作者 |倪泽
RocketMQ-Streams 是一款轻量级流处理引擎,应用以SDK 的形式嵌入并启动,即可进行流处理计算,不依赖于其他组件,最低1核1G可部署,在资源敏感场景具有很大优势。同时它支持 UTF/UTAF/UTDF 多种计算类型。目前已经广泛运用于安全,风控,边缘计算等场景。
本期将带领大家从源码的角度,解析RocketMQ-Streams的构建,数据流转过程。也会讨论RocketMQ-Streams是如何实现故障恢复和扩缩容的。
一、使用示例
代码示例:
public class RocketMQWindowExample {
public static void main(String[] args) {
DataStreamSource source = StreamBuilder.dataStream("namespace", "pipeline");
source.fromRocketmq(
"topicName",
"groupName",
false,
"namesrvAddr")
.map(message -> JSONObject.parseObject((String) message))
.window(TumblingWindow.of(Time.seconds(10)))
.groupBy("groupByKey")
.sum("字段名", "输出别名")
.count("total")
.waterMark(5)
.setLocalStorageOnly(true)
.toDataSteam()
.toPrint(1)
.start();
}
}pom文件依赖:
<dependency>
<groupId>org.apache.rocketmq</groupId>
<artifactId>rocketmq-streams-clients</artifactId>
<version>1.0.1-preview</version>
</dependency>
上述代码是一个简单的使用例子,它主要的功能是从RocketMQ中指定topic读取数据,经过转化成JSON格式,以groupByKey字段值分组、10秒一个窗口,对OutFlow字段值进行累加,结果输出到total字段,并打印到控制台上。上述计算中还允许输入乱序5秒,即窗口时间到达后不会马上触发,而是会等待5s,如果这个段时间内,有窗口数据到达依然有效。上述setLocalStorageOnly为true表示不对状态进行远程存储,仅使用RocksDB做本地存储。目前1.0.1的RocketMQ-Streams版本依然使用Mysql作为远程状态存储,下一版本将使用RocketMQ作为远程状态存储。
二、RocketMQ总体架构图
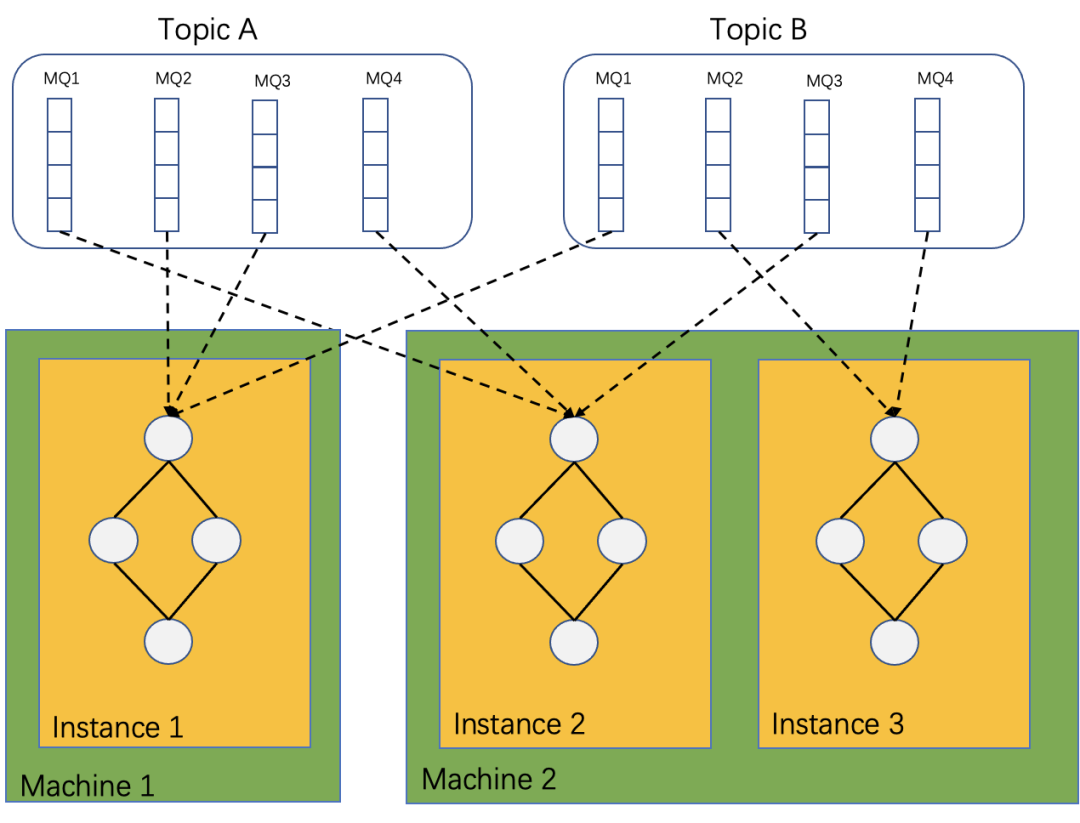
RocketMQ-Streams 作为轻量流处理引擎,本质上是作为RocketMQ 的客户端消费数据,一个流处理实例可以处理多个队列,而一个队列只能被一个实例消费。若干RocketMQ-Streams 实例组成消费者组共同消费数据,通过扩容实例达到增加处理能力的消费,减少实例则会发生rebalance,消费的队列自动重平衡到其他消费实例上。从上述图中,我们还可以看出计算实例间不需要直接交换任何数据,可各自独立完成所有计算处理。这种架构简化了RocketMQ-Streams 本身的设计,同时也可非常方便的进行实例扩缩容。
处理拓扑
处理器拓扑为应用定义了流处理过程的计算逻辑,它由一系列的处理器节点和数据流向组成。例如,在开头的代码示例中,整个处理拓扑由source、map、groupBy、sum、count、print等处理节点组成。有两种特殊的处理节点:
- source节点
他没有任何上游节点,从外部读入数据到RocketMQ-Streams,并交由下游处理。
- sink节点
他没有任何下游节点,他将处理后的数据写出到外部。
处理拓扑仅仅是流处理代码的逻辑抽象,在流计算启动时将会被实例化。为了设计简单,目前一个流处理实例中仅有一张计算拓扑。
在所有流处理算子之中,有两种特别的算子,一种是涉及数据分组的算子groupBy,另一种是有状态计算例如count等。这两种算子会影响整个计算拓扑的构建,下面将具体分析RocketMQ-Streams是如何处理他们的。
groupBy
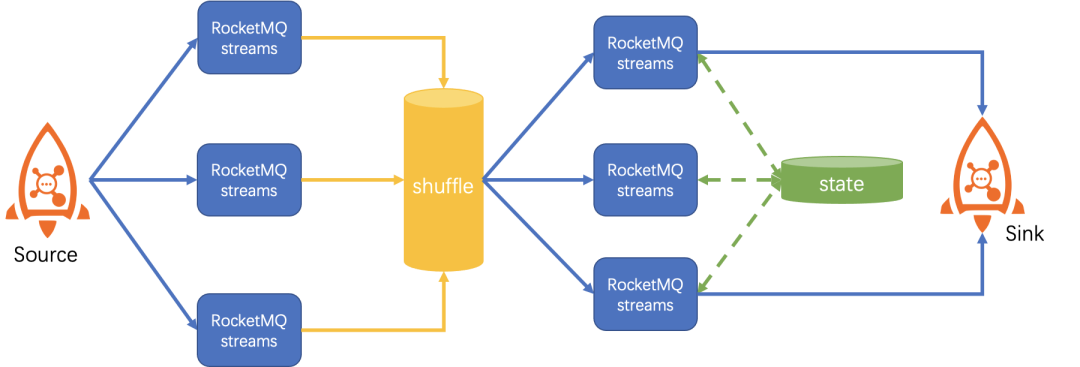
分组算子groupBy特殊是因为经过groupBy操作,后续算子期望对相同key的数据进行操作,例如经过groupBy("年级")之后再进行sum就是对按照年级分组求和,这就要求需要将具有相同“年级”的数据重新路由到一个流计算实例上处理,如果不这样做,每个实例上得出的结果都将是不完整的,整体输出结果也将是错误的。
RocketMQ-Streams 采用 shuffle topic 这种方式来处理。具体说来,计算实例将groupBy数据重新发回RocketMQ的一个topic,并且在发回过程中按照key的hash值来选择目标队列,再从这个topic读取数据进行后续流处理。按照key hash后相同的key一定在一个队列里面,而一个队列只会被一个流处理实例消费,这样就达到相同key被路由到一个实例上处理的效果。
有状态算子
有状态算子与无状态算子相对。如果计算结果只与当前输入有关,和上一次输入无关就是无状态算子,例如filter、map、foreach结果只与当前输入有关系。还有一种算子的输出结果不仅与当前算子有关系还与上一次输入有关,例如sum,需要对一段时间内输入进行求和,他就是有状态算子。
RocketMQ-Streams利用RocksDB作为本地存储,Mysql作为远程存储来保存状态数据。他具体做法是:
当发现消息来自新的队列时,检查是否需要加载状态,如果需要异步加载状态到RocksDB。
数据到达有状态算子时,如果加载完成使用RocksDB中状态进行计算,如果没有,使用Mysql中状态计算。
计算完成后,将状态数据保存到RocksDB和Mysql中。
窗口触发后,从RocksDB中查询出状态数据,并将结果向下游算子传递。
整体数据流向图如下:
三、扩缩容与故障恢复
扩缩容和故障恢复是一个硬币的两面,即同一个事物的两种表达,计算集群如果能正确扩缩容就等于具备故障恢复的能力,反之亦然。通过前面介绍我们知道,RocketMQ-Streams具有非常良好的扩缩容性能,扩容时只需要新部署一个流计算实例即可,缩容时停止计算实例即可。对于无状态的计算来说比较简单,扩容后,数据计算不需要之前的状态。有状态计算的扩缩容涉及到状态的迁移。有状态的扩缩容可由下图表示:
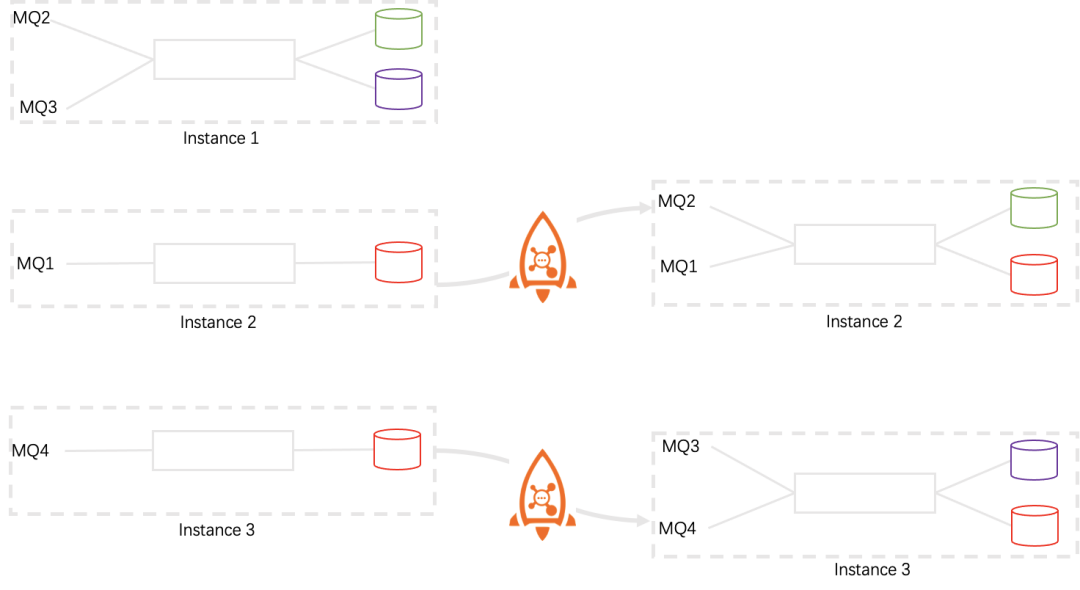
当计算实例从3个缩容到2个,借助于RocketMQ的rebalance,MQ会在计算实例之间重新分配。
Instance1上消费的MQ2和MQ3被分配到Instance2和Instance3上,这两个MQ的状态数据也需要迁移到Instance2和Instance3上,这也暗示,状态数据是根据源数据分片保存的;扩容则是刚好相反的过程。
具体实现上,RocketMQ-Streams采用系统消息来触发状态的加载和持久化。
系统消息类别:
//新增消费队列
NewSplitMessage
//不在消费某个队列
RemoveSplitMessage
//客户端持久化消费位点到MQ
CheckPointMessage
当发现消息来自一个新的RocketMQ队列(MessageQueue),RocketMQ-Streams之前没有处理过来自该队列的消息,会先于数据前发送NewSplitMessage消息,通过处理拓扑下游算子传递,当有状态算子收到该消息时会将新增队列对应的状态加载到本地内存RocksDB中,当数据真正到达时,就根据这个状态继续计算。
当因为计算实例增加或者RocketMQ集群变动,rebalance后,计算实例不再消费某个队列(MessageQueue)时,会发出RemoveSplitMessage消息,有状态算子删除本地RocksDB中的状态。
CheckPointMessage是一种特别的系统消息,他的作用与实现exactly-once有关。我们在扩缩容过程中需要做到exactly-once,才能保证扩缩容或故障恢复对计算结果没有影响。RocketMQ-streams向broker提交消费offset前会产生CheckPointMessage消息,向下游拓扑传递,他将保证即将提交消费位点的所有消息都已经被sink处理掉。
开源地址:
RocketMQ-Streams 仓库地址:
https://github.com/apache/rocketmq-streams
RocketMQ 仓库地址:
https://github.com/apache/rocketmq
作者:倪泽,RocketMQ 资深贡献者, RocketMQ-Streams 维护者之一,阿里云技术专家。