












图神经网络在应用到现实世界时会面临很多挑战,比如内存限制、硬件限制、可靠性限制等。在这篇文章中,剑桥大学在读博士生 Chaitanya K. Joshi 从数据准备、高效架构和学习范式三个方向综述了研究者们在克服这些问题时取得的进展。
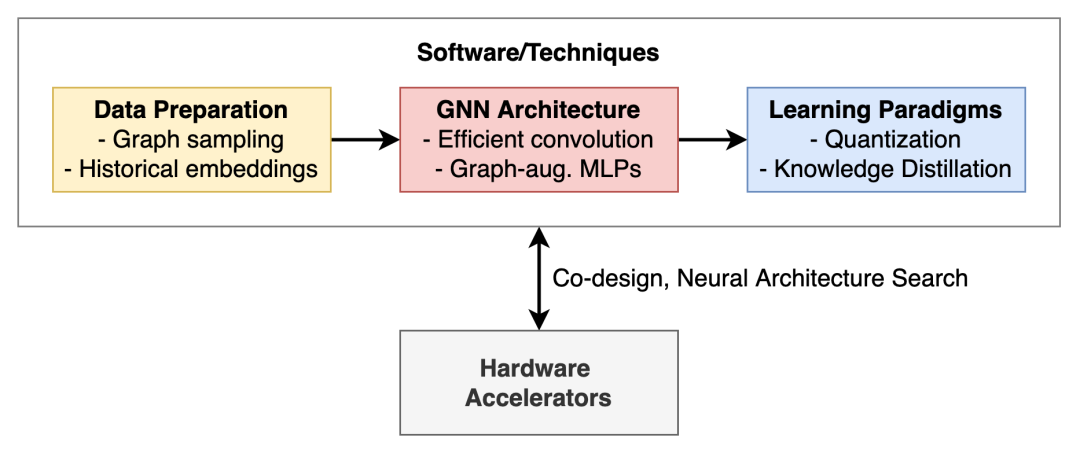 用于高效和可扩展的图形表示学习的工具箱。
用于高效和可扩展的图形表示学习的工具箱。
本文旨在概述关于高效图神经网络和可扩展图表示学习的关键思想,并将介绍数据准备、GNN 架构和学习范式方面的关键进展,这些最新进展让图神经网络能够扩展到现实世界,并应用于实时场景。
具体内容如下:
图神经网络面临的现实挑战
图神经网络作为一种新兴的深度学习体系架构,它可以操作诸如图、集合、3D 点云等不规则数据结构。最近几年,GNN 的发展跨越社交网络、推荐系统、生物医学发现等不同领域。但在实际应用中,构建 GNN 面临以下挑战:
内存限制
现实世界的网络可能非常庞大和复杂,例如 Facebook 有近 30 亿活跃账户,这些账户以点赞、评论、分享等不同方式进行互动,从而在以账户为节点构成的图中创造出无数个边。
 现实世界中的的图网络,例如记录所有 Facebook 用户表以及他们交互方式的图网络,可能非常庞大且难以处理,以至于可能无法将这种巨型图网络安装到 GPU 内存中以训练神经网络。
现实世界中的的图网络,例如记录所有 Facebook 用户表以及他们交互方式的图网络,可能非常庞大且难以处理,以至于可能无法将这种巨型图网络安装到 GPU 内存中以训练神经网络。
硬件限制
图本质上是一种稀疏对象,GNN 按理说应该利用其稀疏性来进行高效和可扩展的计算。但是这说起来容易做起来难,因为现代 GPU 旨在处理矩阵上的密集运算。虽然针对稀疏矩阵的定制硬件加速器可以显著提高 GNN 的及时性和可扩展性,但如何设计仍然是一个悬而未决的问题。
 现代 GPU 更适用于密集矩阵运算,而图本质上是稀疏结构。除非邻接矩阵非常稀疏,否则在实现 GNN 的过程中,将图简单地视为密集矩阵并使用掩码来识别非连通节点通常更快。
现代 GPU 更适用于密集矩阵运算,而图本质上是稀疏结构。除非邻接矩阵非常稀疏,否则在实现 GNN 的过程中,将图简单地视为密集矩阵并使用掩码来识别非连通节点通常更快。
可靠性限制
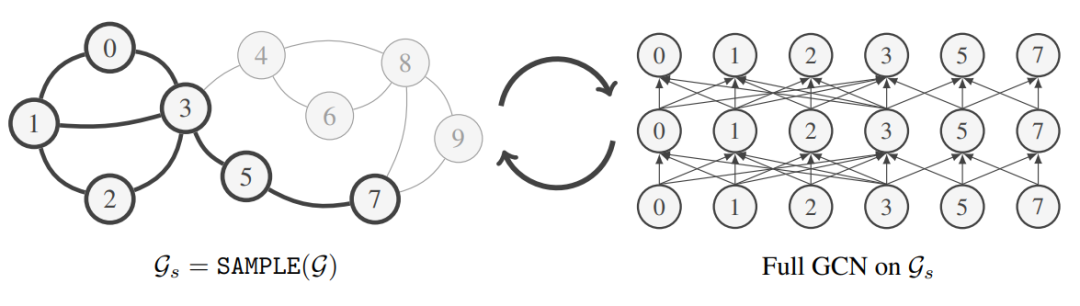
处理巨型图的一种直接方法是将它们分成更小的子图,并通过小批量梯度法下降训练 GNN(每个子图可以作为一个小批量数据)。但是,这种方法最大的问题在于:与样本独立的机器学习标准数据集不同,网络数据的关系结构会在样本之间产生统计依赖性。因此,要确保子图保留完整图的语义以及为训练 GNN 提供可靠的梯度并不是一件简单的事情。
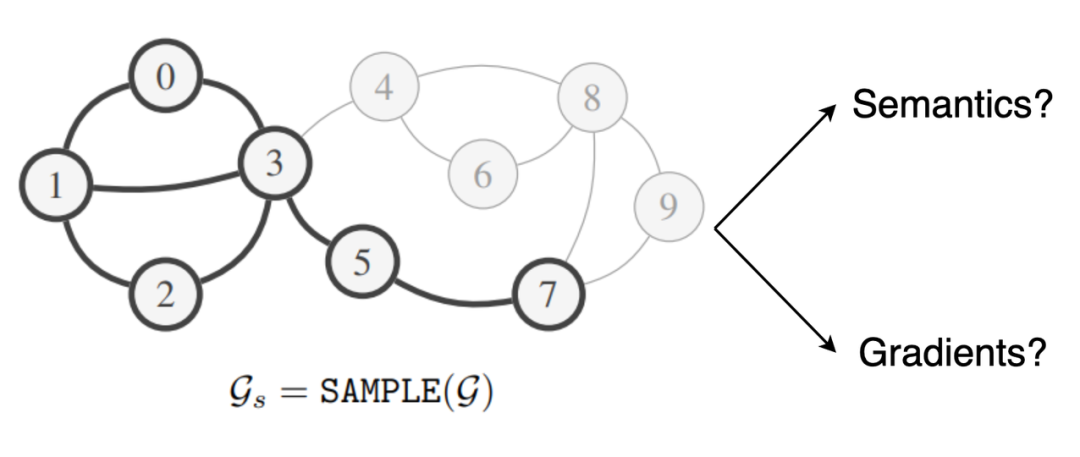 如何设计同时保留全图语义和梯度信息的采样程序?
如何设计同时保留全图语义和梯度信息的采样程序?
处理巨型图
二次采样技术
现有论文在尝试将巨型图放入 GNN 时,关注点在于图的子采样,以将大图拆分为可管理的子图。ClusterGCN 利用聚类算法将图拆分为聚类子图,并通过将每个簇作为单次的小批量数据来训练 GNN。在实践中这样做效果很好,特别是对于同质图,同质图中集群通常形成具有相似标签的有意义的集群。
 资料来源:《GraphSAINT: Graph Sampling Based Inductive Learning Method》
资料来源:《GraphSAINT: Graph Sampling Based Inductive Learning Method》
GraphSAINT 提出了一种更通用的概率图采样器来构建小批量子图。可能的采样方案包括统一节点 / 边缘采样以及随机游走采样。然而,由于上一节中强调的可靠性问题(语义和梯度信息),与在全图上训练相比,子采样方法可能会限制模型的性能。
历史节点嵌入
GNNAutoScale (GAS) 是基本子采样技术的一种很有前景的替代方案,用于将 GNN 应用到大型图。GAS 建立在 Chen 等人之前关于历史节点嵌入的工作之上,即将之前训练得到的节点嵌入,重新用于现在的训练。
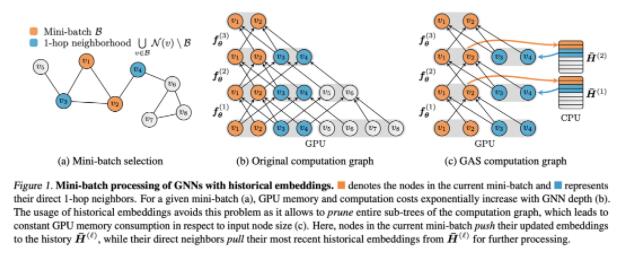
 资料来源:《GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings.》。
资料来源:《GNNAutoScale: Scalable and Expressive Graph Neural Networks via Historical Embeddings.》。
GAS 框架有两个主要组成部分:首先,第一部分是构建一个小批量节点(执行快速随机子采样)并修剪 GNN 计算图以仅保留小批量内的节点及其 1 跳邻居节点——这意味着 GAS 的尺度独立于 GNN 深度。其次,每当 GNN 聚合需要小批量节点嵌入时,GAS 就会从存储在 CPU 上的历史嵌入中检索它们。同时,当前小批量节点的历史嵌入也不断更新。
第二部分是与子采样的关键区别——能够使 GNN 最大限度地表达信息,并将当前的小批量数据和历史嵌入组合起来,得到完整的邻域信息并加以利用,同时确保对大型图的可扩展性。
GAS 的作者还将他们的想法整合到流行的 PyTorch 几何库中。于是可以在非常大的图上训练大多数的消息传递 GNN,同时降低 GPU 内存需求并保持接近全批次的性能(即在全图上训练时的性能)。
工具包中用于扩展到大型图的其他一些想法还包括:
[CVPR 2020] L2-GCN: Layer-Wise and Learned Efficient Training of Graph Convolutional Networks. Yuning You, Tianlong Chen, Zhangyang Wang, Yang Shen.
[KDD 2020] Scaling Graph Neural Networks with Approximate PageRank. Aleksandar Bojchevski, Johannes Klicpera, Bryan Perozzi, Amol Kapoor, Martin Blais, Benedek Rózemberczki, Michal Lukasik, Stephan Günnemann.
[ICLR 2021] Graph Traversal with Tensor Functionals: A Meta-Algorithm for Scalable Learning. Elan Markowitz, Keshav Balasubramanian, Mehrnoosh Mirtaheri, Sami Abu-El-Haija, Bryan Perozzi, Greg Ver Steeg, Aram Galstyan.
[NeurIPS 2021] Decoupling the Depth and Scope of Graph Neural Networks. Hanqing Zeng, Muhan Zhang, Yinglong Xia, Ajitesh Srivastava, Andrey Malevich, Rajgopal Kannan, Viktor Prasanna, Long Jin, Ren Chen.
可扩展且资源高效的 GNN 架构
图增强 MLP
在开发可扩展 GNN 的时候,一个违反直觉的想法是:只需在小批量节点上运行简单的 MLP,而不考虑图的关系结构!
Wu 等人的简化图卷积网络(SGC)是第一个提出这个想法的工作。SGC 本质上是由 Kipf 和 Welling 通过将(昂贵但非学习的)稀疏邻域特征聚合步骤与(廉价且可学习的)线性投影解耦,然后用 ReLU 非线性步骤来 “解构” 普通 GCN。在处理大型图时,可以在 CPU 上高效地预先计算特征聚合(CPU 在处理稀疏操作方面表现不错),然后可以对 “结构增强” 节点特征进行批处理并传递给在 GPU 上训练的 MLP。
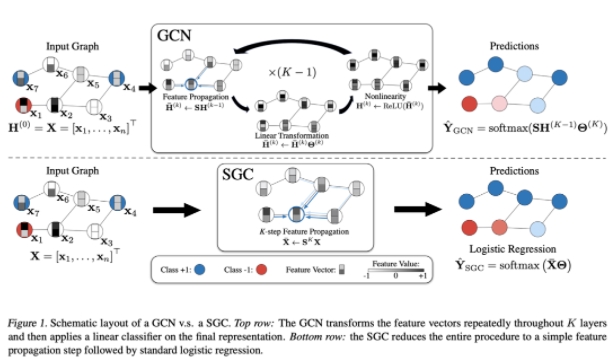
 资料来源:《Simplifying Graph Convolutional Networks》
资料来源:《Simplifying Graph Convolutional Networks》
SIGN:Rossi 等人的 Scalable Inception Graph Neural Networks 试图通过从计算机视觉的 Inception 网络中寻求灵感,并运行多个预计算步骤来为每个图节点获得更好的初始结构特征,从而将 SGC 的想法更进一步。
这一系列架构的其他有趣发展包括 Chen 等人探索结构增强 MLP 的理论局限性的工作,以及 Huang 等人的论文(该论文显示,在节点特征上运行 MLP 后类似的标签传播方法的性能优于在同质图上更繁琐的 GNN)。
高效的图卷积层
不幸的是,同质图上的节点分类之外的许多任务可能需要比 SGC/SIGN 类模型更具表现力的 GNN 架构。这通常发生在对图做分类或推理任务时,其中表现最好的 GNN 通常利用节点和边的特征。
此类模型遵循 GNN 架构设计的消息传递风格(由 Petar Veličković 推广),并且可以被认为是「各向异性的」,因为它们对每条边进行了不同的处理(而普通 GCN 是「各向同性的」,因为相同的可学习权重被应用于每条边)。然而,在每层的节点和边上维护隐空间嵌入会显著增加 GNN 的推理延迟和内存需求。
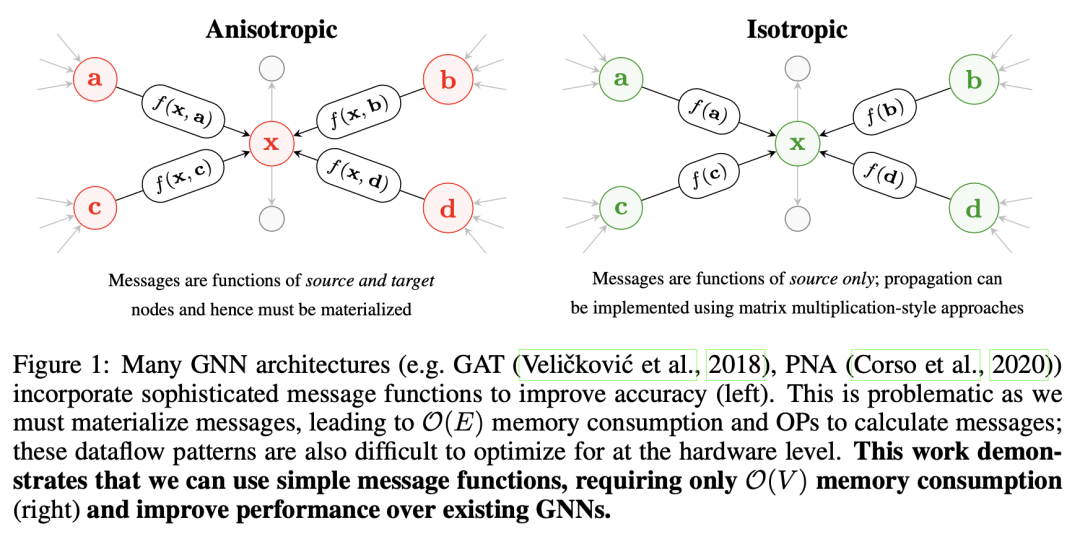 资料来源:《Do We Need Anisotropic Graph Neural Networks?》
资料来源:《Do We Need Anisotropic Graph Neural Networks?》
Tailor 等人的高效图卷积 (EGC) 试图解决这个困境。他们从基本的 GCN 设计开始(对于批量中等大小的图具有良好的可扩展性),并设计了一个最大表达的卷积 GNN 版本,同时保留了 GCN 的可扩展性。令人印象深刻的是,它们在 Open Graph Benchmark 的图分类任务中优于更复杂和繁琐的基准模型。
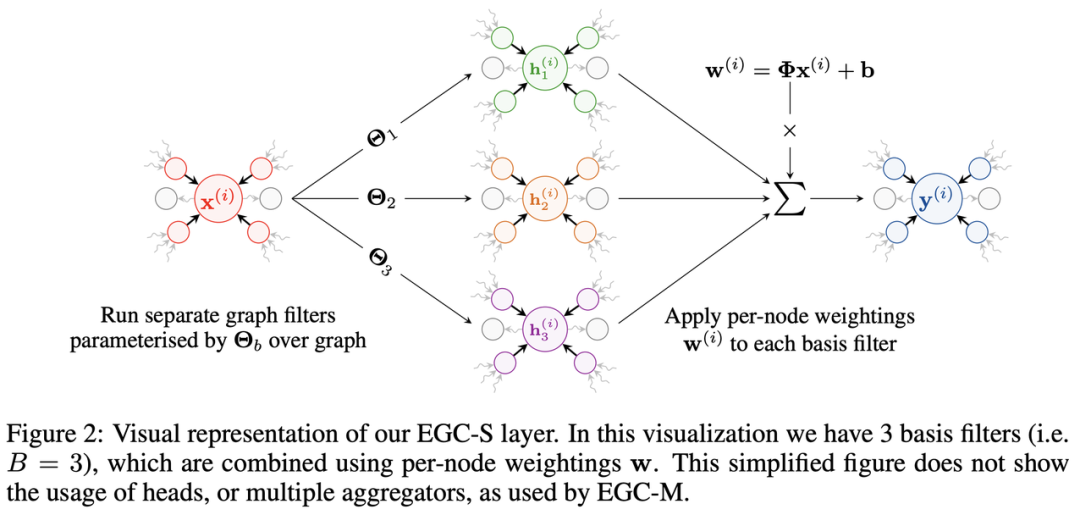 资料来源:《Do We Need Anisotropic Graph Neural Networks?》
资料来源:《Do We Need Anisotropic Graph Neural Networks?》
EGC 层也已集成到 PyTorch Geometric 中,可以作为即插即用的替代品来提高 GNN 的性能和可扩展性。
Li 等人的另一个有趣的想法是利用计算机视觉中高效的 ConvNet(可逆连接、组卷积、权重绑定和平衡模型)来提高 GNN 的内存和参数效率。他们的框架能够训练具有(前所未有的)1000 多个层的 GNN,并在 Open Graph Benchmark 的大规模节点分类任务中表现出色。
GNN 压缩的学习范式
除了数据准备技术和有效的模型架构之外,学习模式,即模型的训练方式,也可以显著提高 GNN 的性能,并且降低延迟。
知识蒸馏可以提升性能
知识蒸馏(KD)是一种通用的神经网络学习范式,它将知识从高性能但资源密集型的教师模型转移到资源高效的学生身上。KD 的概念最初是由 Hinton 等人提出的,KD 训练学生以匹配教师模型的输出 logits 以及标准的监督学习损失。
杨等人最近的工作以及随后发表的 Zhang 等人的工作,展示了这种简单的基于 logit 的 KD 理念对于开发资源高效的 GNN 的强大功能:他们将富有表现力的 GNN 训练为教师模型,并使用 KD 将知识转移给 MLP 学生,以便在节点特征和图结构高度相关的情况下更容易部署。这个想法可以扩展到上一节中的 SGC 或 SIGN 等图形增强型 MLP,图形增强型 MLP 可以显着提高类 MLP 模型的性能,同时易于在生产系统中部署。
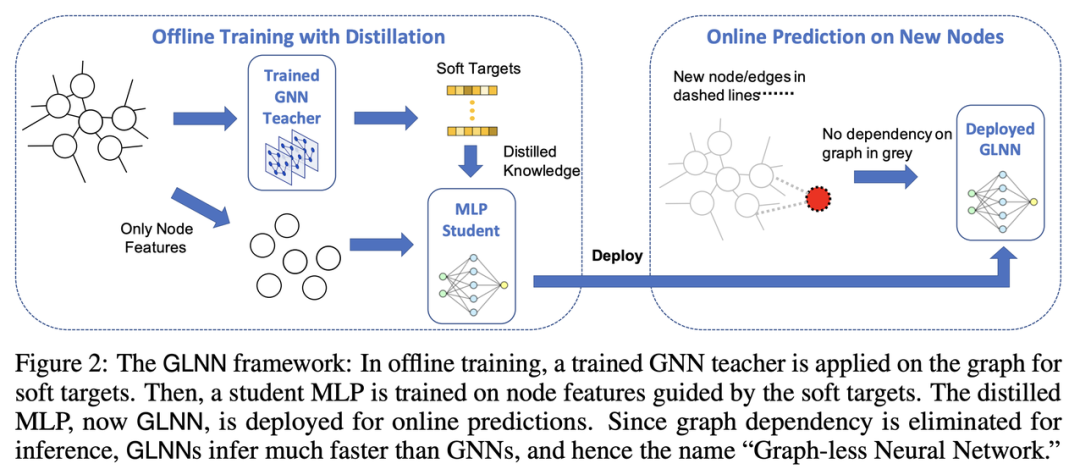 资料来源:《Graph-less Neural Networks: Teaching Old MLPs New Tricks via Distillation》
资料来源:《Graph-less Neural Networks: Teaching Old MLPs New Tricks via Distillation》
在计算机视觉中,实践者试图超越基于 logit 的 KD,通过对齐潜在嵌入空间的损失函数将表示性知识从教师转移到学生。
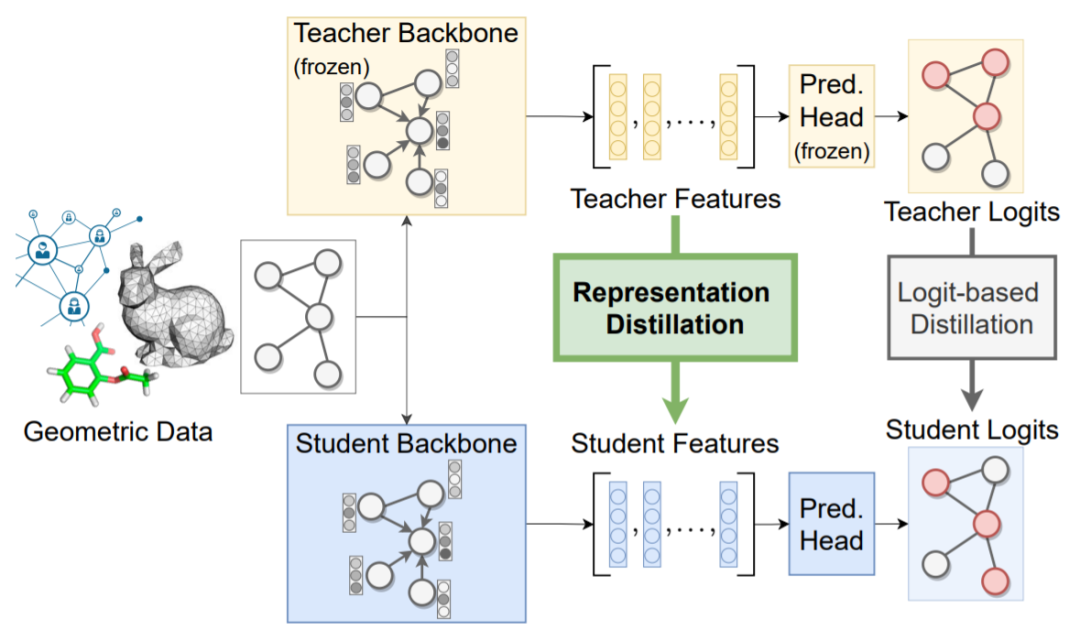 资料来源:《On Representation Knowledge Distillation for Graph Neural Networks》
资料来源:《On Representation Knowledge Distillation for Graph Neural Networks》
Yang 等人的开创性工作首先通过训练学生从教师的节点嵌入空间中保留局部拓扑结构来探索 GNN 的表示蒸馏。他们将这种方法称为局部结构保留 (LSP),因为它鼓励学生模仿教师节点嵌入空间中存在的直接邻居的成对相似性。
最近,Joshi 等人扩展了 LSP 研究,通过保留直接邻居之外的潜在相互作用来考虑全局拓扑结构。他们为 GNN 提出了两个新的表示蒸馏目标:(1)一种显式方法——全局结构保留,它扩展了 LSP 以考虑所有成对的相似性;(2) 一种隐式方法——图形对比表示蒸馏,它使用对比学习将学生节点嵌入与教师节点嵌入在共享表示空间中对齐。
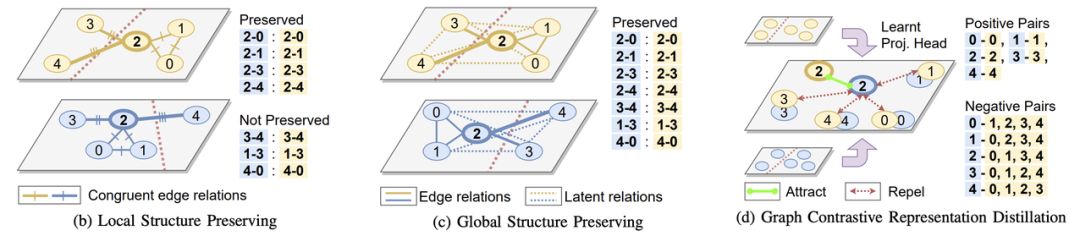 资料来源:《On Representation Knowledge Distillation for Graph Neural Networks》
资料来源:《On Representation Knowledge Distillation for Graph Neural Networks》
Joshi 等人在 Open Graph Benchmark 数据集上的实验表明,使用表示蒸馏训练轻量级 GNN 可以显著提高其实验性能以及对噪声或分布外数据的鲁棒性。
GNN 的其他一些 KD 方法包括无教师蒸馏,也称为自蒸馏,以及无数据蒸馏。
低精度的 GNN 的量化
量化感知训练(QAT)是另一种通用的神经网络学习范式。虽然传统的神经网络模型权重和激活存储为 32 位浮点数 FP32,但 QAT 训练具有较低精度、整数权重和激活的模型,例如 INT8 或 INT4。低精度模型在推理延迟方面享有显著优势,尽管以降低性能为代价。
Tailor 等人的 DegreeQuant 提出了一种专门用于 GNN 的 QAT 技术。为计算机视觉 CNN 设计的通用 QAT 在应用于 GNN 时通常会导致量化后的性能非常差。DegreeQuant 旨在通过巧妙地将基础数据的图结构整合到量化过程中来缓解这一问题:他们表明,具有许多邻居(度数较高)的节点会导致 QAT 期间的不稳定,并建议在执行 QAT 时随机屏蔽度数较高的节点。与 FP32 模型相比,这为 GNN 提供了更稳定的 QAT,并最大限度地减少了 INT8 的性能下降。
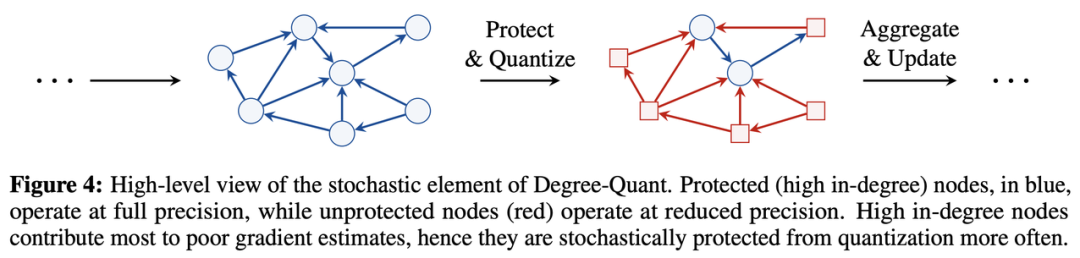
量化 GNN 的其他想法包括利用 Zhao 等人的 Neural Architecture Search 和 Bahri 等人的二值化方法(这是量化的极端情况)。一般来说,QAT 的一些性能降低可以通过知识蒸馏来恢复,如 Bahri 等人以及 Joshi 等人在上一节的 Graph Contrastive Representation Distillation 论文中所示。
结论与展望
本文重点介绍高效的图神经网络和可扩展的图表示学习。我们首先确定了现实世界 GNN 的理论和工程挑战:
- 巨型图 - 内存限制
- 稀疏计算——硬件限制
- 图二次抽样——可靠性限制
然后,我们介绍了三个关键思想,它们可能会成为开发高效且可扩展的 GNN 的工具:
1. 数据准备——通过历史节点嵌入查找,实现从对大规模图采样到 CPU-GPU 中进行混合训练。2. 高效架构——用于扩展到巨型网络的图增强 MLP,以及用于对批量图数据进行实时推理的高效图卷积设计。3. 学习范式——将量化感知训练(低精度模型权重和激活)与知识蒸馏(使用富有表现力的教师模型将 GNN 改进地更加高效)相结合,以最大限度地提高推理延迟和性能。
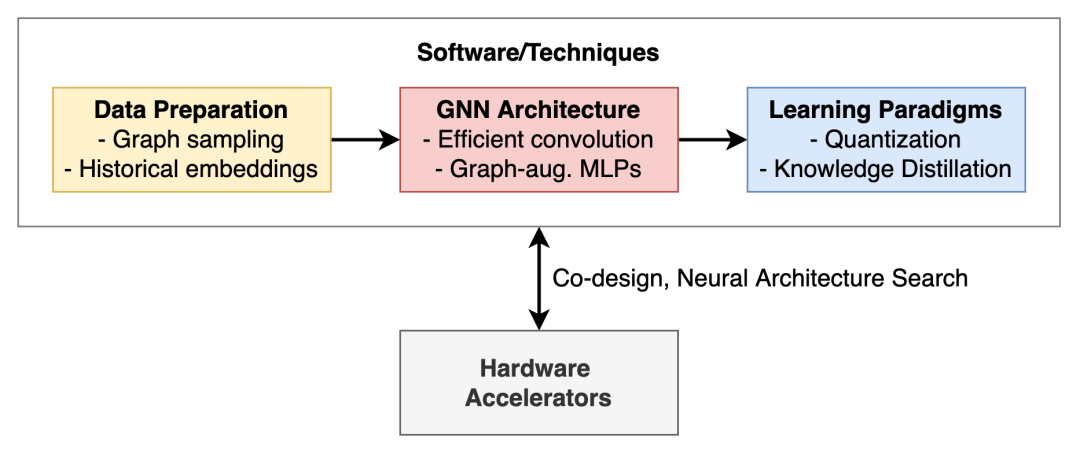 用于高效和可扩展的图形表示学习的工具箱。
用于高效和可扩展的图形表示学习的工具箱。
在不久的将来,预计研究社区将继续推进 GNN 网络的高效化、可扩展性工具箱,并可能通过直接集成的方式出现在 PyTorch Geometric 和 DGL 等 GNN 库中。我们还希望听到越来越多的 GNN 处理真实世界图和实时应用程序的成功案例。
从长远来看,我们希望图数据 + GNN 从一个深奥的新兴研究领域转变为用于机器学习研究和应用的标准数据 + 模型范式(很像 2D 图像 + CNN,或文本 + Transformers)。因此,我们可能期望看到 GNN 更深入地集成到 PyTorch 或 TensorFlow 等标准框架中,为 GNN 开发专门的硬件加速器,以及更复杂的图数据软硬件协同设计。
事实上,这些努力可能已经在从图数据和 GNN 中获得巨大商业价值的公司中进行!
如需更深入地了解本文所涵盖的主题,请参阅以下研究:
Abadal 等人的广泛调查涵盖了从 GNN 的基本原理到用于图表示学习的硬件加速器设计的所有内容(本文未涉及)。
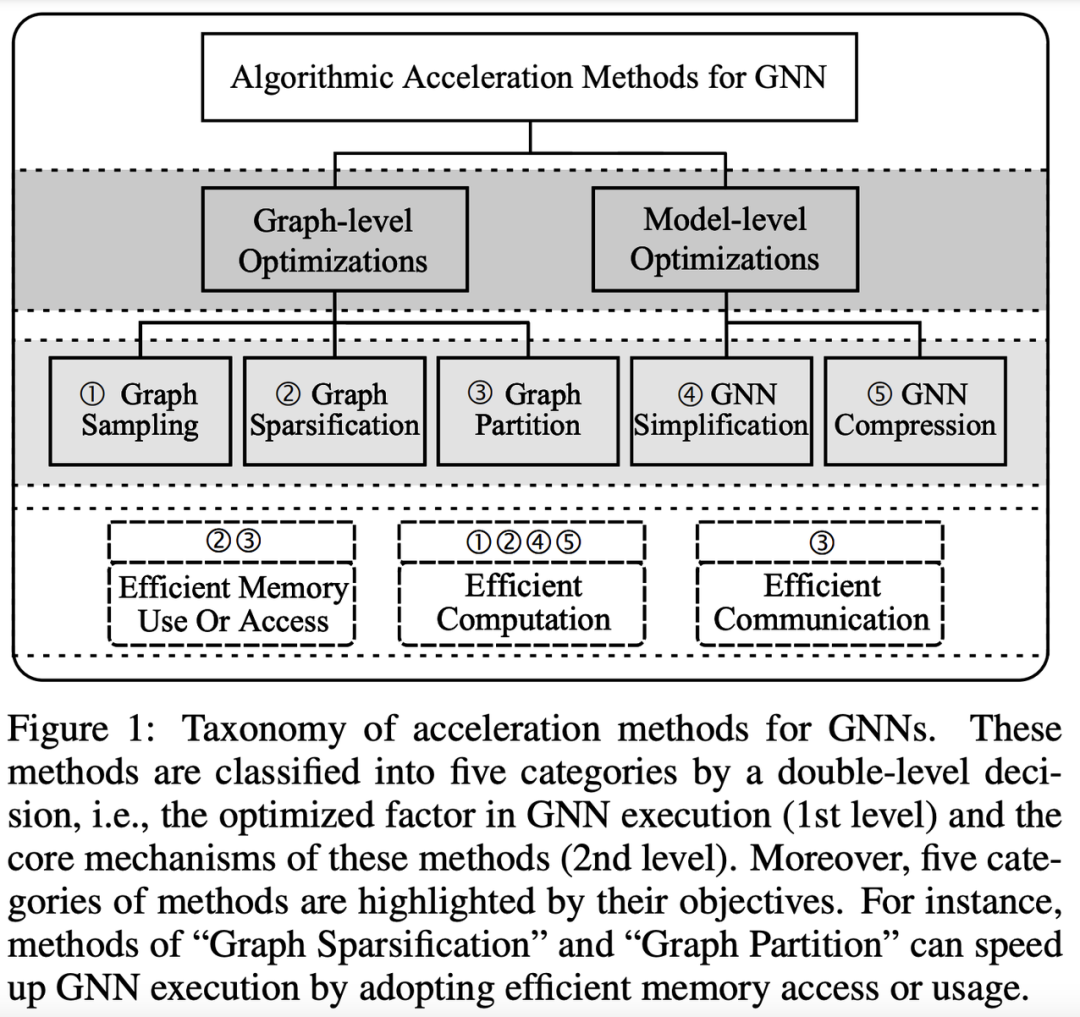 资料来源:图神经网络加速调查:算法视角。
资料来源:图神经网络加速调查:算法视角。
文中提到的论文请参考原文。





















