












LotusDB 是一个基于 LSM Tree 进行设计,并结合 B+ 树优势的单机 KV 存储引擎,读写性能稳定、快速。
在传统的 LSM Tree 架构中,增删数据均是追加有序写入到 SST 文件中,相同的 key 对应的数据可能存在多份,需要通过复杂的 compaction 策略来进行空间回收,这同时带来了空间放大和写放大问题。
LSM Tree 在磁盘上维护多级 SSTable 文件,在数据读取时,需要逐层扫描文件来查找指定的数据,最坏情况下需要扫描每一层的 SSTable,读性能不稳定。
和 LSM Tree 相对应的,另一种常见的数据存储模型是 B+ Tree,B+ 树由于有着很好的适配磁盘页的特性,在数据库存储引擎中广泛应用,例如最为人熟知的 Mysql 的 InnoDB 引擎。
B+ Tree 将数据维护在树最底层叶子节点中,读性能比较稳定,但是数据的插入和更新均是随机 IO 进行写入,导致 B+ Tree 的写性能相对较低。
我们知道,LSM 存储模型诞生于 HDD(机械硬盘) 时代,HDD 的随机和顺序读写速度差别巨大,所以 LSM 的设计最大限度的发挥了顺序 IO 的优势,所有的数据先到内存 buffer 里缓存,然后批量有序写入到文件中。但是随着存储硬件的更新迭代,磁盘的随机和顺序读写差别变小了,在一些介质中,顺序和随机读写甚至没有太大的差别。
LSM Tree 针对顺序 IO 的一些设计就会显得过于复杂,导致整个系统难以实现和控制(如果你熟悉 rocksdb 的话,就会深有体会)。
自行设计一个系统的底层存储引擎,比掌握一个复杂的项目要更加容易,出现了相关的问题也更容易定位和解决,这也是为什么 cockroach 采用自研的 Pebble 存储引擎替代 rocksdb,而 LotusDB 就是一个这样可以轻易学习和掌握的存储引擎,因为它简洁、直观且高效。
LotusDB 的整体架构图如下:
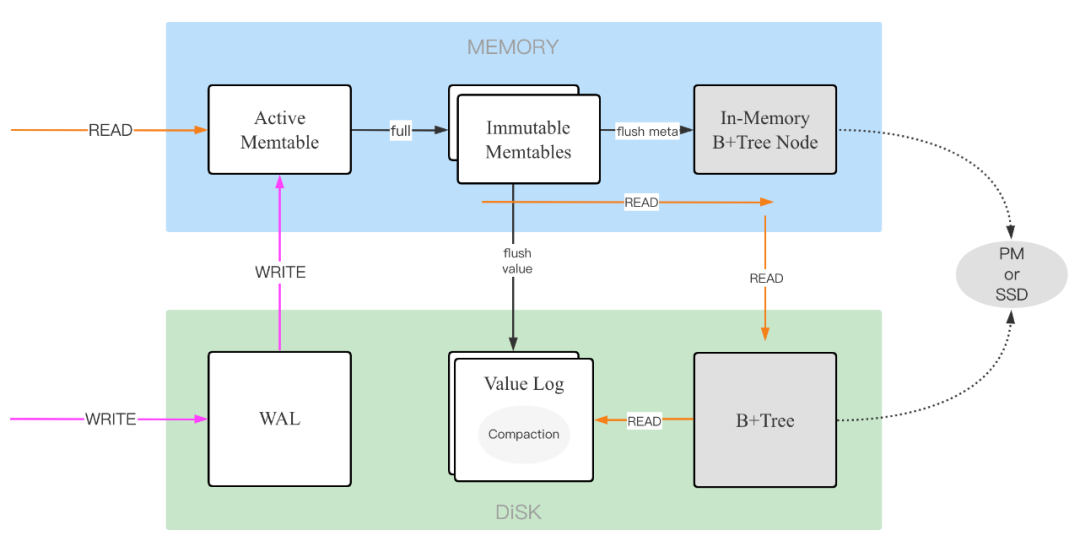
LotusDB 仍然保留了 LSM Tree 中的写流程,因为这能够最大限度的保证写入数据的持久性以及写吞吐,所以在磁盘上维护了 WAL 日志,新写入的数据先追加到 WAL 中保证数据不丢失,然后再写入到内存中。内存中维护了多个跳表结构,最新的跳表叫做 active memtable,一个 memtable 写满之后,会变为 immutable memtable,即不可变的 memtable,其不能接收新的写入,并且等待被后台线程 flush 到磁盘中。
Flush 的时候,数据索引信息会被存放到 B+ 树中,而 value 会被单独存放到 Value Log 中,value log 的结构类似于 WAL,数据写入都是采用日志追加,只不过 value log 会有一个阈值,写满之后会打开一个新的 value log,因此 value log 是存在多个的。
需要注意的是,B+ Tree 应该尽量存储新的存储介质中,例如固态硬盘,因为前面提到过 B+ 树是随机写入,如果使用传统机械硬盘的话,写性能受限制,写放大严重,Flush 可能会是一个瓶颈。
这就是 LotusDB 的整体实现,在这种实现下,我们来看看基本的数据读写流程是什么样的。
写一个 key/value:前面说过了,和 LSM 模型完全一致,先将 key/value 封装成一条日志追加到 WAL 中,然后将 k/v 写入到内存的 active memtable。
根据 key 读一个 value:先在内存当中的 active memtable 和 immutable memtable 中依次查找,如果找到直接返回。否则说明 value 可能在磁盘中,就从 B+ 树获取 key 的索引信息,索引信息是一个二元组 ,标识 value 位于 value log 中具体哪个文件,以及文件中的位置,然后直接根据这个索引信息到 value log 文件中获取 value 即可。
最后再来总结下 LotusDB 架构的优点,简单归纳大概有如下几点:
1.写数据流程和传统 LSM 模型完全一致,保证了顺序 IO 的高吞吐,以及数据持久性
2.读性能相较于原生 LSM 模型更加稳定,读放大降低,因为引入了 B+ 树,得益于 B+ 树稳定的读性能,整体的读取效率会更加可控
3.完全去除了 LSM Tree 模型中的多级 SSTable,没有了 SSTable 的维护,并且采用已有的 B+ 树实现(BoltDB),大大降低了系统的复杂性
4.Compaction 对存储介质的损耗降低,LotusDB 中只有 value log 存在 Compaction;原生 LSM 不仅 SSTable 需要 Compaction,并且如果进行了 kv 分离的话,value log 也同样需要 Compaction
5.读写流程简洁直观,没有 bloom filter、block cache 等
LotusDB Github 地址:https://github.com/flower-corp/lotusdb















