当下网络就如同空气一样在我们的周围,它以无数种方式改变着我们的生活,但要说网络的核心技术变化甚微。
随着开源文化的蓬勃发展,诞生了诸多优秀的开源 Web 框架,让我们的开发变得轻松。但同时也让我们不敢停下学习新框架的脚步,其实万变不离其宗,只要理解了 Web 框架的核心技术部分,当有一个新的框架出来的时候,基础部分大同小异只需要重点了解:它有哪些特点,用到了哪些技术解决了什么痛点?这样接受和理解起新技术来会更加得心应手,不至于疲于奔命。
还有那些只会用 Web 框架的同学,是否无数次打开框架的源码,想学习提高却无从下手?
今天我们就抽丝剥茧、去繁存简,用一个文件,实现一个迷你 Web 框架,从而把其核心技术部分清晰地讲解清楚,配套的源码均已开源。
GitHub 地址:https://github.com/521xueweihan/OneFile
在线查看:https://hellogithub.com/onefile/
如果你觉得我做的这件事对你有帮助,就请给我一个 ✨Star,多多转发让更多人受益。
闲言少叙,下面就开始我们今天的提高之旅。
一、介绍原理
说到 Web 不得不提的就是网络协议,如果我们从 OSI 七层网络模型开始,我敢断定看完的绝对不超过三成!
所以今天我们就直接聊最上面的一层,也就是 Web 框架接触最多的 HTTP 应用层,至于 TCP/IP 部分会在聊 socket 的时候粗略带过。期间我会刻意打码非必要讲解技术的细枝末节,切断远离本期主题的技术话题,一个文件只讲一个技术点!绝不拖堂请大家放心阅读。
首先让我们先回忆下,平常浏览网站的流程。
如果我们把在网上冲浪,比做在一间教室听课,那么老师就是服务器(server),学生就是客户端(client)。当同学有问题的时候会先举手(请求建立 TCP),老师发现学生的提问请求,同意学生回答问题后,学生起立提出问题(发送请求),如果老师承诺会给提问的学生加课堂表现分,那么提问的时候就需要有个高效的提问方式(请求格式),即:
- 先报学号
- 再提问题
师接收到学生的提问后就可以立即回答问题(返回响应)无需再问学号,回答格式(响应格式)如下:
- 回答问题
- 根据学号加分!
有了约定好的提问格式(协议),就可以省去老师每次询问学生的学号,即高效又严谨。最后,老师回答完问题让学生坐下(关闭连接)。
其实,我们在网络上通信流程也大致如此:
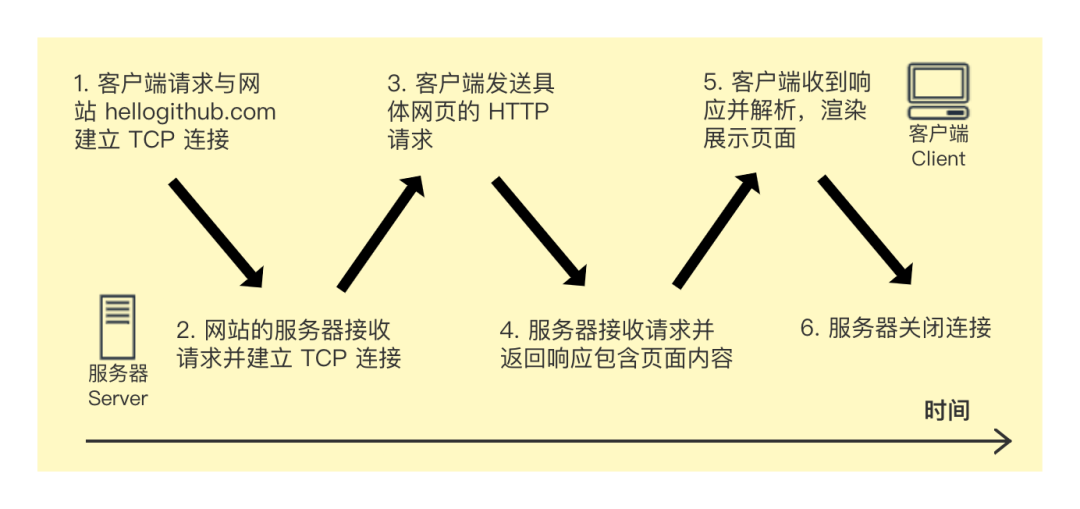
只不过机器执行起来更加严格,大家都是遵循某种协议来开发软件,这样就可以实现在某种协议下进行通信,而这种网络通信协议就叫做 HTTP(超文本传输协议)。
而我们要做的 Web 框架就是处理上面的流程:建立连接、接收请求、解析请求、处理请求、返回请求。
原理部分就聊这么多,目前你只需要记住网络上通信分为两大步:建立连接(用于通信)和处理请求。
所谓框架就是处理大多数情况下要处理的事情,所以我们要写的 Web 框架也就是处理两件事,即:
- 处理连接(socket)
- 处理请求(request)
一定要记住:连接和请求是两个东西,建立起连接才能发送请求。
而想要建立连接发起通信,就需要通过 socket 来实现(建立连接),socket 可以理解为两个虚拟的本子(文件句柄),通信的双方人手一个,它既能读也能写,只要把传输的内容写到本子上(处理请求),对方就可以看到了。

下面我把 Web 框架分为两部分进行讲解,所有代码将采用简单易懂的 Python3 进行实现。
二、编写 Web 框架
代码+注释一共 457 行,请放心绝对简单易懂。
2.1 处理连接(HTTPServer)
这里需要简单聊一下 socket 这个东西,在编程语言层面它就是一个类库,负责搞定连接建立网络通信。但本质上是系统级别提供通信的进程,而一台电脑可以建立多条通信线路,所以每一个端口号后面都是一个 socket 进程,它们相互独立、互不干涉,这也是为什么我们在启动服务的时候要指定端口号的原因。
最后,上面所说的服务器其实就是一台性能好一点、一直开着的电脑,而客户端就是浏览器、手机、电脑,它们都有 socket 这个东西(操作系统级别的一个进程)。
如果上面这段话没有看懂也不碍事,能看懂下面的图就行,得搞明白 socket 处理连接的步骤和流程,才能编写 Web 框架处理连接的部分。
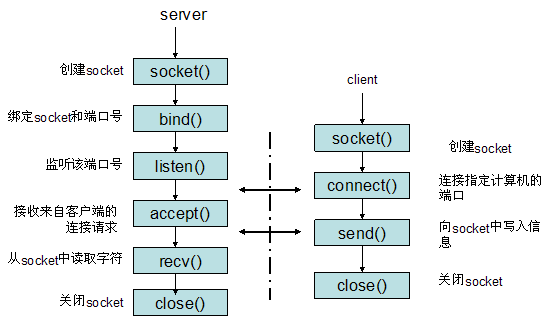
下面分别展示基于 socket 编写的 server.py 和 client.py 代码。
# coding: utf-8
# 服务器端代码(server.py)
import socket
print('我是服务端!')
HOST = ''
PORT = 50007
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM) # 创建 TCP socket 对象
s.setsockopt(socket.SOL_SOCKET, socket.SO_REUSEADDR, 1) # 重启时释放端口
s.bind((HOST, PORT)) # 绑定地址
s.listen(1) # 监听TCP,1代表:操作系统可以挂起(未处理请求时等待状态)的最大连接数量。该值至少为1
print('监听端口:', PORT)
while 1:
conn, _ = s.accept() # 开始被动接受TCP客户端的连接。
data = conn.recv(1024) # 接收TCP数据,1024表示缓冲区的大小
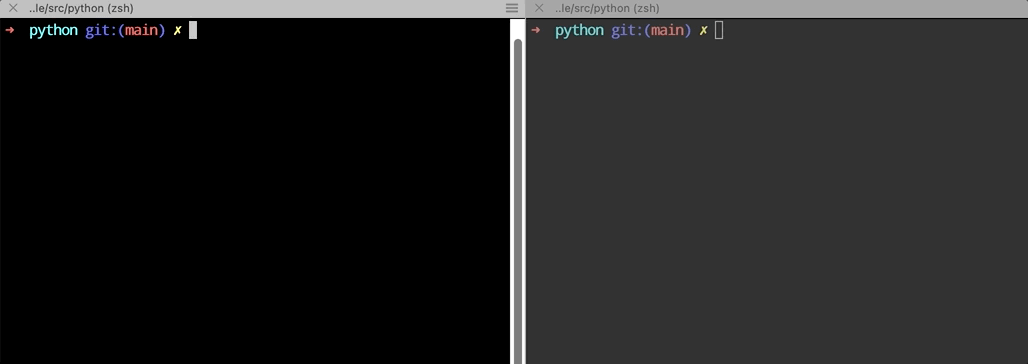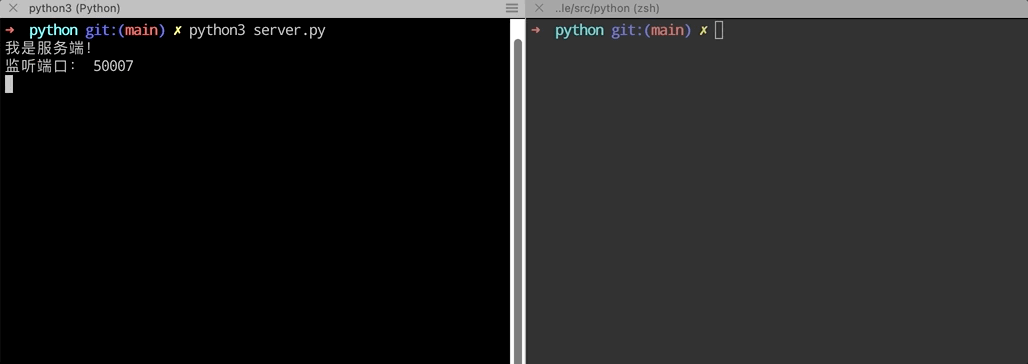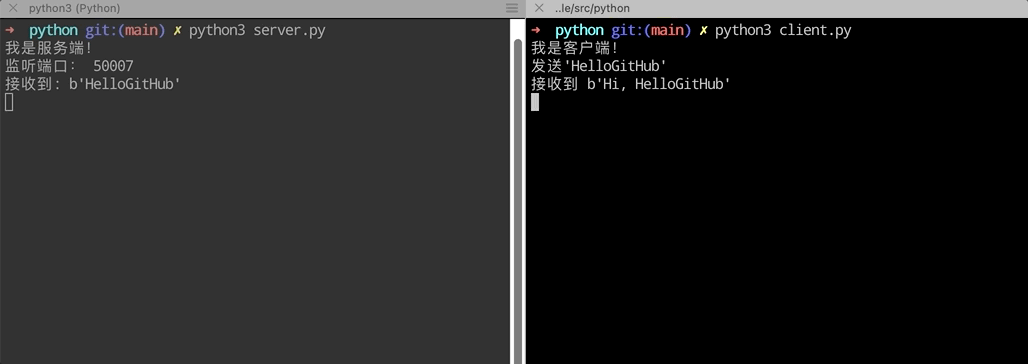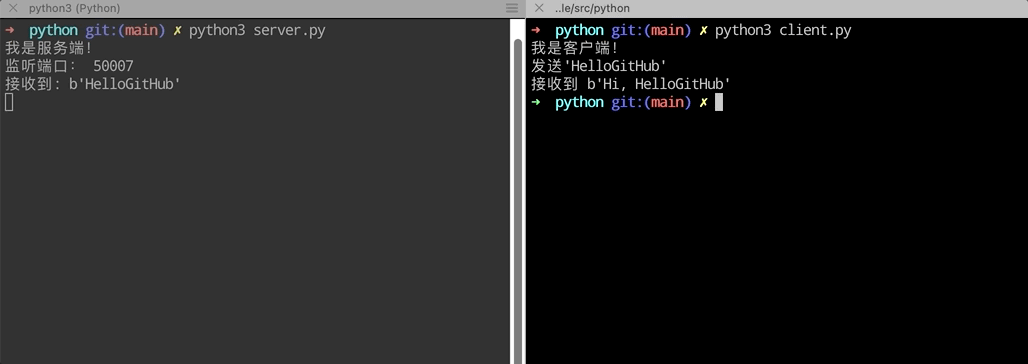
print('接收到:', repr(data))
conn.sendall(b'Hi, '+data) # 给客户端发送数据
conn.close()
因为 HTTP 是建立在相对可靠的 TCP 协议上,所以这里创建的是 TCP socket 对象。
# coding: utf-8
# 客户端代码(client.py)
import socket
print('我是客户端!')
HOST = 'localhost' # 服务器的IP
PORT = 50007 # 需要连接的服务器的端口
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect((HOST, PORT))
print("发送'HelloGitHub'")
s.sendall(b'HelloGitHub') # 发送‘HelloGitHub’给服务器
data = s.recv(1024)
s.close()
print('接收到', repr(data)) # 打印从服务器接收回来的数据
运行效果如下:
结合上面的代码,可以更加容易理解 socket 建立通信的流程:
- socket:创建socket
- bind:绑定端口号
- listen:开始监听
- accept:接收请求
- recv:接收数据
- close:关闭连接
所以,Web 框架中处理连接的 HTTPServer 类要做的事情就呼之欲出了。即:一开始在 __init__方法中创建 socket,接着绑定端口(server_bind)然后开始监听端口(server_activate)
# 处理连接进行数据通信
class HTTPServer(object):
def __init__(self, server_address, RequestHandlerClass):
self.server_address = server_address # 服务器地址
self.RequestHandlerClass = RequestHandlerClass # 处理请求的类
# 创建 TCP Socket
self.socket = socket.socket(socket.AF_INET,
socket.SOCK_STREAM)
# 绑定 socket 和端口
self.server_bind()
# 开始监听端口
self.server_activate()
通过传入的 RequestHandlerClass 参数可以看出,处理请求与建立连接是分开处理。
下面就要开始启动服务接收请求了,也就是 HTTPServer 的启动方法 serve_forever,这里包含了接收请求、接收数据、开始处理请求、结束请求的全过程。
def serve_forever(self):
while True:
ready = selector.select(poll_interval)
# 当客户端请求的数据到位,则执行下一步
if ready:
# 有准备好的可读文件句柄,则与客户端的链接建立完毕
request, client_address = self.socket.accept()
# 可以进行下面的处理请求了,通过 RequestHandlerClass 处理请求和连接独立
self.RequestHandlerClass(request, client_address, self)
# 关闭连接
self.socket.close()
如此循环下去,就是 HTTPServer 处理连接、建立起 HTTP 连接的全部代码,就这?对!是不是很简单?
代码中的 RequestHandlerClass 形参是处理请求的类,下面将深入讲解其对应的 HTTPRequestHandler 是如何处理 HTTP 请求。
2.2 处理请求(HTTPRequestHandler)
还记得上面介绍的 socket 如何实现两端通信吗?通过两个可读写的“虚拟本子”。
再加上还要保证通信的高效和严谨,就需要有对应的“通信格式”。
所以,处理请求只需要三步走:
setup:初始化两个本子
- 读请求的文件句柄(rfile)
- 写响应的文件句柄(wfile)
handle:读取并解析请求、处理请求、构造响应并写入
finish:返回响应,销毁两个本子释放资源,然后尘归尘土归土,等待下个请求
对应的代码:
# 处理请求
class HTTPRequestHandler(object):
def __init__(self, request, client_address, server):
self.request = request # 接收来的请求(socket)
# 1、初始化两个本子
self.setup()
try:
# 2、读取、解析、处理请求,构造响应
self.handle()
finally:
# 3、返回响应,释放资源
self.finish()
def setup(self):
self.rfile = self.request.makefile('rb', -1) # 读请求的本子
self.wfile = self.request.makefile('wb', 0) # 写响应的本子
def handle(self):
# 根据 HTTP 协议,解析请求
# 具体的处理逻辑,即业务逻辑
# 构造响应并写入本子
def finish(self):
# 返回响应
self.wfile.flush()
# 关闭请求和响应的句柄,释放资源
self.wfile.close()
self.rfile.close()
以上就是处理请求的整体流程,下面将详细介绍 handle 如何解析 HTTP 请求和构造 HTTP 响应,以及如何实现把框架和具体的业务代码(处理逻辑)分开。
在解析 HTTP 之前,需要先看一个实际的 HTTP 请求,当我打开 hellogithub.com 网站首页的时候,浏览器发送的 HTTP 请求如下:
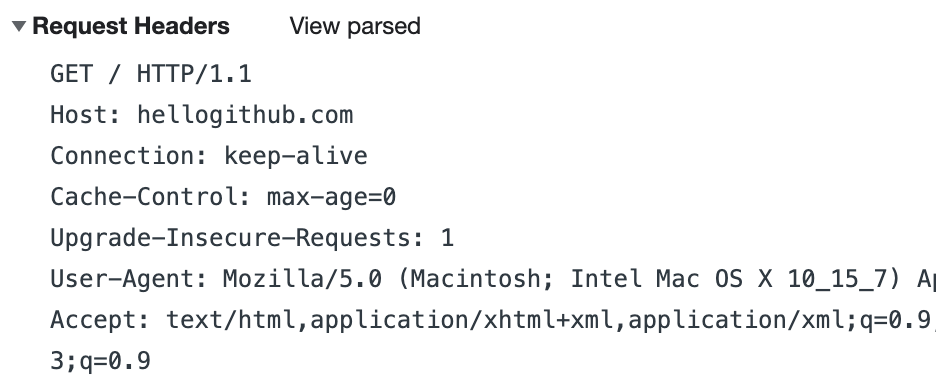
整理归纳可得 HTTP 请求格式,如下:
{HTTP method} {PATH} {HTTP version}\r\n
{header field name}:{field value}\r\n
\r\n
{request body}得到了请求格式,那么 handle 解析请求的方法也就有了。
def handle(self):
# --- 开始解析 --- #
self.raw_requestline = self.rfile.readline(65537) # 读取请求第一行数据,即请求头
requestline = str(self.raw_requestline, 'iso-8859-1') # 转码
requestline = requestline.rstrip('\r\n') # 去换行和空白行
# 就可以得到 "GET / HTTP/1.1" 请求头了,下面开始解析
self.command, self.path, self.request_version = requestline.split()
# 根据空格分割字符串,可得到("GET", "/", "HTTP/1.1")
# command 对应的是 HTTP method,path 对应的是请求路径
# request_version 对应 HTTP 版本,不同版本解析规则不一样这里不做展开讲解
self.headers = self.parse_headers() # 解析请求头也是处理字符串,但更为复杂标准库有工具函数这里略过
# --- 业务逻辑 --- #
# do_HTTP_method 对应到具体的处理函数
mname = ('do_' + self.command).lower()
method = getattr(self, mname)
# 调用对应的处理方法
method()
# --- 返回响应 --- #
self.wfile.flush()
def do_GET(self):
# 根据 path 区别处理
if self.path == '/':
self.send_response(200) # status code
# 加入响应 header
self.send_header("Content-Type", "text/html; charset=utf-8")
self.send_header("Content-Length", str(len(content)))
self.end_headers() # 结束头部分,即:'\r\n'
self.wfile.write(content.encode('utf-8')) # 写入响应 body,即:页面内容
def send_response(self, code, message=None):
# 响应体格式
"""
{HTTP version} {status code} {status phrase}\r\n
{header field name}:{field value}\r\n
\r\n
{response body}
"""
# 写响应头行
self.wfile.write("%s %d %s\r\n" % ("HTTP/1.1", code, message))
# 加入响应 header
self.send_header('Server', "HG/Python ")
self.send_header('Date', self.date_time_string())
以上就是 handle 处理请求和返回响应的核心代码片段了,至此 HTTPRequestHandler 全部内容均已讲解完毕,下面将演示运行效果。
2.3 运行
class RequestHandler(HTTPRequestHandler):
# 处理 GET 请求
def do_get(self):
# 根据 path 对应到具体的处理方法
if self.path == '/':
self.handle_index()
elif self.path.startswith('/favicon'):
self.handle_favicon()
else:
self.send_error(404)
if __name__ == '__main__':
server = HTTPServer(('', 8080), RequestHandler)
# 启动服务
server.serve_forever()
这里通过继承 Web 框架的 HTTPRequestHandler 实现的子类 RequestHandler 重写 do_get 方法,实现业务代码和框架的分离。这样保证了框架的灵活性和解耦。
接下来服务毫无意外地运行起来了,效果如下:
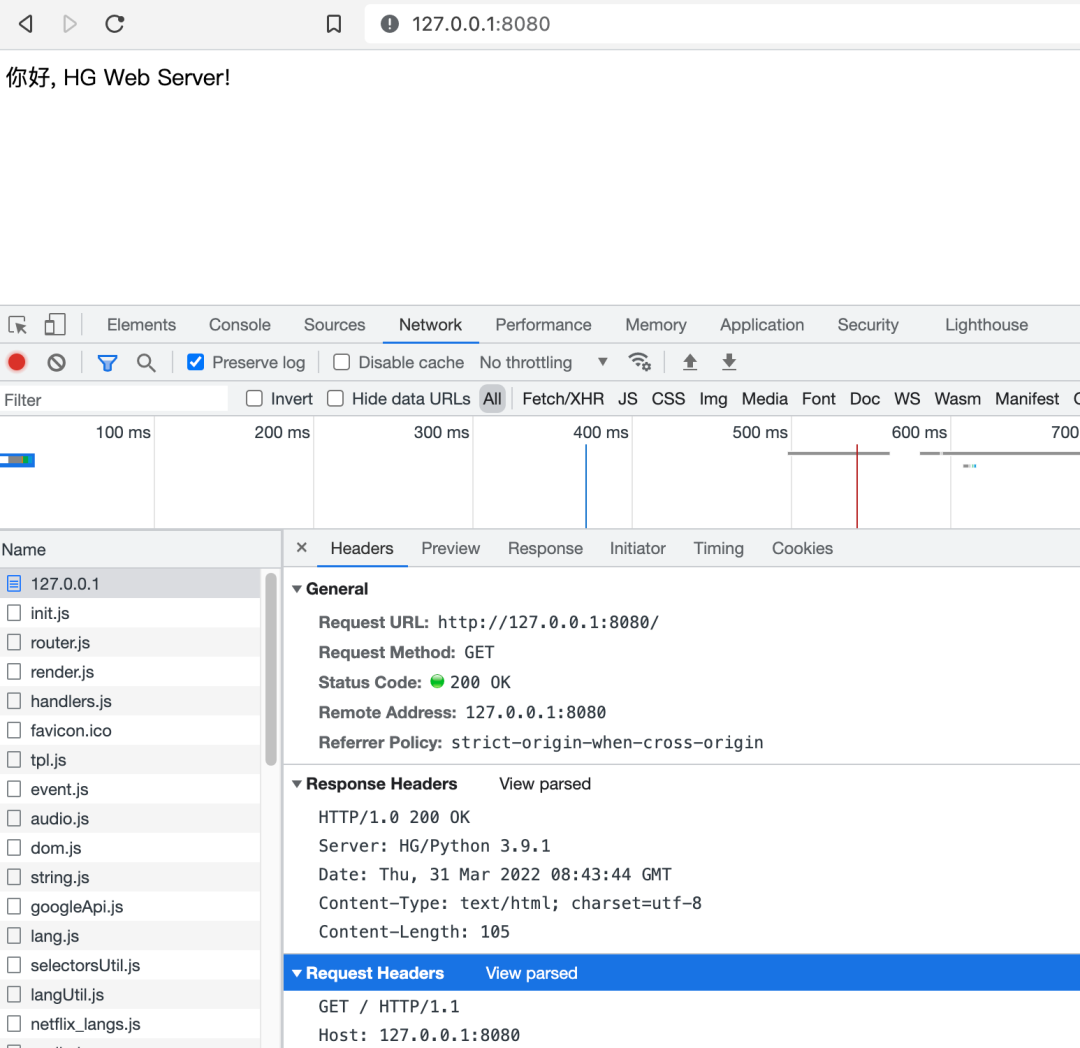
本文中涉及 Web 框架的代码,为方便阅读都经过了简化。如果想要获取完整可运行的代码,可前往 GitHub 地址获取:
https://github.com/521xueweihan/OneFile/blob/main/src/python/web-server.py
该框架并不包含 Web 框架应有的丰富功能,旨在通过最简单的代码,实现一个迷你 Web 框架,让不了解基本 Web 框架结构的同学,得以一探究竟。
如果本文的内容勾起了你对 Web 框架的兴趣,你还想更加深入的了解更加全面、适用于生产环境、代码和结构同样的简洁的 Web 框架。我建议的学习路径:
- Python3 的 HTTPServer、BaseHTTPRequestHandler
- bottle:单文件、无三方依赖、持续更新,可用于生产环境的开源 Web 框架:
- werkzeug -> flask
- starlette -> uvicorn -> fastapi
有的时候阅读框架源码不是为了写一个新的框架,而是向前辈学习和靠拢。
最后
新的技术总是学不完的,掌握核心的技术原理,不仅可以在接受新的知识时快人一步,还可以在排查问题时一针见血。