













大家好! 我是深圳技术大学FSR实验室的同学,在OpenHarmony成长计划啃论文俱乐部里,与华为、软通动力、润和软件、拓维信息、深开鸿等公司一起,学习和研究序列化相关技术…
【本期看点】
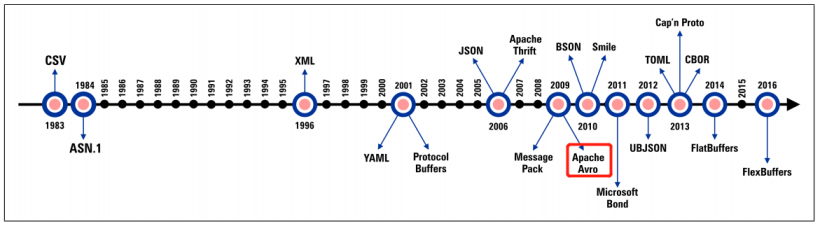
- Apache Avro发展时间及应用。
- 文献场景概述。
- 与Apache Avro集成后的Twister体系结构。
Apache Avro发展时间及应用
开源地址:apache/avro: Apache Avro is a data serialization system. (github.com)。
今天我们要讲的是Apache Avro,其是Hadoop的一个子项目,由Hadoop的创始人Doug Cutting牵头开发。Avro是一个数据序列化系统,设计用于支持大批量数据交换的应用。它的主要特点有:支持二进制序列化方式,可以便捷,快速地处理大量数据;动态语言友好,Avro提供的机制使动态语言可以方便地处理Avro数据。
其主要应用场景也是在大数据处理方面。


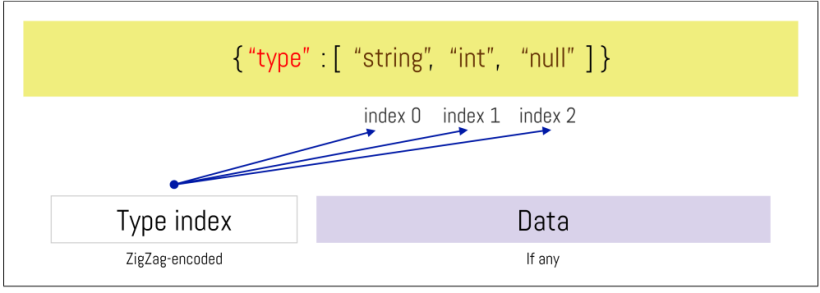
Apache Avro的 schema可以为单个字段声明潜在类型的有序列表。在这些情况下,Apache Avro二进制编码会在值的前面加上一个32位 ZigZag编码的小尾端基数128(LEB128)可变长度有符号整数,该整数对应于有序类型列表的索引。
对于多种类型组成的字段,会被编码为数据类型索引(Type index)。例如下图,如果schema定义了一个类型为[“string”、“int”、“null”]的字段,那么如果值是字符串,则该值将以0x00作为前缀,如果值是整数,则以0x02作为前缀,如果值为空,则以0x04作为前缀,然后作为数据段的类型索引(Type index)。
文献场景概述
这次我分享的文献是关于Apache Avro在Twister信息传递系统的应用,该项目的目标是研究并实现一种用于Twister消息传递系统的新方法。
Twister是一个迭代的MapReduce框架,它将MapReduce范式提升到了一个更高的层次,满足了迭代性质的应用。Twister通过Narada Brokering使用发布/订阅消息系统,但是由此引发的问题是,与较小的控制消息相比,在交换相对较大的数据消息时,消息传递体验会延迟。
为了研究这个问题,该论文提出了另一种方法实现,就是通过远程过程调用(RPC),并且选择Apache Avro作为RPC框架,所有计算节点都可以直接从彼此发送和接收数据,而不是通过代理系统。下面我们来看看Apache Avro和原Narada Brokerin系统的性能差别吧。
与Apache Avro集成后的Twister体系结构
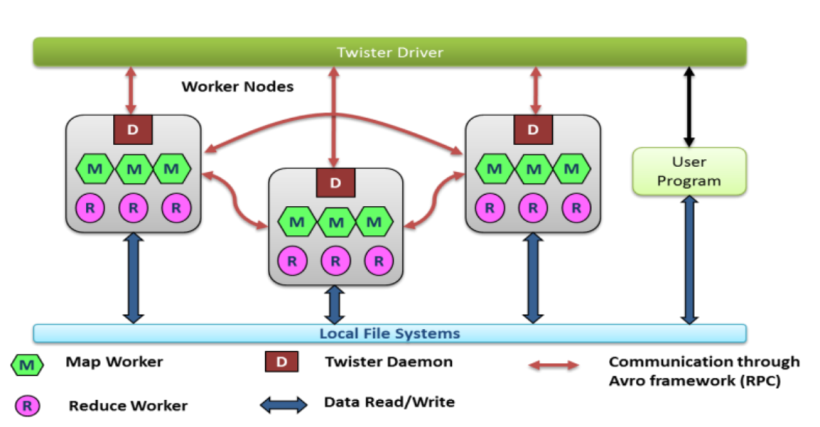

如上图,ApacheAvro用于Twister驱动程序(Twister Driver)和Twister Daemon之间,以及Twister Daemon之间的通信。每个节点都可以通过RPC和序列化直接相互通信,而不是通过代理系统发送或接收消息。这样就可以消除了发布/订阅代理系统与计算节点之间的通信开销和瓶颈。
测试结果
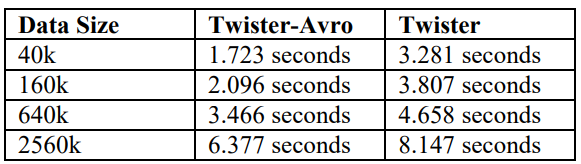

上图展示了使用我们Apache Avro和原Narada Brokerin系统在不同的数据大小上运行K-means算法的时间性能差别。正如我们所期望的,这个基于Apache Avro的替代方法可以减少通信开销并提高系统性能。





























