译者 | 朱先忠
审校 | 梁策 孙淑娟
AutoML简介

自动机器学习(AutoML)能够自动运行各种机器学习过程,并优化错误度量以生成最佳模型。这些过程包括数据预处理、编码、缩放、优化超参数、模型训练、生成制品和结果列表。自动化机器学习过程可以快速开发人工智能解决方案,让用户体验变得友好,并通常以低代码即可生成准确结果。
目前市场上流行的一些著名AutoML库包括:
在这篇教程中,我们将使用美国1994年人口普查时的收入数据来预测一个人的年收入是否超过5万美元。这是一个经典的二分类问题,我们将在CC0公共域许可下使用Kaggle成人普查收入数据集进行预测。该数据由美国硅图公司(SGI,Silicon Graphics)数据挖掘和可视化部门的罗尼·克哈伊(Ronny Kohavi)和巴里·贝克尔(Barry Becker)从美国1994年人口普查局数据库中提供。但是,我们这里不去深入研究数据分析或模型工作方式,只是仅用几行代码来构建一个优化的机器学习模型,并使用FastAPI服务器对该模型进行访问。
AutoXGB项目简介
AutoXGB是一个开源、简单、有效的AutoML辅助开发工具,可以直接从CSV文件中训练模型表格数据集。AutoXGB使用XGBoost(优化的分布式梯度增强库)来训练模型,使用Optuna(为机器学习、深度学习特别设计的自动超参数优化框架)进行超参数优化,并使用基于Python的FastAPI框架并以API的形式提供模型推理。
下面让我们从安装AutoXGB开始介绍。如果在运行服务器时遇到错误,请确保预先已正确安装了FastAPI框架和unvicorn服务器程序。安装AutoXGB的命令如下:
pip install autoxgb
- 1.
初始化
接下来,我们将深入介绍AutoXGB函数的特征,以及如何使用与之相关的各项参数来改进计算结果或减少训练时间。AutoXGB函数的各项参数含义说明如下:
- train_filename:训练数据所在的路径。
- output:存储工件的输出文件夹的路径。
- test_filename:测试数据所在路径。如果未指定,则仅保存折外预测(out-of-fold predictions,简称“OOF预测”)数据。
- task:如果未指定该参数值,系统将自动推断其值。此参数有两个取值:
1."classification"
2."regression"
- idx:如果未指定该参数值,系统将自动使用名称id生成 id列。
- targets:如果未指定该参数值,则假定目标列被命名为目标(target),并将该问题视为一个二分类、多类分类或单列回归三种问题之一。此参数可以使用如下两种取值:
1.["target"]
2.["target1", "target2"]
- features:如果未指定该参数值, 除去id、targets和kfold列外的所有列都会被使用。指定值方式例如:
1.features = ["col1", "col2"]
- categorical_features:如果未指定该参数值,将自动推断分类列。指定值方式例如:
1.categorical_features = ["col1", "col2"]
- use_gpu:如果未指定该参数值,将不启用GPU计算功能。指定值方式例如:
1.use_gpu = True
2.use_gpu = False
- num_folds:用来进行交叉验证的折(fold)的个数。
- seed:随机种子的重复性。
- num_trials:运行的Optuna试验次数;默认值为1000。
- time_limit:以秒计量的optuna试验时限。
1.如果未指定,将运行所有试验。此时(默认)有time_limit = None。
- fast:如果fast参数值设置为True,超参数调整将只使用一次,从而减少优化时间。之后,将在折(fold)的其余部分进行训练,并生成OOF和测试预测。
在我们的测试项目中,除了参数train_filename、output、target、num_folds、seed、num_trails和time_limit之外,我们将大多数参数的值设置为默认值。项目中各参数的完整设置情况,如下所示:
from autoxgb import AutoXGB
train_filename = "binary_classification.csv"
output = "output"
test_filename = None
task = None
idx = None
targets = ["income"]
features = None
categorical_features = None
use_gpu = False
num_folds = 5
seed = 42
num_trials = 100
time_limit = 360
fast = False
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
训练与优化
现在,我们可以使用AutoXGB函数定义模型,并将之前定义的参数添加到模型中。最后,我们将调用axgb.train()函数开始训练过程。此时,将运行XGBoost和Optuna,并输出各种制品(包括模型、预测、结果、配置、参数、编码器等)。
axgb = AutoXGB(
train_filename=train_filename,
output=output,
test_filename=test_filename,
task=task,
idx=idx,
targets=targets,
features=features,
categorical_features=categorical_features,
use_gpu=use_gpu,
num_folds=num_folds,
seed=seed,
num_trials=num_trials,
time_limit=time_limit,
fast=fast,
)
axgb.train()
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
训练过程耗时10-12分钟,我们可以看到下面的最佳训练结果,并可以通过增加时间限制来提高F1分数。此外,我们还可以使用其他超参数来提高模型性能。
2022-02-09 18:11:27.163 | INFO | autoxgb.utils:predict_model:336 - Metrics: {'auc': 0.851585935958628, 'logloss': 0.3868651767621002, 'f1': 0.5351485750859325, 'accuracy': 0.8230396087432015, 'precision': 0.7282822005864846, 'recall': 0.42303153575005525}
- 1.
使用CLI命令行进行训练
为了使用bash终端方式进行模型训练,我们可以使用命令autoxgb train。此时,我们将只需设置train_filename和output两个参数即可。其中,参数train_filename用于确定训练的二分类文件名,而参数output用于指出输出文件夹位置。命令如下:
autoxgb train \
--train_filename binary_classification.csv \
--output output \
- 1.
- 2.
- 3.
Web API
通过在终端中运行autoxgb 服务的方式,我们可以在本地运行FastAPI服务器。
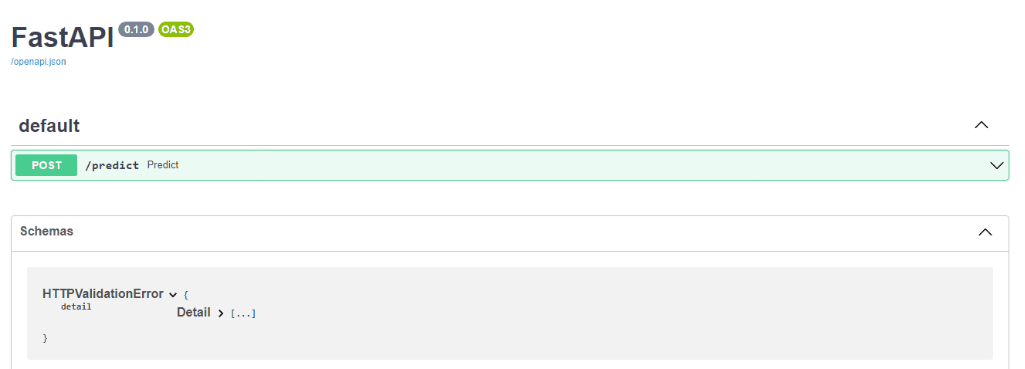
AutoXGB服务参数
- model_path:指向模型文件的路径。在本文测试中,指向输出文件夹。
- Port:服务器主机运行的端口号,值为8080。
- host:运行的服务器主机,IP地址是:0.0.0.0。
- workers:工作线程数或同时请求的数量。
- debug:显示错误和成功的日志。
在Deepnote云服务器上运行
为了在云上运行服务器,Deepnote使用ngrok创建了一个公共URL。我们只需要启用该选项并使用8080端口即可。当然,如果您在本地运行,则无需此步,直接使用地址“http://0.0.0.0:8080”即可。
我们提供了运行服务器的模型路径、主机ip和端口号。
!autoxgb serve --model_path /work/output --host 0.0.0.0 --port 8080 --debug
- 1.
结果显示,我们的API运行平稳。您可以使用网址https://8d3ae411-c6bc-4cad-8a14-732f8e3f13b7.deepnoteproject.com来观察相应的结果数据。
INFO: Will watch for changes in these directories: ['/work']
INFO: Uvicorn running on http://0.0.0.0:8080 (Press CTRL+C to quit)
INFO: Started reloader process [153] using watchgod
INFO: Started server process [163]
INFO: Waiting for application startup.
INFO: Application startup complete.
INFO: 172.3.161.55:40628 - "GET /docs HTTP/1.1" 200 OK
INFO: 172.3.188.123:38788 - "GET /openapi.json HTTP/1.1" 200 OK
INFO: 172.3.167.43:48326 - "GET /docs HTTP/1.1" 200 OK
INFO: 172.3.161.55:47018 - "GET /openapi.json HTTP/1.1" 200 OK
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
预测
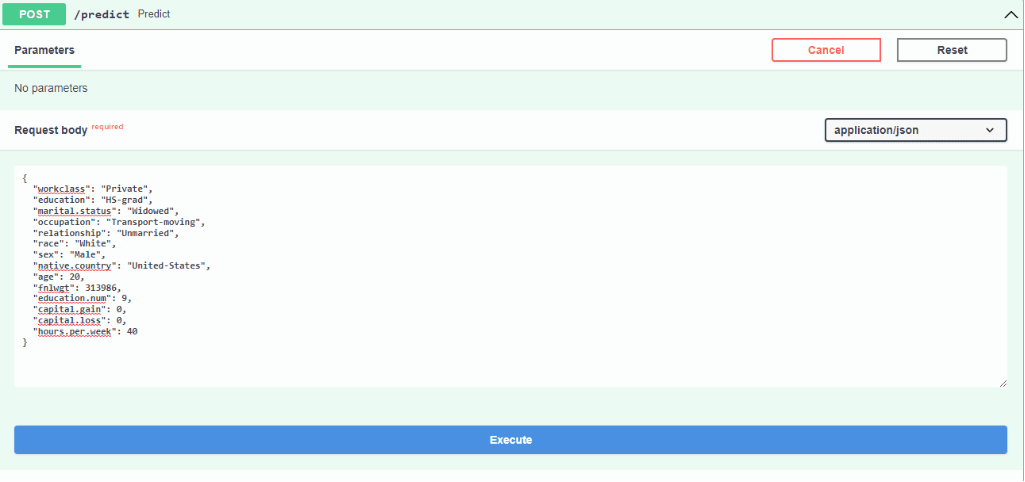
我们可以添加随机输入来预测某人的收入是否超过5万美元。在本例中,我们使用FastAPI/docs选项访问用户界面。
输入数据
我们使用FastAPI GUI来运行模型预测,这可以通过在服务器地址末尾添加/docs实现,例如“172.3.167.43:39118/docs”。本文项目中输入的其他测试数据如下:
- workclass:"Private"
- education:"HS-grad"
- marital.status:"Widowed"
- occupation:"Transport-moving"
- relationship:"Unmarried"
- race:"White"
- sex:"Male"
- native.country:"United-States"
- age:20
- fnlwgt:313986
- education.num:9
- capital.gain:0
- capital.loss:0
- hours.per.week:40
测试结果
实验的结果是:小于5万美元的置信度为97.6%,而大于5万美元的置信度为2.3%。

使用Request库进行测试
你还可以借助Python中的requests库来测试API。这一步很简单,你只需以字典的形式推送参数,然后就可以通过JSON格式获得输出结果。
import requests
params = {
"workclass": "Private",
"education": "HS-grad",
"marital.status": "Widowed",
"occupation": "Transport-moving",
"relationship": "Unmarried",
"race": "White",
"sex": "Male",
"native.country": "United-States",
"age": 20,
"fnlwgt": 313986,
"education.num": 9,
"capital.gain": 0,
"capital.loss": 0,
"hours.per.week": 40,
}
article = requests.post(
f"https://8d3ae411-c6bc-4cad-8a14-732f8e3f13b7.deepnoteproject.com/predict",
json=params,
)
data_dict = article.json()
print(data_dict)
## {'id': 0, '<=50K': 0.9762147068977356, '>50K': 0.023785298690199852}
- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
有关项目源码
如果对本文项目的完整代码及有关示例感兴趣,请访问下面几个链接:
结论
我本人曾借助AutoXGB并使用AutoML在Kaggle竞赛中获得过优异成绩,并为一些机器学习项目开发过一个基础模型。在整个机器学习过程中,有时结果可以快速而准确的获得,但如果想要创建最先进的解决方案,则需要手动尝试各种机器学习过程。
本教程带我们学习了AutoXGB的各种功能,现在我们可以使用AutoXGB预处理数据,训练XGboost模型,使用Optuna优化模型,以及FastAPI运行Web服务器。简而言之,AutoXGB能够为日常表格数据问题提供端到端的解决方案。
译者介绍
朱先忠,51CTO社区编辑,51CTO专家博客、讲师,潍坊一所高校计算机教师,自由编程界老兵一枚。早期专注各种微软技术(编著成ASP.NET AJX、Cocos 2d-X相关三本技术图书),近十多年投身于开源世界(熟悉流行全栈Web开发技术),了解基于OneNet/AliOS+Arduino/ESP32/树莓派等物联网开发技术与Scala+Hadoop+Spark+Flink等大数据开发技术。
原文标题:No Brainer AutoML with AutoXGB,作者:Abid Ali Awan