异构存储的一致性,或者是使用 Redis 计数器 + LUA 脚本模式等。
但是,需要注意的是无论是何种模式,一致性高的,必然性能、可用性会有所折损。如果业务没有强诉求,无需搞得这么复杂,可以引入一个定时回扫脚本,定时更正下即可。
记住,不考虑业务的架构,都是耍流氓。
结束语
在我们的业务开发工作中,经常会遇到计数器的诉求。刚开始,我觉得很简单,不就是 Redis Incr 一下吗?实际上,当业务变得复杂,当数据量变得庞大,当对计数器的一致性要求变高,这一切在演进中都变得复杂而难以处理。
上面的是我在日常工作中总结的两种比较常用且有效的分布式计数器实现方案,如果你的工作中也有用到,也可以尝试尝试。如果暂时没有用到,适当的了解,在面试、日常的工作交流中相信也都会受用。
























