1.前言
本篇文章开始Disruptor的源码分析,理解起来相对比较困难,特别是Disruptor的sequenceBarrier的理解,sequenceBarrier包括生产者与消费者之间的gatingSequence以及消费者与消费者之间的dependentSequence。此外,Disruptor源码中的sequence变量也比较多,需要捋清楚各种sequence的含义。最后,建议小伙伴们动手调试理解,效果会更好。
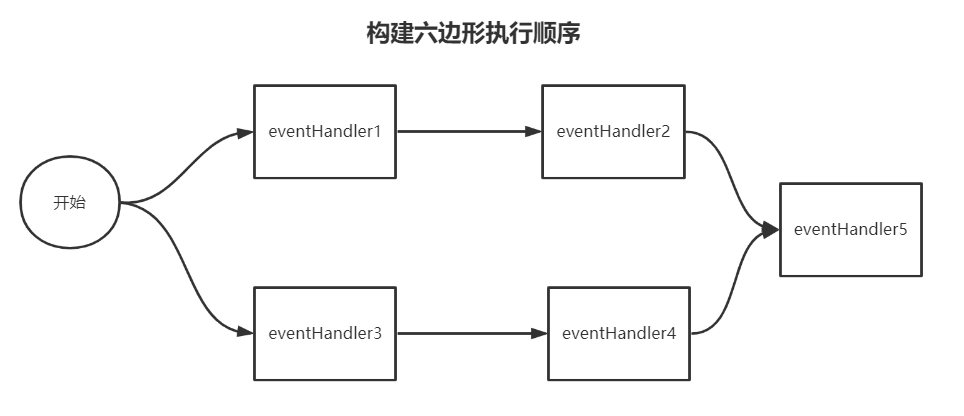
2.Disruptor六边形DEMO
分析源码前,先来看看Disruptor六边形执行器链的DEMO。
public class LongEventMain
{
private static final int BUFFER_SIZE = 1024;
public static void main(String[] args) throws Exception
{
// 1,构建disruptor
final Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(
new LongEventFactory(),
BUFFER_SIZE,
Executors.newFixedThreadPool(5), // 【注意点】线程池需要保证足够的线程:有多少个消费者就要有多少个线程,否则有些消费者将不会执行,生产者可能也会一直阻塞下去
ProducerType.SINGLE,
new YieldingWaitStrategy()
);
EventHandler eventHandler1 = new LongEventHandler1();
EventHandler eventHandler2 = new LongEventHandler2();
EventHandler eventHandler3 = new LongEventHandler3();
EventHandler eventHandler4 = new LongEventHandler4();
EventHandler eventHandler5 = new LongEventHandler5();
// 方式1 构建串行执行顺序:
/*disruptor
.handleEventsWith(eventHandler1)
.handleEventsWith(eventHandler2)
.handleEventsWith(eventHandler3)
.handleEventsWith(eventHandler4)
.handleEventsWith(eventHandler5);*/
// 方式2 构建并行执行顺序
/*disruptor
.handleEventsWith(eventHandler1, eventHandler2, eventHandler3, eventHandler4, eventHandler5);*/
// 方式3 构建菱形执行顺序
/*disruptor.handleEventsWith(eventHandler1, eventHandler2)
.handleEventsWith(eventHandler3);*/
// 2,构建eventHandler执行链
// 方式4 构建六边形执行顺序
disruptor.handleEventsWith(eventHandler1, eventHandler3);
disruptor.after(eventHandler1).handleEventsWith(eventHandler2);
disruptor.after(eventHandler3).handleEventsWith(eventHandler4);
disruptor.after(eventHandler2, eventHandler4).handleEventsWith(eventHandler5);
// 3, 启动disruptor即启动线程池线程执行BatchEventProcessor任务
disruptor.start();
// 4,生产者往ringBuffer生产数据并唤醒所有的消费者消费数据
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
ByteBuffer bb = ByteBuffer.allocate(8);
bb.putLong(0, 666);
ringBuffer.publishEvent(new LongEventTranslatorOneArg(), bb);
}
static class LongEventTranslatorOneArg implements EventTranslatorOneArg<LongEvent, ByteBuffer> {
@Override
public void translateTo(LongEvent event, long sequence, ByteBuffer buffer) {
event.set(buffer.getLong(0));
}
}
static class LongEvent
{
private long value;
public void set(long value)
{
this.value = value;
}
public long get() {
return this.value;
}
}
static class LongEventFactory implements EventFactory<LongEvent>
{
@Override
public LongEvent newInstance()
{
return new LongEvent();
}
}
static class LongEventHandler1 implements EventHandler<LongEvent>
{
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("LongEventHandler1-" + event.get() + " executed by " + Thread.currentThread().getName());
}
}
static class LongEventHandler2 implements EventHandler<LongEvent>
{
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("LongEventHandler2-" + event.get() + " executed by " + Thread.currentThread().getName());
}
}
static class LongEventHandler3 implements EventHandler<LongEvent>
{
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("LongEventHandler3-" + event.get() + " executed by " + Thread.currentThread().getName());
}
}
static class LongEventHandler4 implements EventHandler<LongEvent>
{
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("LongEventHandler4-" + event.get() + " executed by " + Thread.currentThread().getName());
}
}
static class LongEventHandler5 implements EventHandler<LongEvent>
{
@Override
public void onEvent(LongEvent event, long sequence, boolean endOfBatch)
{
System.out.println("LongEventHandler5-" + event.get() + " executed by " + Thread.currentThread().getName());
}
}
}
3.初始化Disruptor实例
先来看下前面DEMO中的初始化Disruptor实例代码:
// 1,构建disruptor
final Disruptor<LongEvent> disruptor = new Disruptor<LongEvent>(
new LongEventFactory(),
BUFFER_SIZE,
Executors.newFixedThreadPool(5), // 线程池需要保证足够的线程
ProducerType.SINGLE,
new YieldingWaitStrategy()
);
这句代码最终是给Disruptor的ringBuffer和executor属性赋值:
// Disruptor.java
public Disruptor(
final EventFactory<T> eventFactory,
final int ringBufferSize,
final Executor executor,
final ProducerType producerType,
final WaitStrategy waitStrategy)
{
this(
// 创建RingBuffer实例
RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy),
executor);
}
private Disruptor(final RingBuffer<T> ringBuffer, final Executor executor)
{
this.ringBuffer = ringBuffer;
this.executor = executor;
}
那么RingBuffer实例又是如何创建的呢?我们来看下RingBuffer.create(producerType, eventFactory, ringBufferSize, waitStrategy)这句源码:
// RingBuffer.java
public static <E> RingBuffer<E> create(
final ProducerType producerType,
final EventFactory<E> factory,
final int bufferSize,
final WaitStrategy waitStrategy)
{
switch (producerType)
{
case SINGLE:
return createSingleProducer(factory, bufferSize, waitStrategy);
case MULTI:
return createMultiProducer(factory, bufferSize, waitStrategy);
default:
throw new IllegalStateException(producerType.toString());
}
}
首先会根据producerType来创建不同的Producer,以创建SingleProducerSequencer实例为例进去源码看下:
// RingBuffer.java
public static <E> RingBuffer<E> createSingleProducer(
final EventFactory<E> factory,
final int bufferSize,
final WaitStrategy waitStrategy)
{
// 1,创建SingleProducerSequencer实例
SingleProducerSequencer sequencer = new SingleProducerSequencer(bufferSize, waitStrategy);
// 2,创建RingBuffer实例
return new RingBuffer<>(factory, sequencer);
}
3.1 创建SingleProducerSequencer实例
首先创建了SingleProducerSequencer实例,给SingleProducerSequencer实例的bufferSize和waitStrategy赋初值;
// AbstractSequencer.java
// SingleProducerSequencer父类
public AbstractSequencer(int bufferSize, WaitStrategy waitStrategy)
{
this.bufferSize = bufferSize;
this.waitStrategy = waitStrategy;
}
此外,创建SingleProducerSequencer实例时还初始化了一个成员变量cursor:
protected final Sequence cursor = new Sequence(Sequencer.INITIAL_CURSOR_VALUE);
即给cursor赋值了一个Sequence实例对象,Sequence是标识RingBuffer环形数组的下标,同时生产者和消费者也会同时维护各自的Sequence。最重要的是,**Sequence通过填充CPU缓存行避免了伪共享带来的性能损耗**,来看下其填充缓存行源码:
// Sequence.java
class LhsPadding
{
// 左填充
protected long p1, p2, p3, p4, p5, p6, p7;
}
class Value extends LhsPadding
{
// Sequence值
protected volatile long value;
}
class RhsPadding extends Value
{
// 右填充
protected long p9, p10, p11, p12, p13, p14, p15;
}
public class Sequence extends RhsPadding
{
// ...
}
3.2 创建RingBuffer实例
然后核心是创建RingBuffer实例,看看最终创建RingBuffer实例源码:
// RingBuffer.java
RingBufferFields( // RingBufferFields为RingBuffer父类
final EventFactory<E> eventFactory,
final Sequencer sequencer)
{
this.sequencer = sequencer;
this.bufferSize = sequencer.getBufferSize();
if (bufferSize < 1)
{
throw new IllegalArgumentException("bufferSize must not be less than 1");
}
if (Integer.bitCount(bufferSize) != 1)
{
throw new IllegalArgumentException("bufferSize must be a power of 2");
}
this.indexMask = bufferSize - 1;
// 【重要特性】内存预加载,内存池机制
this.entries = (E[]) new Object[sequencer.getBufferSize() + 2 * BUFFER_PAD];
fill(eventFactory);
}
实例作为构造参数传入给了RingBuffer实例的sequencer属性赋初值,然后最重要的是在创建RingBuffer实例时,会为RingBuffer的环形数组提前填充Event对象,即内存池机制:
private void fill(final EventFactory<E> eventFactory)
{
for (int i = 0; i < bufferSize; i++)
{
entries[BUFFER_PAD + i] = eventFactory.newInstance();
}
}
内存池机制好处:
- 提前创建好复用的对象,减少程序运行时因为创建对象而浪费性能,其实也是一种空间换时间的思想;
- 因为环形数组对象可复用,从而避免GC来提高性能。
4.构建执行顺序链
// 2,构建eventHandler执行链:构建六边形执行顺序
disruptor.handleEventsWith(eventHandler1, eventHandler3);
disruptor.after(eventHandler1).handleEventsWith(eventHandler2);
disruptor.after(eventHandler3).handleEventsWith(eventHandler4);
disruptor.after(eventHandler2, eventHandler4).handleEventsWith(eventHandler5);
再来看看Disruptor构建执行顺序链相关源码:
先来看看disruptor.handleEventsWith(eventHandler1, eventHandler3);源码:
// Disruptor.java
public final EventHandlerGroup<T> handleEventsWith(final EventHandler<? super T>... handlers)
{
return createEventProcessors(new Sequence[0], handlers);
}
EventHandlerGroup<T> createEventProcessors(
final Sequence[] barrierSequences,
final EventHandler<? super T>[] eventHandlers)
{
checkNotStarted();
// 根据eventHandlers长度来创建多少个消费者Sequence实例,注意这个processorSequences是传递到EventHandlerGroup用于构建执行顺序链用的,
// 比如有执行顺序链:A->B,那么A的sequenct即processorSequences会作为B节点的barrierSequences即dependencySequence
final Sequence[] processorSequences = new Sequence[eventHandlers.length];
// 新建了一个ProcessingSequenceBarrier实例返回
// ProcessingSequenceBarrier实例作用:序号屏障,通过追踪生产者的cursorSequence和每个消费者( EventProcessor)
// 的sequence的方式来协调生产者和消费者之间的数据交换进度
final SequenceBarrier barrier = ringBuffer.newBarrier(barrierSequences);// 如果构建执行顺序链比如A->B,那么barrierSequences是A消费者的sequence;如果是A,C->B,那么barrierSequences是A和C消费者的sequence
for (int i = 0, eventHandlersLength = eventHandlers.length; i < eventHandlersLength; i++)
{
final EventHandler<? super T> eventHandler = eventHandlers[i];
// 有多少个eventHandlers就创建多少个BatchEventProcessor实例(消费者),
// 但需要注意的是同一批次的每个BatchEventProcessor实例共用同一个SequenceBarrier实例
final BatchEventProcessor<T> batchEventProcessor =
new BatchEventProcessor<>(ringBuffer, barrier, eventHandler);
if (exceptionHandler != null)
{
batchEventProcessor.setExceptionHandler(exceptionHandler);
}
// 将batchEventProcessor, eventHandler, barrier封装成EventProcessorInfo实例并加入到ConsumerRepository相关集合
// ConsumerRepository作用:提供存储机制关联EventHandlers和EventProcessors
consumerRepository.add(batchEventProcessor, eventHandler, barrier); // // 如果构建执行顺序链比如A->B,那么B消费者也一样会加入consumerRepository的相关集合
// 获取到每个消费的消费sequece并赋值给processorSequences数组
// 即processorSequences[i]引用了BatchEventProcessor的sequence实例,
// 但processorSequences[i]又是构建生产者gatingSequence和消费者执行器链dependentSequence的来源
processorSequences[i] = batchEventProcessor.getSequence();
}
// 总是拿执行器链最后一个消费者的sequence作为生产者的gateingSequence
updateGatingSequencesForNextInChain(barrierSequences, processorSequences);
// 最终返回封装了Disruptor、ConsumerRepository和消费者sequence数组processorSequences的EventHandlerGroup对象实例返回
return new EventHandlerGroup<>(this, consumerRepository, processorSequences);
}
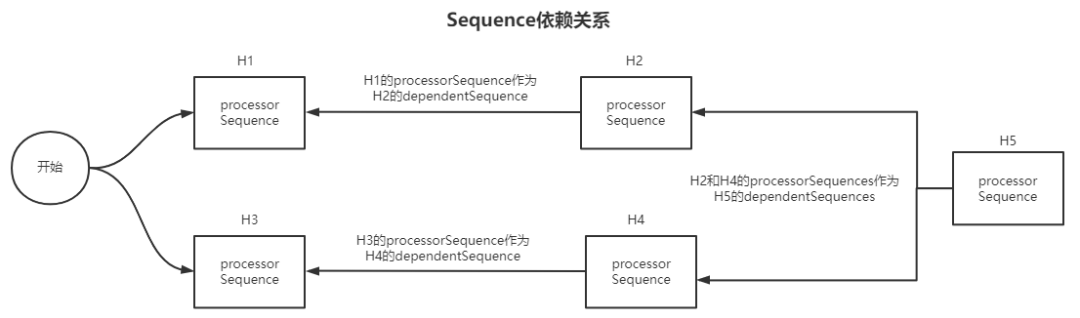
构建Disruptor执行顺序链的核心逻辑就在这段源码中,我们缕一缕核心逻辑:
- 有多少个eventHandlers就创建多少个BatchEventProcessor实例(消费者),BatchEventProcessor消费者其实就是一个实现Runnable接口的线程实例;
- 每个BatchEventProcessor实例(消费者)拥有前一个消费者的sequence作为其sequenceBarrier即dependentSequence;
- 当前消费者的sequence通过EventHandlerGroup这个载体来传递给下一个消费者作为其sequenceBarrier即dependentSequence。
再来看看diruptor.after(eventHandler1)源码:
// Disruptor.java
public final EventHandlerGroup<T> after(final EventHandler<T>... handlers)
{
// 获取指定的EventHandler的消费者sequence并赋值给sequences数组,
// 然后重新新建一个EventHandlerGroup实例返回(封装了前面的指定的消费者sequence被赋值
// 给了EventHandlerGroup的成员变量数组sequences,用于后面指定执行顺序用)
final Sequence[] sequences = new Sequence[handlers.length];
for (int i = 0, handlersLength = handlers.length; i < handlersLength; i++)
{
sequences[i] = consumerRepository.getSequenceFor(handlers[i]);
}
return new EventHandlerGroup<>(this, consumerRepository, sequences);
}
这段源码做的事情也是将当前消费者sequence封装进EventHandlerGroup,从而可以通过这个载体来传递给下一个消费者作为其sequenceBarrier即dependentSequence。
最终构建的最终sequence依赖关系如下图,看到这个图不禁让我想起AQS的线程等待链即CLH锁的变相实现,附上文章链接,有兴趣的读者可以比对理解。
5.启动Disruptor实例
// 3, 启动disruptor即启动线程池线程执行BatchEventProcessor任务
disruptor.start();
我们再来看看 disruptor.start()这句源码:
// Disruptor.java
public RingBuffer<T> start()
{
checkOnlyStartedOnce();
// 遍历每一个BatchEventProcessor消费者(线程)实例,并把该消费者线程实例跑起来
for (final ConsumerInfo consumerInfo : consumerRepository)
{
consumerInfo.start(executor);
}
return ringBuffer;
}
其实这里做的事情无非就是遍历每个消费者线程实例,然后启动每个消费者线程实例BatchEventProcessor,其中BatchEventProcessor被封装进ConsumerInfo实例。还没生产数据就启动消费线程的话,此时消费者会根据阻塞策略WaitStrategy进行阻塞。
6.生产消费数据
6.1 生产者生产数据
// 4,生产者往ringBuffer生产数据并唤醒所有的消费者消费数据
RingBuffer<LongEvent> ringBuffer = disruptor.getRingBuffer();
ByteBuffer bb = ByteBuffer.allocate(8);
bb.putLong(0, 666);
ringBuffer.publishEvent(new LongEventTranslatorOneArg(), bb);
生产者生产数据的源码在ringBuffer.publishEvent(new LongEventTranslatorOneArg(), bb);中。
// RingBuffer.java
public <A> void publishEvent(final EventTranslatorOneArg<E, A> translator, final A arg0)
{
// 【1】获取下一个RingBuffer中需填充数据的event对象的序号,对应生产者
final long sequence = sequencer.next();
// 【2】转换数据格式并生产数据并唤醒消费者
translateAndPublish(translator, sequence, arg0);
}
6.1.1 生产者获取RingBuffer的sequence
先来看下单生产者获取sequence的源码:
// SingleProducerSequencer.java
public long next(final int n)
{
if (n < 1 || n > bufferSize)
{
throw new IllegalArgumentException("n must be > 0 and < bufferSize");
}
// 总是拿到生产者已生产的当前序号
long nextValue = this.nextValue;
// 获取要生产的下n个序号
long nextSequence = nextValue + n;
// 生产者总是先有bufferSize个坑可以填,所以nextSequence - bufferSize
long wrapPoint = nextSequence - bufferSize;
// 拿到上一次的GatingSequence,因为是缓存,这里不是最新的
long cachedGatingSequence = this.cachedValue;
// 如果生产者生产超过了消费者消费速度,那么这里自旋等待,这里的生产者生产的下标wrapPoint是已经绕了RingBuffer一圈的了哈
if (wrapPoint > cachedGatingSequence || cachedGatingSequence > nextValue)
{
cursor.setVolatile(nextValue); // StoreLoad fence
long minSequence;
// 自旋等待,其中gatingSequences是前面构建执行顺序链时的最后一个消费者的sequence
while (wrapPoint > (minSequence = Util.getMinimumSequence(gatingSequences, nextValue)))
{
LockSupport.parkNanos(1L); // TODO: Use waitStrategy to spin?
}
this.cachedValue = minSequence;
}
// 将获取的nextSequence赋值给生产者当前值nextValue
this.nextValue = nextSequence;
return nextSequence;
}
这段源码相对较难,我们缕一缕:
- 生产者把第一圈RingBuffer的坑填完后,此时生产者进入RingBuffer第2圈,如果消费者消费速度过慢,此时生产者很可能会追上消费者,如果追上消费者那么就让生产者自旋等待;
- 第1点的如果消费者消费速度过慢,对于构建了一个过滤器链的消费者中,那么指的是哪个消费者呢?指的就是执行器链最后执行的那个消费者gatingSequences就是执行器链最后执行的那个消费者的sequence;这个gatingSequences其实就是防止生产者追赶消费者的sequenceBarrier;
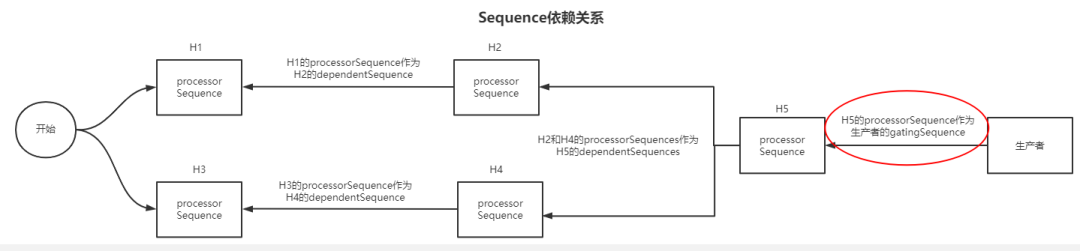
- 生产者总是先把第一圈RingBuffer填满后,才会考虑追赶消费者的问题,因此才有wrapPoint > cachedGatingSequence的评判条件。
前面是单生产者获取sequence的源码,对于多生产者MultiProducerSequencer的源码逻辑也是类似,只不过将生产者当前值cursor和cachedGatingSequence用了CAS操作而已,防止多线程问题。
6.1.2 生产者生产数据并唤醒消费者
再来看看 translateAndPublish(translator, sequence, arg0)源码:
// RingBuffer.java
private <A> void translateAndPublish(final EventTranslatorOneArg<E, A> translator, final long sequence, final A arg0)
{
try
{
// 【1】将相应数据arg0转换为相应的Eevent数据,其中get(sequence)会从RingBuffer数组对象池中取出一个对象,而非新建
translator.translateTo(get(sequence), sequence, arg0);
}
finally
{
// 【2】发布该序号说明已经生产完毕供消费者使用
sequencer.publish(sequence);
}
}
// SingleProducerSequencer.java
public void publish(final long sequence)
{
// 【1】给生产者cursor游标赋值新的sequence,说明该sequenc对应的对象数据已经填充(生产)完毕
cursor.set(sequence);// 这个cursor即生产者生产时移动的游标,是AbstractSequencer的成员变量
// 【2】根据阻塞策略将所有消费者唤醒
// 注意:这个waitStrategy实例是所有消费者和生产者共同引用的
waitStrategy.signalAllWhenBlocking();
}
生产者生产数据并唤醒消费者的注释已经写得很清楚了,这里需要注意的点:
- cursor才是生产者生产数据的当前下标,消费者消费速度有无追赶上生产者就是拿消费者的消费sequence跟生产者的cursor比较的,因此生产者生产数据完成后需要给cursor赋值;
- waitStrategy策略对象时跟消费者共用的,这样才能线程间实现阻塞唤醒逻辑。
6.2 消费者消费数据
前面第4节启动Disruptor实例中讲到,其实就是开启各个消费者实例BatchEventProcessor线程,我们看看其run方法中的核心逻辑即processEvents源码:
// BatchEventProcessor.java
private void processEvents()
{
T event = null;
// nextSequence:消费者要消费的下一个序号
long nextSequence = sequence.get() + 1L; // 【重要】每一个消费者都是从0开始消费,各个消费者维护各自的sequence
// 消费者线程一直在while循环中不断获取生产者数据
while (true)
{
try
{
// 拿到当前生产者的生产序号
final long availableSequence = sequenceBarrier.waitFor(nextSequence);
if (batchStartAware != null)
{
batchStartAware.onBatchStart(availableSequence - nextSequence + 1);
}
// 如果消费者要消费的下一个序号小于生产者的当前生产序号,那么消费者则进行消费
// 这里有一个亮点:就是消费者会一直循环消费直至到达当前生产者生产的序号
while (nextSequence <= availableSequence)
{
event = dataProvider.get(nextSequence);
eventHandler.onEvent(event, nextSequence, nextSequence == availableSequence);
nextSequence++;
}
// 消费完后设置当前消费者的消费进度,这点很重要
// 【1】如果当前消费者是执行链的最后一个消费者,那么其sequence则是生产者的gatingSequence,因为生产者就是拿要生产的下一个sequence跟gatingSequence做比较的哈
// 【2】如果当前消费者不是执行器链的最后一个消费者,那么其sequence作为后面消费者的dependentSequence
sequence.set(availableSequence);
}
catch (final TimeoutException e)
{
notifyTimeout(sequence.get());
}
catch (final AlertException ex)
{
if (running.get() != RUNNING)
{
break;
}
}
catch (final Throwable ex)
{
handleEventException(ex, nextSequence, event);
sequence.set(nextSequence);
nextSequence++;
}
}
}
消费者线程起来后,然后进入死循环,持续不断从生产者处批量获取可用的序号,如果获取到可用序号后,那么遍历所有可用序号,然后调用eventHandler的onEvent方法消费数据,onEvent方法写的是消费者的业务逻辑。消费完后再设置当前消费者的消费进度,这点很重要,用于构建sequenceBarrier包括gatingSequence和dependentSequence。
下面再来看看消费者是怎么获取可用的序号的,继续看sequenceBarrier.waitFor(nextSequence)源码:
// ProcessingSequenceBarrier.java
public long waitFor(final long sequence)
throws AlertException, InterruptedException, TimeoutException
{
checkAlert();
// availableSequence:获取生产者生产后可用的序号
// sequence:消费者要消费的下一个序号
// cursorSequence:生产者生产数据时的当前序号
// dependentSequence:第一个消费者即前面不依赖任何消费者的消费者,dependentSequence就是生产者游标;
// 有依赖其他消费者的消费者,dependentSequence就是依赖的消费者的sequence
long availableSequence = waitStrategy.waitFor(sequence, cursorSequence, dependentSequence, this);
if (availableSequence < sequence)
{
return availableSequence;
}
// 这个主要是针对多生产者的情形
return sequencer.getHighestPublishedSequence(sequence, availableSequence);
}
可以看到ProcessingSequenceBarrier封装了WaitStrategy等待策略实例,此时消费者获取下一批可用序号的逻辑又封装在了WaitStrategy的waitFor方法中,以BlockingWaitStrategy为例来其实现逻辑:
// BlockingWaitStrategy.java
public long waitFor(long sequence, Sequence cursorSequence, Sequence dependentSequence, SequenceBarrier barrier)
throws AlertException, InterruptedException
{
long availableSequence;
// cursorSequence:生产者的序号
// 第一重条件判断:如果消费者消费速度大于生产者生产速度(即消费者要消费的下一个数据已经大于生产者生产的数据时),那么消费者等待一下
if (cursorSequence.get() < sequence)
{
lock.lock();
try
{
while (cursorSequence.get() < sequence)
{
barrier.checkAlert();
processorNotifyCondition.await();
}
}
finally
{
lock.unlock();
}
}
// 第一重条件判断:自旋等待
// 即当前消费者线程要消费的下一个sequence大于其前面执行链路(若有依赖关系)的任何一个消费者最小sequence(dependentSequence.get()),那么这个消费者要自旋等待,
// 直到前面执行链路(若有依赖关系)的任何一个消费者最小sequence(dependentSequence.get())已经大于等于当前消费者的sequence时,说明前面执行链路的消费者已经消费完了
while ((availableSequence = dependentSequence.get()) < sequence)
{
barrier.checkAlert();
ThreadHints.onSpinWait();
}
return availableSequence;
}
可以看到,消费者获取下一批可用消费序号时,此时要经过两重判断:
- 第一重判断:消费者消费的序号不能超过当前生产者消费当前生产的序号,否则消费者就阻塞等待;当然,这里因为是BlockingWaitStrategy等待策略的实现,如果是其他策略,比如BusySpinWaitStrategy和YieldingWaitStrategy的话,这里消费者是不会阻塞等待的,而是自旋,因此这也是其无锁化的实现了,但就是很耗CPU而已;
- 第二重判断:消费者消费的序号不能超过其前面依赖的消费消费的序号,否则其自旋等待。因为这里是消费者等消费者,按理说前面消费者应该会很快处理完,所以不用阻塞等待;但是消费者等待生产者的话,如果生产者没生产数据的话,消费者还是自旋等待的话会比较浪费CPU,所以对于BlockingWaitStrategy策略,是阻塞等待了。
7.WaitStrategy等待策略
最后,再来看下WaitStrategy有哪些实现类:
可以看到消费者的WaitStrategy等待策略有8种实现类,可以分为有锁和无锁两大类,然后每一种都有其适用的场合,没有最好的WaitStrategy等待策略,只有适合自己应用场景的等待策略。因为其源码不是很难,这里逐一分析。