












随着越来越多的企业转向人工智能来完成各种各样的任务,企业很快发现,训练人工智能模型是昂贵的、困难的和耗时的。
一家公司 MosaicML 的目标正是找到一种新的方法来应对这些层出不穷的挑战。近日, MosaicML 推出了一个用于高效神经网络训练的 PyTorch 库「Composer」,旨在更快地训练模型、降低成本,并获得表现更好的模型。
Composer 是一个用 PyTorch 编写的开源库,旨在集成更好的算法来加速深度学习模型的训练,同时实现更低的成本和更高的准确度。目前项目在 GitHub 平台已经收获了超过 800 个 Star。

项目地址:https://github.com/mosaicml/composer

Composer 具有一个功能界面(类似于 torch.nn.functional),用户可以将其集成到自己的训练循环中;它还包含一个 Trainer,可以将高效的训练算法无缝集成到训练循环中。
项目中已经部署了 20 几种加速方法,只需几行代码就能应用在用户的训练之中,或者与内置 Trainer 一起使用。
总体而言,Composer 具备几个亮点:
- 20 多种加速计算机视觉和语言建模训练网络的方法。当 Composer 为你完成工作时,你就不需要浪费时间尝试复现研究论文。
- 一个易于使用的 Trainer,其编写的目的是尽可能提高性能,并集成了高效训练的最佳实践。
- 所有加速方法的功能形式,都允许用户将它们集成到现有的训练循环中。
- 强大、可重现的基线,让你尽可能地快开始工作。
那么,使用 Composer 能够获得怎样的训练效果提升呢?
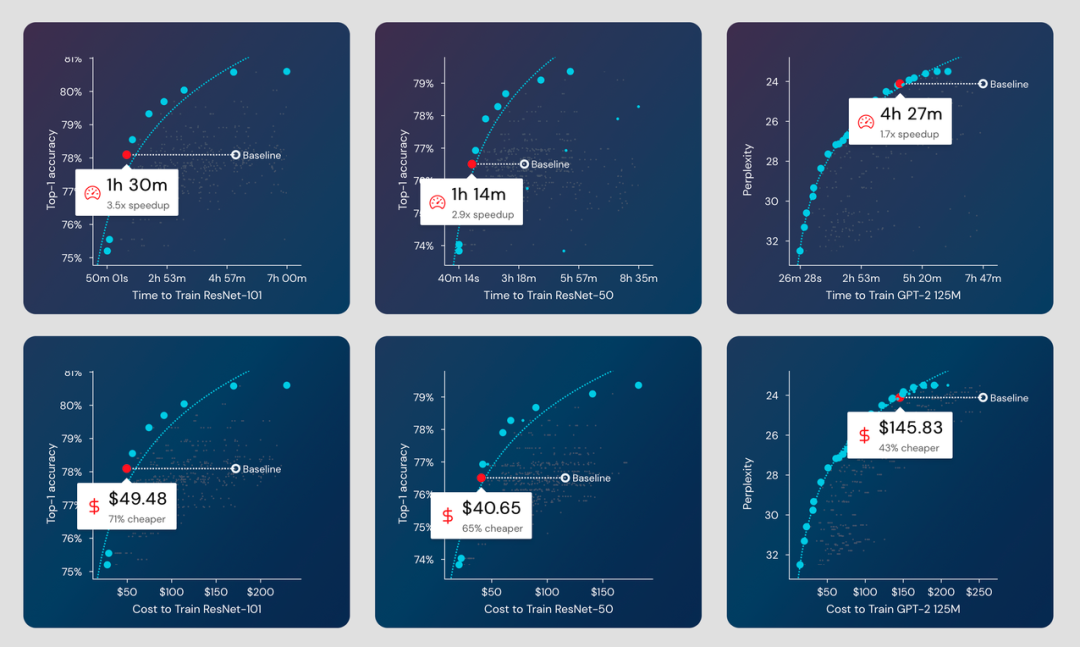 多个模型系列的训练中减少的时间和成本。
多个模型系列的训练中减少的时间和成本。
据项目信息介绍,使用 Composer 训练,你可以做到:
- ResNet-101 在 ImageNet 上的准确率在 1 小时 30 分钟内达到 78.1%(AWS 上 49 美元),比基线快 3.5 倍,便宜 71%。
- ResNet-50 在 ImageNet 上的准确率在 1 小时 14 分钟内达到 76.51%(AWS 上 40 美元),比基线快 2.9 倍,便宜 65%。
- 在 4 小时 27 分钟内将 GPT-2 在 OpenWebText 上的困惑度提高到 24.11(AWS 上 145 美元),比基线快 1.7 倍,便宜 43%。
在 Reddit 社区,项目作者 Jonathan Frankle 现身说法,他介绍说,Composer 是自己关于彩票假设研究的直接延续。
2019 年,Frankle 和 Carbin 的《The Lottery Ticket Hypothesis: Finding Sparse, Trainable Neural Networks》获得了 ICLR 2019 的最佳论文荣誉。在这篇论文中,Frankle 等人发现标准的剪枝技术会自然地发现子网络,这些子网络经过初始化后能够有效进行训练。二人基于这些结果提出了「彩票假设」(lottery ticket hypothesis):密集、随机初始化的前馈网络包含子网络(「中奖彩票」),当独立训练时,这些子网络能够在相似的迭代次数内达到与原始网络相当的测试准确率。
目前,Frankle 是 Mosaic 公司的首席科学家,推动了 Composer 的打造。
这次,Frankle 表示,深度学习背后的「数学」并没有什么神圣之处。从根本上改变「数学」是完全没问题的(比如删除很多权重)。你将获得与其他方式不同的网络,但这不像原始网络是「正确的」网络。如果改变「数学」让你的网络变得同样好(例如同样的准确性)而速度更快,那就是胜利。
如果你愿意打破深度学习背后的「数学」,彩票假设就是一个例子。Composer 有几十种技术可以做到这一点,并且拥有与之匹配的加速。
同时,项目作者们也将 Composer 与 PyTorch Lightning 进行了对比:「PyTorch Lightning 是一个具有不同 API 的不同训练库。实际上,我们在 PTL 之上构建了我们的第一个 Composer 实现。」

PyTorch Lightning 的创建者 William Falcon 也出现在了后续讨论中,但二人似乎未达成共识。
目前,Composer 的训练器可以应用于众多模型,包括对于 Resnet-50、Resnet-101、UNet 和 GPT-2 的加速。
作者表示,未来还将扩展至更多模型,比如 ViT、BERT、分割和目标检测等等。

























