













作者 | 剑萧
阿里大淘系数据体系经过多年发展,通过丰富的数据和产品支撑了复杂的业务场景,在数据领域取得了非常大的领先优势。随着数据规模越来越大,开发人员越来越多,虽有阿里大数据体系规范进行统一管理,但是由于没有在产品侧进行有效的模型设计和管控,在模型规范性、应用层效率、通用层复用性等方面的问题逐渐凸显。计存成本提升、效率降低、规范减弱、数据使用难度变大、运维负担增加等。
为了解决这些问题,我们进行了大淘系模型治理专项,在数据服务业务的同时,追求极致的降本提效目标。
参与团队:
- 数据技术及产品部-大淘系数据团队
- 数据技术及产品部-数据安全生产平台&计算平台事业部-DataWorks
- 计算平台事业部-产品与解决方案-DataWorks
- PAI产品组
一、数据现状
为了更好的分析当前大淘系的数据问题,我们进行了详细的数据分析,首先进行数字化。(整个问题分析有详细的数据支撑,涉及到数据安全,因此只抽象问题,不展示具体数据细节)。
1 规范性问题
- 表命名不规范,缺乏管控:随着数据量增长,大淘系的表出现了大量命名未遵循阿里大数据体系的情况,难以管控。
2 通用层复用性问题
- 通用层表复用性不高:通用层表下游引用少于2个的数量非常多;
- 通用层建设不足或通用层透出不足:cdm引用下降,ads引用上升;
- 较多的ads表共性逻辑未下沉:出现很多ads表代码重复,字段相似度高的情况;
3 应用层效率问题
- 临时表多,影响数据管理:出现了很多TDDL临时表、PAI临时表、机器临时表、压测临时表等;
- 通用层表在各团队分布不合理:散布多个团队;
- 较多的ads表共性逻辑未下沉;
- 部分ads表层内依赖深度较深:很多ads表在应用层的深度超过10层;
- 应用层跨集市依赖问题明显:不同集市间ads互相依赖,不仅影响了数据稳定性,而且数据准确性也难以保障;
- 存在大量的可交接的通用层表:不同团队的通用层数据与大淘系数据混合在一起;
- 表人员分配不均衡:表owner管理的表数量分布很不均匀,有些owner名下只有几十张,有些owner名下有几千张;
二、问题分析
通过对当前数据问题的数字化,我们发现问题涉及到数据的评、建、管、用各个环节。
评:缺乏一套统一数据评估体系。数据问题的发现以往主要通过专家经验、开发使用环节发现和离散型的数据分析得到,缺乏一套统一的数字化评估体系。数据量有多少?不同层次的数据分布如何?表的命名规范性如何?表的复用性如何?表的加工效率和消费效率如何?如何评价数据建设、使用和维护的好不好?好的数据应该通过哪些指标评估出来?
建:基于数据问题分析我们发现:在统一进行通用层构建和治理的时间段,数据在规范性、复用性、链路复杂度、使用效率等方面表现较好,但是在没有进行统一构建和治理的时间,数据在各方面都表现不好。原因在于:我们有一套阿里大数据体系规范,但是我们并没有一套覆盖设计、评审、开发、管控、治理的建模开发产品。
管:数据构建完成后后,并没有有效的对数据进行成本、复用性、效率、健康情况的管理,通常依赖于集中治理、专项治理或推送治理。成本高、迭代慢。同时还存在表管理分布不均的问题,有些owner承担了大量的管理和运维工作,数据交接后难以维护,导致数据使用难度高。
用:数据最终是为了使用,通过数据分析和调研问卷来看,普遍存在以下问题:找数难、不会用、不敢用等问题。就导致除了一些非常核心的模型数据外,很多开发者宁愿重新开发也不愿去花费很大精力去找数和理解数据,造成恶性循环。
三、解决方案
针对对问题的分析,我们确定了以下目标:
- 模型数字化:构建一套通用的大淘系模型评估体系,能够清晰的从多个维度评估当前数据的健康情况,针对问题数据提供改进建议。
- 提效公共模型下沉:定义清晰通用层数据下沉标准,能够清晰的界定哪些数据应该沉淀到通用层,对于需要沉淀的数据要及时进行沉淀。
- 产品化:通过共建开发一套覆盖设计、评审、开发、管控、治理的建模开发产品。
- 日常治理:日常监控模型健康情况,并进行治理优化。
- 找数提效:通过共建提高数据检索效率,提高推荐准确度,将核心数据在数据专辑展示。
为了实现以上目标,我们进行了模型治理整体设计:
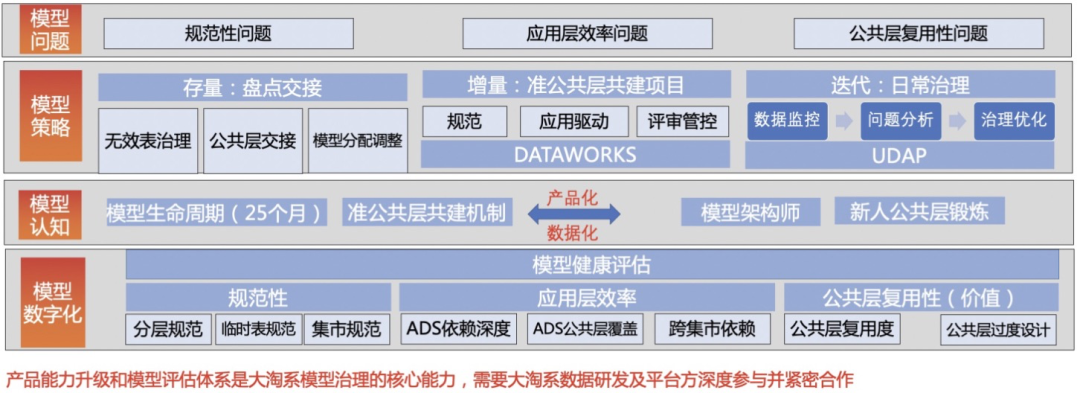
1.DataWorks共建
DataWorks是基于MaxCompute/EMR/Hologres等大数据计算引擎,提供专业高效、安全可靠的一站式大数据开发与治理平台。通过与DataWorks团队进行深度共建,利用大淘系多年积累的模型、开发、运维等数据经验提供输入和DataWorks强大的产品研发能力,进行智能建模、开发助手、数据地图等功能的升级,实现数据设计、开发、管控、使用全链路产品化,解决长久以来的数据问题。
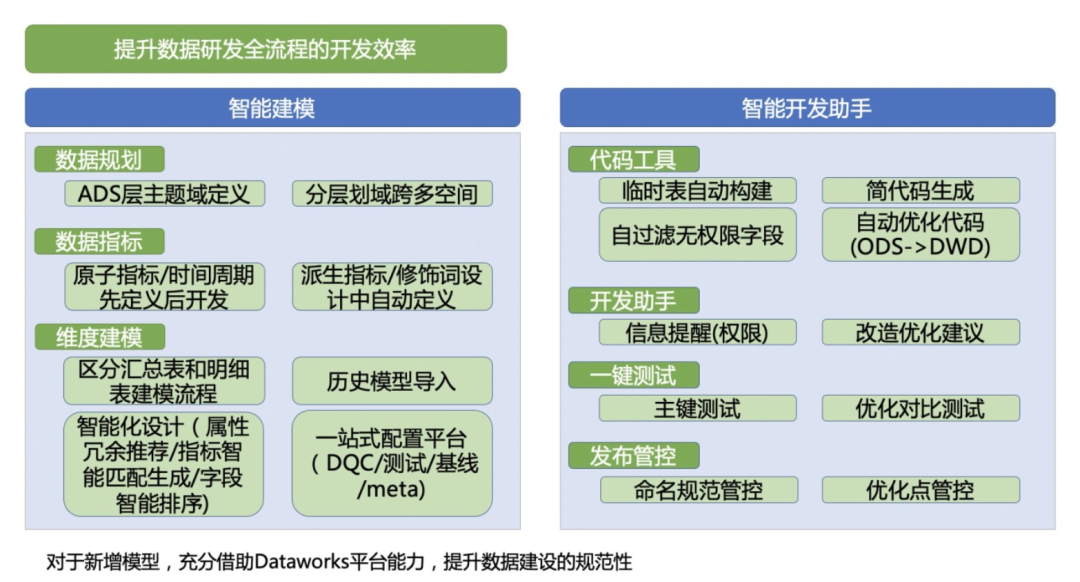
DataWorks智能数据建模
目前,DataWorks智能数据建模产品完成了数仓规划、数据标准、维度建模、数据指标四大产品模块的重大产品功能迭代,具备逆向建模、正向可视化建模、excel建模、代码建模等产品能力,并完成了DataWorks智能数据建模产品在2021年云栖大会的新功能重磅发布。
DataWorks智能数据建模产品全新发布的核心产品功能主要包含以下内容:
数仓规划:
- 支持公共层及应用层数仓经典分层化域方案所需要素(如数据域、数据集市等)的业务自定义;
- 支持数仓规范的业务自定义,如各层表名规范定义;
- 支持建模空间,支持设置建模空间与数据研发空间的关系建立,满足大淘系多业务共享数据规范统筹管理数据模型的需求。
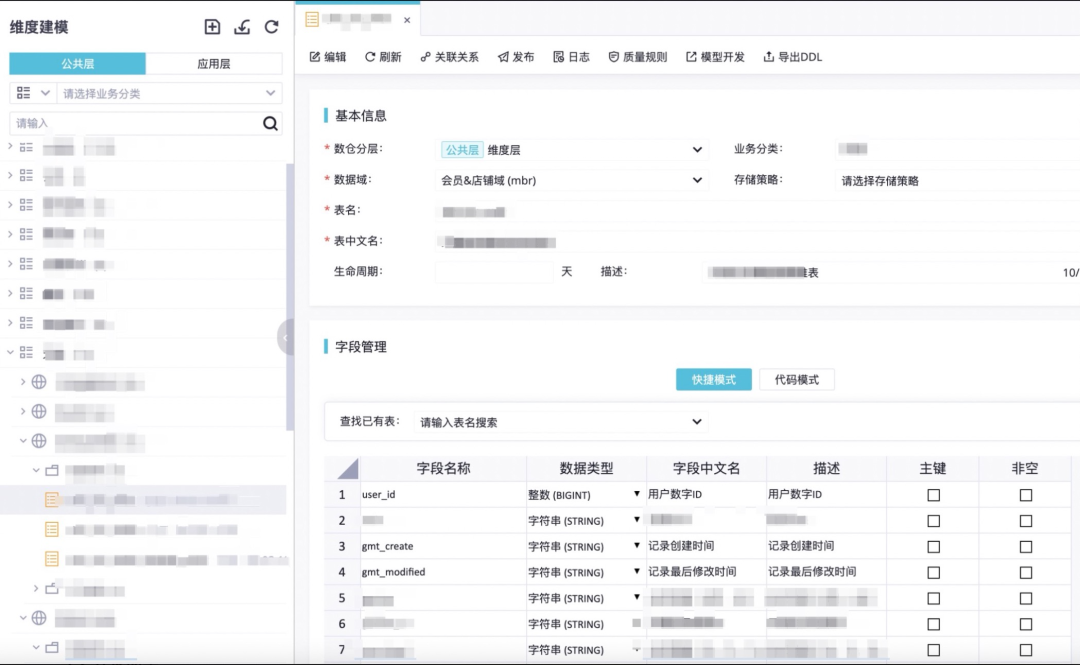
维度建模:
- 支持数仓已有物理表的、的逆向建模,解决了大淘系已有物理表的冷启动难题。
- 支持维度表、明细表、轻度汇总表和应用层表的正向建模,支持可视化建模、excel文件导入模型及代码建模三种方式。正向可视化建模产品功能汲取了大淘系建模同学沉淀的经典建模理论,依托了MaxCompute的优势,实现了快速复制MC已有物理表的表结构并支持基于已有字段做维度字段冗余的产品功能,此外,汇总表及应用层表可快速引用已创建的指标生成模型表字段。正向建模excel文件导入模型将大淘系同学数年来沉淀的经典模型excel模版产品化,满足部分习惯性excel建模同学的建模需求。正向建模产品功能,极大程度上提升了建模效率。
- 设计完成的模型,支持模型评审及物理表发布到MaxCompute、Hologres等五种引擎。
- 发布成功的模型,实现了和DataStuido(数据开发)的打通,支持自动生成ETL框架代码,数据开发同学只需在此代码基础上补充业务逻辑代码即可,该功能在一定程度上提升了数据开发同学的研发效率;
以上产品功能能很好的解决模型建设规范性和提效的目的。
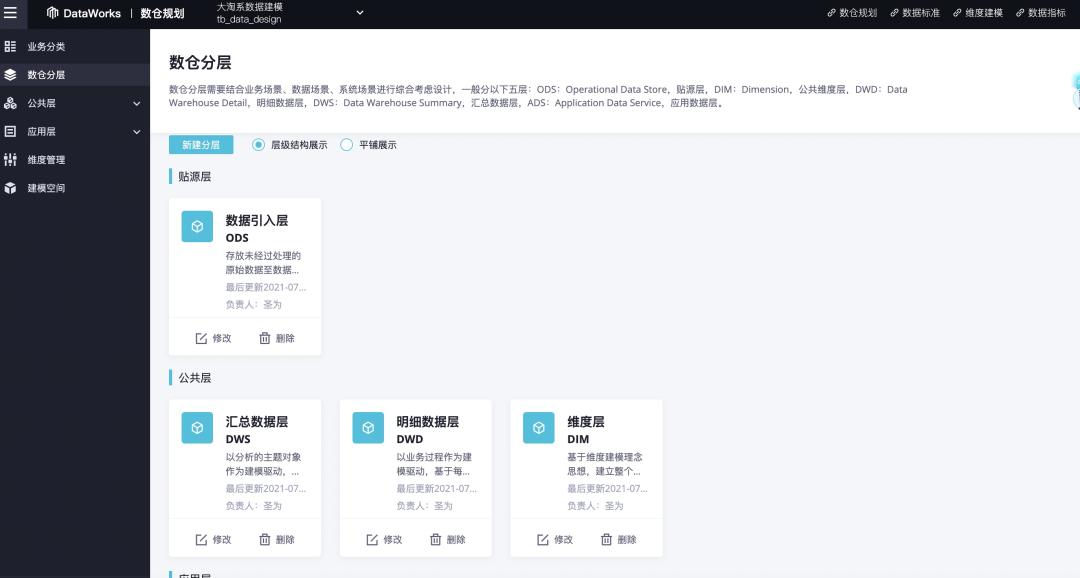
数仓规划
维度建模
开发助手
开发助手可以在代码开发中进行权限提醒、发布管控、临时表自动构建等。
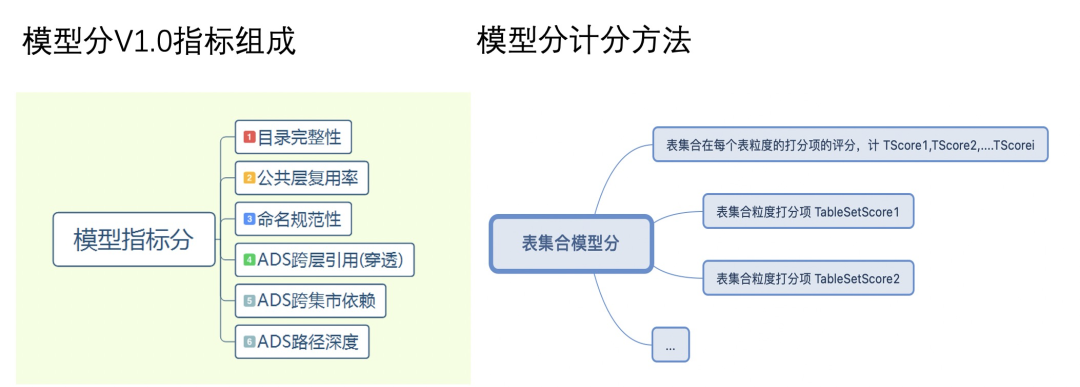
2.模型分
模型分打分逻辑
模型分大盘
我们将模型分评估在内部通过数字大盘的形式展示,并将对应的治理建议通过治理跳转的方式直接跳转到相应的产品页面进行操作。
为了更好的实现复用,模型分支持快速配置接入,只要提供project清单即可通过修改配置快速接入对应BU的数据,产出表级别、owner级别、BU级别模型分及治理动作。
模型大盘的治理项使用了全链路血缘和标签能力,可以比较精准的实现针对性治理。
3.找数提效
找数提效方案:
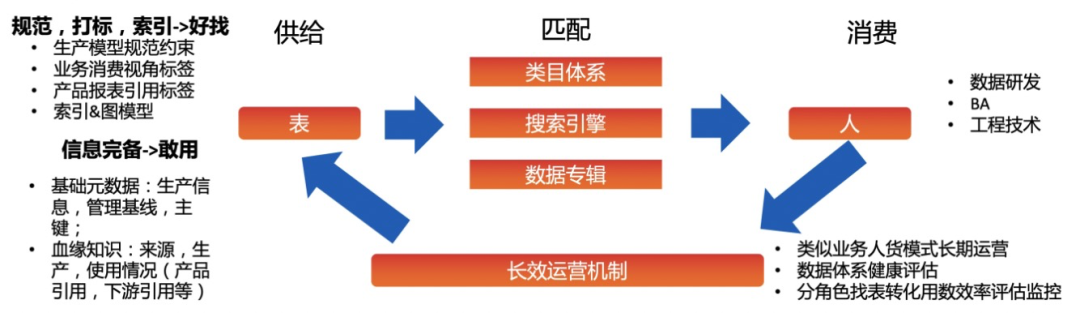
目前,数据地图上线了团队常用表、猜你会用、热门浏览、热门读取、数据专辑、搜索优化、表说明升级等,表说明功能已完成升级;数据专辑的多人协作维护、展示和修改收藏备注发布、专辑增加使用说明功能。对于找数、用数、数据维护具有重要的意义。
【搜索&推荐】搜索结果过滤增强
- 搜索结果左侧过滤条件透出高频使用条件供用户选择,提高筛选效率和搜索CTR。
- 恢复字段搜索功能,搜索过滤支持按照环境过滤。
【内容&组织】表说明功能升级
- 升级表使用说明编辑器为语雀编辑器,支持导入语雀内容,来帮助解决口径问题
【内容&组织】数据专辑
- 数据专辑提供管理员功能,支持多人协作维护。
- 加入专辑支持展示和修改收藏备注。
- 个人专辑详情页中,支持通过表的描述和收藏备注进行搜索。
- 专辑增加使用说明功能
【内容&组织】数据地图与DataWorks数据打通
- 支持在地图中标识表是模型表、展示出表的模型信息。
1)搜索推荐

2)数据专辑
数据专辑中将核心表集中展示,可以有效实现核心表的查找和使用。
3)专辑说明
将结构化的知识集中管理,支持语雀知识导入,更好的管理和维护数据。
4)数据百晓生
将数据知识进行算法处理,透过机器人问答实现找表、用表等。为此我们结合内部机器人产品构建了智能答疑机器人。
四、思考总结
经过FY22大淘系模型治理专项,通过大淘系内部开发、与DataWorks团队&数据安全生产平台共建,实现了以下重要能力:
模型评估体系:设计并定义了大淘系模型评估体系,从多个维度实现了数据健康度的评估和表级别的治理建议。
智能建模:与DataWorks智能建模团队合作,上线了数仓规划、维度建模等重磅产品,实现了维度表、明细表、轻度汇总表和应用层表的正逆向建模。
数据地图升级:升级了搜索推荐、数据专辑、表说明等重要功能,极大的提高了找数、用数、管理数据的效率。
协作规章制度:定义了准通用层下沉规范、协作规章、交接流程、新人培养机制等清晰的制度,提供清晰的制度保障。
五、后续规划
目前,大淘系模型治理已经取得了非常好的阶段性成果,在产品共建、模型分评估、找数提效方面都有很好的效果产出。但仍然存在一些未解决问题:
- 统一架构和规范难保障:各业务对阿里大数据体系规范的理解程度不一致,集团数据架构和规范的统一难以保障;
- 业务通用层比较薄:历史背景之下,各业务通用层建设比较薄弱,新架构下业务效率和口径存在风险;
- ADS层持续增长,复杂度难管控:阿里大数据体系规范缺少对应用层的规范,ADS与通用层的边界划分不清晰,ADS的复杂度难以控制;
- 缺乏有效管控:在数据开发与运维层面,阿里巴巴沉淀了大数据体系规范不断与数据平台融合,但是部分标准无法强制执行与数据平台进行集成。数据治理上,当前数据无法有效识别数据表是否无效,导致研发对数据表不敢下、没精力下;
- 数据建设和使用尚未完全打通:当前数据开发和数据使用尚未完全实现数据打通,定义的模型、开发的数据未在数据地图中有效的实现透出和管理。
下阶段将针对尚未解决的问题进一步深入解决:
- 大淘系模型架构
我们会针对当前存在的架构问题进行升级,从架构原则、设计规范、开发规范、运维规范、治理规范、共建机制等方面进行方法论的升级,以更好的适应当前阶段的数据研发现状,切实的从架构层面为降本、提效提供有效保障。
- 智能建模
继续与DataWorks团队共建,进一步提高通用层、应用层开发效率,从产品层面提供保障。
- 数据地图
官方专辑快速接入:当前官方专辑构建需要专人进行配置和维护,后续可以考虑降低接入成本,下放到各个团队进行自主接入和维护,提升数据专辑的丰富度和易用性。
进一步打通数据开发和使用环节:将智能建模的数据与数据地图进一步打通,实现核心模型的快速筛选和透出。
多角度提升表查询和使用的能力:从表说明、表答疑、数据知识提取等方面实现对找表、用表、表答疑的简易度提升,结合文本算法、机器人等技术和产品能力,实现数据知识的智能生成。
- 开发助手
开发助手在表推荐和表管控方面可以进一步升级。
- 大淘系通用层评估体系升级
针对当前的模型分加入模型血缘相关的信息,做厚大淘系通用层,为业务提供更好的通用层数据支撑。
表自动化下线:实现模型、表、服务的自动化下线&专家经验下线,提高数据下线效率,降低人工介入成本。





















