是否能学习分区表的方式,从逻辑上对单表进行分区,从而加快删除的速度?说到此处,我们先来回顾下单表的物理存储结构:段–区–块。区是段的最小分配单元,一个区又包含多个块,那么能否利用区或块的物理特性来模拟分区呢?笔者尝试使用区来做分区,为什么不用块呢?因为一个数据库块能存储的数据量不超过1000行,故被排除。
我们利用ROWID对每一行进行按区分片,此处引入了Oracle内部函数dbms_rowid.rowid_create帮助我们按区进行ROWID分片,代码如下:
SQL> select A.FILE_ID,
A.EXTENT_ID,
A.BLOCK_ID,
A.BLOCKS,
' rowid between ' || '''' ||
dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id,
0) || '''' || ' and ' || '''' ||
dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id + blocks - 1,
999) || ''';'
from dba_extents a, dba_objects b
where a.segment_name = b.object_name
and a.owner = b.owner
and b.object_name = 'JASON'
and b.owner = 'SCOTT'
order by a.relative_fno, a.block_id;
按区分片后的信息输出如下图所示。
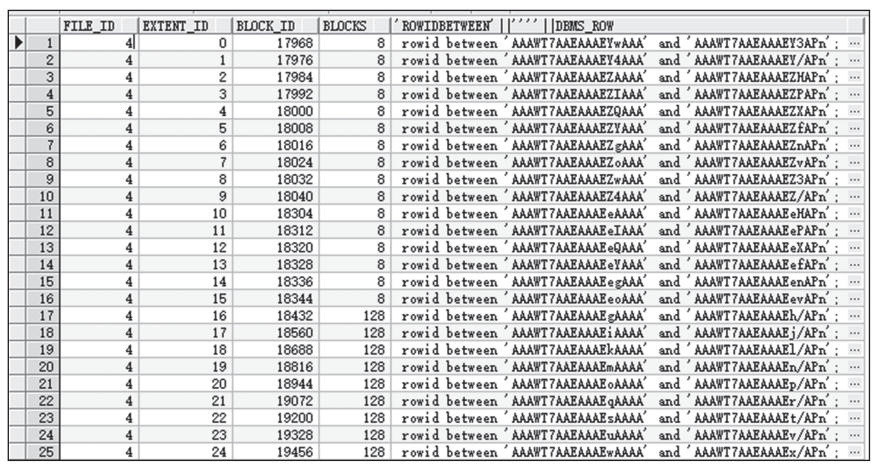
图 按区分片后的信息输出
有了以上的分片信息,我们只需要带入需要筛选的条件,使用匿名块批量删除即可,具体实现方式如下:
SQL> declare
cursor cur_rowid is
select dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id,
0) begin_rowid,
dbms_rowid.rowid_create(1,
b.data_object_id,
a.relative_fno,
a.block_id + blocks - 1,
999) end_rowid
from dba_extents a, dba_objects b
where a.segment_name = b.object_name
and a.owner = b.owner
and b.object_name = 'JASON'
and b.owner = 'SCOTT'
order by a.relative_fno, a.block_id;
r_sql varchar2(4000);
begin
FOR cur in cur_rowid LOOP
r_sql := 'delete SCOTT.jason where OBJECT_TYPE=' || '''' || 'INDEX' || '''' ||
' and rowid between :1 and :2';
EXECUTE IMMEDIATE r_sql
using cur.begin_rowid, cur.end_rowid;
COMMIT;
END LOOP;
end;
在具体的实现过程中,大家只需要替换对应的SQL语句及用户名对象即可。
虽然按区构造ROWID分片进行删除,效率上比单纯的delete提高了好几倍,但整个执行过程并不是并行的,需要在不同的窗口进行人工操作,实现过程较为烦琐。那么还有没有更高效的方式呢?
Oracle从11g R2版本开始推出了DBMS_PARALLEL_EXECUTE包,能够高效地对大表进行DML操作。可以自定义并行度这一特点,使得DBMS_PARALLEL_EXECUTE包成为了最优的选择。实现代码如下:
SQL> SET SERVEROUTPUT ON
SQL> BEGIN
DBMS_PARALLEL_EXECUTE.DROP_TASK ('test_task');
EXCEPTION WHEN OTHERS THEN
NULL;
END;
/
SQL> DECLARE
l_task VARCHAR2(30) := 'test_task';
l_sql_stmt VARCHAR2(32767);
l_try NUMBER;
l_status NUMBER;
BEGIN
-- Create the TASK
DBMS_PARALLEL_EXECUTE.CREATE_TASK (task_name => l_task);
-- Chunk the table by the ROWID
DBMS_PARALLEL_EXECUTE.CREATE_CHUNKS_BY_ROWID
(
TASK_NAME => l_task,
TABLE_OWNER => 'JOE', <<<用户名
TABLE_NAME => 'OB2', <<<表名
BY_ROW => TRUE, <<<值为TRUE,表示chunk_size为行数,否则表示块数
CHUNK_SIZE => 2500 <<<自定义chunk的大小,这里表示2500行为一个chunk
);
-- DML to be execute in parallel
l_sql_stmt := 'delete OB2 where object_type = ''SYNONYM'' and rowid BETWEEN
:start_id AND :end_id'; <<<想要执行的SQL语句
-- Run the task
DBMS_PARALLEL_EXECUTE.RUN_TASK
(
TASK_NAME => l_task,
SQL_STMT => l_sql_stmt,
LANGUAGE_FLAG => DBMS_SQL.NATIVE,
PARALLEL_LEVEL => 2 <<<自定义执行并行度
);
-- If there is error, RESUME it for at most 2 times.
l_try := 0;
l_status := DBMS_PARALLEL_EXECUTE.TASK_STATUS(l_task);
WHILE(l_try < 2 and l_status != DBMS_PARALLEL_EXECUTE.FINISHED)
LOOP
l_try := l_try + 1;
DBMS_PARALLEL_EXECUTE.RESUME_TASK(l_task);
l_status := DBMS_PARALLEL_EXECUTE.TASK_STATUS(l_task);
END LOOP;
-- Done with processing; drop the task
DBMS_PARALLEL_EXECUTE.DROP_TASK(l_task);
EXCEPTION WHEN OTHERS THEN
DBMS_OUTPUT.PUT_LINE('Error in the code :' || SQLERRM);
END;
/
如上述脚本所示,DBMS_PARALLEL_EXECUTE包的使用方法较为简单,只需要修改标红的备注部分即可执行。以上这个脚本是通过ROWID进行切割的,当然切割表的方法还有另外两种,一是通过指定字段CREATE_CHUNKS_BY_NUMBER_COL来切割,二是通过自己指定SQL语句CREATE_CHUNKS_BY_SQL来切割,这里就不详细说明了,大家如想进一步了解,可自行搜索相关资料。
DBMS_PARALLEL_EXECUTE的基本原理是将一个大表以指定的块大小(chunk size)进行分片(chunk size 可以指定行数或块数),然后对多个分片进行并行删除(delete)或其他DML操作,每一个分片完成后立即提交,最后通过调用job进行并发控制操作。
所以,如果想要调用DBMS_PARALLEL_EXECUTE包,除了拥有此包的访问权限之外,还必须要有创建job的权限。
DBMS_PARALLEL_EXECUTE包的基本执行流程具体如下。
1)调用create_task(),创建任务(task)。
2)调用create_chunk_by_rowid(),创建分块规则。
3)编写自己需要执行的DML操作语句。
4)调用run_task(),运行任务。
5)调用drop_task(),即任务执行完成后,删除任务。
DBMS_PARALLEL_EXECUTE包涉及的相关视图如下:
DBA_PARALLEL_EXECUTE_TASKS
DBA_PARALLEL_EXECUTE_CHUNKS
dba_scheduler_jobs
在任务的执行过程中,可以通过上述视图实时监控任务的执行情况。
本文摘编于《DBA攻坚指南:左手Oracle,右手MySQL》,经出版方授权发布。(ISBN:9787111684336)转载请保留文章出处。