大家好,欢迎来到Tlog4J课堂,我是Jensen。
面试官:数据库事务的四大特性是什么?
候选人:ACID,分别指原子性、一致性、隔离性、持久性(得意~)
面试官:那在MySQL的InnoDB中,ACID是怎么保证的呢?
候选人:啊这……
ACID大家耳熟能详,ACID是指数据库事务中的基本特性:原子性、一致性、隔离性、持久性,那么这四种特性在MySql中是怎么保证的呢?或者说,在InnoDB存储引擎中,ACID是怎么实现的呢?这个在学校里的老师可没教……
那今天咱们一起来看看,MySQL为了达成这四种特性做了一些什么事情。
首先,要回答这个问题得了解清楚MySQL的日志体系,MySQL在InnoDB存储引擎级别有两种日志:undo log日志和redo log日志,那在MySQL Server级别又有一个binlog日志,咱们结合这几个日志来说明ACID特性。
Atomicity原子性保障
事务的原子性指一个事务(transaction)中的所有操作,要么全部完成,要么全部不完成,不会结束在中间某个环节。事务在执行过程中发生错误,会被回滚(Rollback)到事务开始前的状态,就像这个事务从来没有执行过一样。
原子性是由undo log日志保证的,它记录了需要回滚的日志信息,也就是说我们的事务还没提交需要回滚,那么事务回滚就是根据undo log日志来撤销已经执行成功的SQL。
说白了,undo log其实就是SQL的反向执行,它记录了反向执行的SQL语句,把正向语句回滚回去。
Consistency一致性保障
事务的一致性指的是在一个事务执行之前和执行之后数据库都必须处于一致性状态。
如果事务成功地完成,那么系统中所有变化将正确地应用,系统处于有效状态;如果在事务中出现错误,那么系统中的所有变化将自动地回滚,系统返回到原始状态。
一致性是ACID的目的,也就是说,只需要保证原子性、隔离性、持久性,自然也就保证了数据的一致性。
比如说,我们的ID在数据库中是唯一的,此时插入了一个唯一ID,数据库会给我们做一个检查,告诉咱们是否发生了主键冲突,如果主键冲突数据就无法插入。
另一部分是业务数据的一致性,这需要程序代码来保证。
比如说转账这个场景,假设我要转账100元出去,实际上数据库中只有90元,那这时候就不应该转账成功,这种情况通过数据库是无法保证的,只能由程序来保证。
Isolation隔离性保障
事务的隔离性指的是在并发环境中,当不同的事务同时操纵相同的数据时,每个事务都有各自的完整数据空间,由并发事务所做的修改必须与任何其他并发事务所做的修改隔离。
事务查看数据更新时,数据所处的状态要么是另一事务修改它之前的状态,要么是另一事务修改它之后的状态,事务不会查看到中间状态的数据。
在MySQL中隔离性是通过MVCC多版本并发控制机制来保证的,它是在事务隔离级别中最最重要的一个概念,那它是怎么实现的呢?
多版本并发控制:读取数据时通过一种类似快照的方式将数据保存下来,这样读锁和写锁就不冲突了,不同事务的session会看到自己特定版本的数据,也就是版本链,通过版本链的概念来达到读和写能够并发进行。
MVCC只在READ COMMITTED(已提交读)和REPEATABLE READ(可重复读)两个隔离级别下工作,其他两个隔离级别和MVCC不兼容,这是因为READ UNCOMMITTED(读未提交)总是读取最新的数据行,而不是符合当前事务版本的数据行,而ZERIALIZABLE(串行化)则会对所有读取的行都加锁,MVCC就没有意义了。
在MySQL的InnoDB下,聚簇索引记录中有两个必要的隐藏列:
- trx_id:它用来存储每次对某条聚簇索引记录进行修改时的事务ID,这个事务ID由MySQL分配。
- roll_pointer:每次对哪条聚簇索引记录有修改的时候,都会把老版本写入undo日志中,这个roll_pointer就是存了一个指针,它指向这条聚簇索引记录的上一个版本的位置,通过它来获得上一个版本的记录信息(注意插入操作的undo日志没有这个属性,因为它没有老版本)。
OK,理解了这些概念,咱们再来看看MVCC。
已提交读和可重复读的区别就在于它们生成ReadView的策略不同。
MVCC就是版本链+ReadView所组成的这么一种概念,当我们掌握了版本链和ReadView这两个概念,也就明白了MVCC,我们接着来看看这个ReadView。
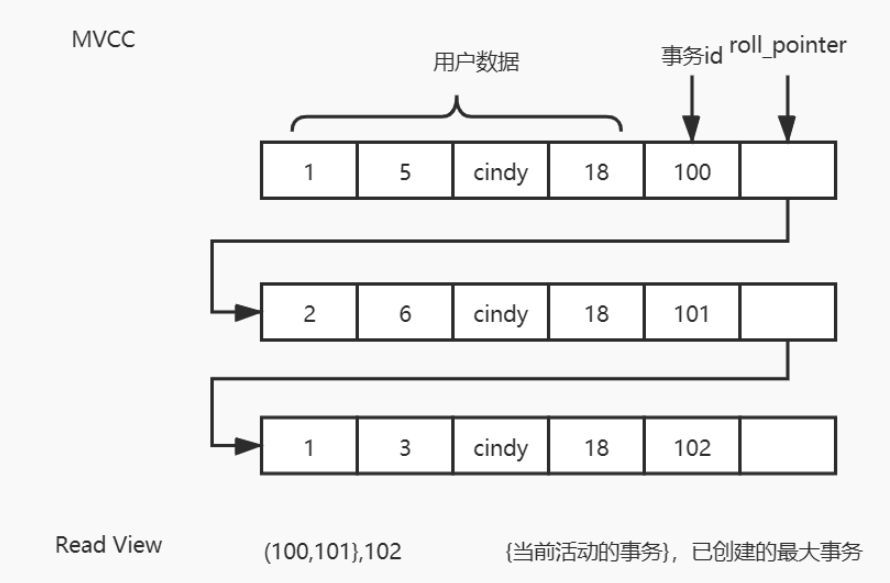
我们在开启事务时创建ReadView,ReadView维护了当前活动的事务ID,即未提交的正在进行中的事务ID,排序生成一个数组访问数据,获取需要修改的记录中的事务ID(获取的是事务ID最大的记录),然后去对比ReadView:
- 如果获取的事务ID在ReadView的左边(比ReadView都小),表示可以访问(在左边意味着该事务已经提交)。
- 如果获取的事务ID在ReadView的右边(比ReadView都大),或者就在ReadView中,表示不可以访问,获取roll_pointer,取上一版本重新对比(在右边意味着,该事务在ReadView生成之后出现,在ReadView中意味着该事务还未提交)。
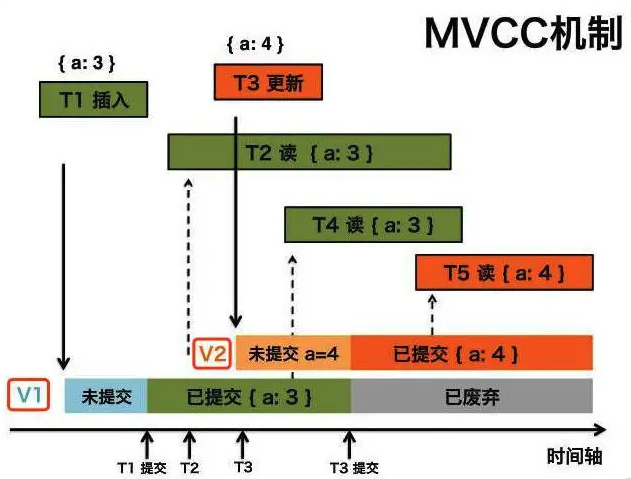
已提交读隔离级别下的事务在每次查询的开始都会生成一个独立的ReadView,也就是说我每次select查出来的ReadView都会重新生成,所以ReadView可能会不一样,就是说读到的数据就会不一样;
而可重复读隔离级别则在第一次读的时候生成一个ReadView,之后的读都复用之前的ReadView,每次select查询都是一样的。
在这里咱们发现了这两者的性能是有差别的,MySQL为了提高查询性能,默认使用了可重复读这种隔离级别(原因之一)。
这就是MySQL的MVCC,通过版本链,实现多版本可并发读-写、写-读,通过ReadView生成策略的不同实现不同的隔离级别。
Durability持久性保障
事务的持久性指的是只要事务成功结束,它对数据库所做的更新就必须永久保存下来,即使发生系统崩溃,重新启动数据库系统后,数据库还能恢复到事务成功结束时的状态。
持久性意味着事务操作最终要持久化到数据库中,持久性是由 内存+redo log来保证的,MySQL的InnoDB在修改数据的时候,同时在内存和redo log记录这次操作,宕机的时候可以从redo log中恢复数据。
同时,我们都知道MySQL Server的主从同步就是通过binlog来实现的,从服务器通过binlog文件的SQL拿过去执行一遍,保证跟主服务器的数据一致,而binlog和redo log都存储了表中的数据,都可以用来做数据恢复的,那怎么保证binlog和redo log的数据一致呢?
下面是InnoDB下redo log的过程:
- 对redo log进行写盘,写完后事务进入prepare状态。
- 如果前面prepare成功,马上就会进行binlog写盘,再继续将事务日志持久化到binlog。
- 如果binlog持久化成功,那么事务则进入commit状态(在redo log里面写一条commit记录)。
这意味着一个事务到底有没有成功,由两方面来保证:第一是redo log里面有没有commit记录,如果有commit记录,那么binlog一定是持久化成功了,也就是说事务成功了。
再者就是redo log最终还会进行刷盘,它的刷盘会在系统空闲时进行,并不是写到redo log时马上进行刷盘。
以上就是数据库的基本特性ACID在MySQL中如何进行保证的方法,ACID就是这样通过InnoDB的几个日志和MVCC来保证原子性、一致性、隔离性、持久化的。
最后,再问大家一个问题:MySQL是先设计ACID特性才有的底层实现,还是先实现了底层才总结出ACID特性的呢?