













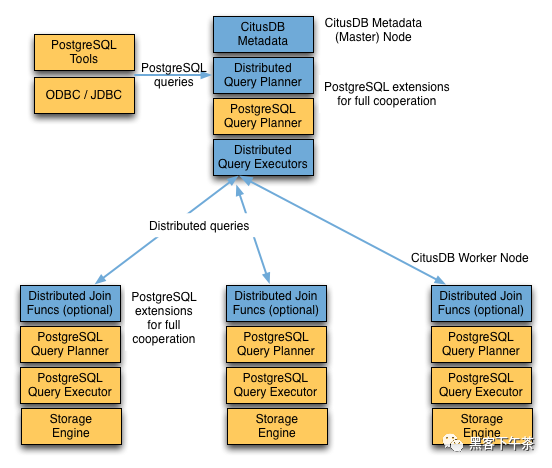
一个 Citus 集群由一个 coordinator 实例和多个 worker 实例组成。数据在 worker 上进行分片和复制,而 coordinator 存储有关这些分片的元数据。向集群发出的所有查询都通过 coordinator 执行。 coordinator 将查询划分为更小的查询片段,其中每个查询片段可以在分片上独立运行。然后协调器将查询片段分配给 worker,监督他们的执行,合并他们的结果,并将最终结果返回给用户。查询处理架构可以通过下图进行简要描述。
Citus 的查询处理管道涉及两个组件:
- 分布式查询计划器和执行器
- PostgreSQL 计划器和执行器
我们将在后续部分中更详细地讨论它们。
分布式查询计划器
Citus 的分布式查询计划器接收 SQL 查询并规划它以进行分布式执行。
对于 SELECT 查询,计划器首先创建输入查询的计划树,并将其转换为可交换和关联形式,以便可以并行化。它还应用了一些优化以确保以可扩展的方式执行查询,并最大限度地减少网络 I/O。
接下来,计划器将查询分为两部分 - 在 coordinator 上运行的 coordinator 查询和在 worker 上的各个分片上运行的 worker 查询片段。然后,计划器将这些查询片段分配给 worker,以便有效地使用他们的所有资源。在这一步之后,分布式查询计划被传递给分布式执行器执行。
分布列上的键值查找或修改查询的规划过程略有不同,因为它们恰好命中一个分片。一旦计划器收到传入的查询,它需要决定查询应该路由到的正确分片。为此,它提取传入行中的分布列并查找元数据以确定查询的正确分片。然后,计划器重写该命令的 SQL 以引用分片表而不是原始表。然后将该重写的计划传递给分布式执行器。
分布式查询执行器
Citus 的分布式执行器运行分布式查询计划并处理故障。执行器非常适合快速响应涉及过滤器、聚合和共置连接的查询,以及运行具有完整 SQL 覆盖的单租户查询。它根据需要为每个分片打开一个与 woker 的连接,并将所有片段查询发送给他们。然后它从每个片段查询中获取结果,合并它们,并将最终结果返回给用户。
子查询/CTE Push-Pull 执行
如有必要,Citus 可以将来自子查询和 CTE 的结果收集到 coordinator 节点中,然后将它们推送回 worker 以供外部查询使用。这允许 Citus 支持更多种类的 SQL 构造。
例如,在 WHERE 子句中包含子查询有时不能与主查询同时执行内联,而必须单独执行。假设 Web 分析应用程序维护一个按 page_id 分区的 page_views 表。要查询前 20 个访问量最大的页面上的访问者主机数,我们可以使用子查询来查找页面列表,然后使用外部查询来计算主机数。
SELECT page_id, count(distinct host_ip)
FROM page_views
WHERE page_id IN (
SELECT page_id
FROM page_views
GROUP BY page_id
ORDER BY count(*) DESC
LIMIT 20
)
GROUP BY page_id;- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
执行器希望通过 page_id 对每个分片运行此查询的片段,计算不同的 host_ips,并在 coordinator 上组合结果。但是,子查询中的 LIMIT 意味着子查询不能作为片段的一部分执行。通过递归规划查询,Citus 可以单独运行子查询,将结果推送给所有 worker,运行主片段查询,并将结果拉回 coordinator。 push-pull(推拉) 设计支持上述子查询。
让我们通过查看此查询的 EXPLAIN 输出来了解这一点。它相当参与:
GroupAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: remote_scan.page_id
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
-> Distributed Subplan 6_1
-> Limit (cost=0.00..0.00 rows=0 width=0)
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: COALESCE((pg_catalog.sum((COALESCE((pg_catalog.sum(remote_scan.worker_column_2))::bigint, '0'::bigint))))::bigint, '0'::bigint) DESC
-> HashAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=54.70..56.70 rows=200 width=12)
Group Key: page_id
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=4)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=84.50..86.75 rows=225 width=36)
Group Key: page_views.page_id, page_views.host_ip
-> Hash Join (cost=17.00..78.88 rows=1124 width=36)
Hash Cond: (page_views.page_id = intermediate_result.page_id)
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=36)
-> Hash (cost=14.50..14.50 rows=200 width=4)
-> HashAggregate (cost=12.50..14.50 rows=200 width=4)
Group Key: intermediate_result.page_id
-> Function Scan on read_intermediate_result intermediate_result (cost=0.00..10.00 rows=1000 width=4)- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
- 26.
- 27.
- 28.
- 29.
- 30.
- 31.
- 32.
让我们把它拆开并检查每一块。
GroupAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: remote_scan.page_id- 1.
- 2.
- 3.
- 4.
树的 root 是 coordinator 节点对 worker 的结果所做的事情。在这种情况下,它正在对它们进行分组,并且 GroupAggregate 要求首先对它们进行排序。
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
-> Distributed Subplan 6_1
.- 1.
- 2.
- 3.
自定义扫描有两个大子树,从“分布式子计划”开始。
-> Limit (cost=0.00..0.00 rows=0 width=0)
-> Sort (cost=0.00..0.00 rows=0 width=0)
Sort Key: COALESCE((pg_catalog.sum((COALESCE((pg_catalog.sum(remote_scan.worker_column_2))::bigint, '0'::bigint))))::bigint, '0'::bigint) DESC
-> HashAggregate (cost=0.00..0.00 rows=0 width=0)
Group Key: remote_scan.page_id
-> Custom Scan (Citus Adaptive) (cost=0.00..0.00 rows=0 width=0)
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=54.70..56.70 rows=200 width=12)
Group Key: page_id
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=4)
.- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
工作节点为 32 个分片中的每一个运行上述内容(Citus 正在选择一个代表进行显示)。我们可以识别 IN (...) 子查询的所有部分:排序、分组和限制。当所有 worker 完成此查询后,他们会将其输出发送回 coordinator,coordinator 将其组合为“中间结果”。
Task Count: 32
Tasks Shown: One of 32
-> Task
Node: host=localhost port=9701 dbname=postgres
-> HashAggregate (cost=84.50..86.75 rows=225 width=36)
Group Key: page_views.page_id, page_views.host_ip
-> Hash Join (cost=17.00..78.88 rows=1124 width=36)
Hash Cond: (page_views.page_id = intermediate_result.page_id)
.- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
Citus 在第二个子树中启动另一个执行器作业。它将在 page_views 中计算不同的主机。它使用 JOIN 连接中间结果。中间结果将帮助它限制在前二十页。
-> Seq Scan on page_views_102008 page_views (cost=0.00..43.47 rows=2247 width=36)
-> Hash (cost=14.50..14.50 rows=200 width=4)
-> HashAggregate (cost=12.50..14.50 rows=200 width=4)
Group Key: intermediate_result.page_id
-> Function Scan on read_intermediate_result intermediate_result (cost=0.00..10.00 rows=1000 width=4)
.- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
工作人员使用 read_intermediate_result 函数在内部检索中间结果,该函数从 coordinator 节点复制的文件中加载数据。
这个例子展示了 Citus 如何使用分布式子计划在多个步骤中执行查询,以及如何使用 EXPLAIN 来了解分布式查询执行。
PostgreSQL 计划器和执行器
一旦分布式执行器将查询片段发送给 worker,它们就会像常规 PostgreSQL 查询一样被处理。该 worker 上的 PostgreSQL 计划程序选择在相应分片表上本地执行该查询的最佳计划。 PostgreSQL 执行器然后运行该查询并将查询结果返回给分布式执行器。您可以从 PostgreSQL 手册中了解有关 PostgreSQL 计划器和执行器的更多信息。最后,分布式执行器将结果传递给 coordinator 进行最终聚合。
- 计划器
http://www.postgresql.org/docs/current/static/planner-optimizer.html
- 执行器
http://www.postgresql.org/docs/current/static/executor.html





























