在移动互联网的业务场景中,数据量很大,我们需要保存这样的信息:一个 key 关联了一个数据集合,同时对这个数据集合做统计。
- 统计一个 APP 的日活、月活数;
- 统计一个页面的每天被多少个不同账户访问量(Unique Visitor,UV));
- 统计用户每天搜索不同词条的个数;
- 统计注册 IP 数。
通常情况下,我们面临的用户数量以及访问量都是巨大的,比如百万、千万级别的用户数量,或者千万级别、甚至亿级别的访问信息。
今天「码哥」分别使用不同的数据类型来实现统计一个页面的每天被多少个不同账户访问量这个功能,循序渐进的引出 HyperLogLog的原理与 Java 中整合 Redission 实战。
告诉大家一个技巧,Redis 官方网站现在能在线运行 Redis 指令了:https://redis.io/。如图:
Redis 在线运行
使用 Set 实现
一个用户一天内多次访问一个网站只能算作一次,所以很容易就想到通过 Redis 的 Set 集合来实现。
比如微信 ID 为「肖菜鸡」访问 「Redis 为什么这么快」这篇文章时,我们把这个信息存到 Set 中。
SADD Redis为什么这么快:uv 肖菜鸡 谢霸哥 肖菜鸡
(integer) 1
「肖菜鸡」多次访问「Redis 为什么这么快」页面,Set 的去重功能保证不会重复记录同一个「微信 ID」。
通过 SCARD 命令,统计「Redis 为什么这么快」页面 UV。指令返回一个集合的元素个数(也就是用户 ID)。
SCARD Redis为什么这么快:uv
(integer) 2
使用 Hash 实现
码老湿,还可以利用 Hash 类型实现,将用户 ID 作为 Hash 集合的 key,访问页面则执行 HSET 命令将 value 设置成 1。
即使「肖菜鸡」重复访问页面,重复执行命令,也只会把 key 等于「肖菜鸡」的 value 设置成 1。
最后,利用 HLEN 命令统计 Hash 集合中的元素个数就是 UV。
如下:
HSET Redis为什么这么快 肖菜鸡 1
// 统计 UV
HLEN Redis为什么这么快
使用 Bitmap 实现
Bitmap 的底层数据结构用的是 String 类型的 SDS 数据结构来保存位数组,Redis 把每个字节数组的 8 个 bit 位利用起来,每个 bit 位 表示一个元素的二值状态(不是 0 就是 1)。
Bitmap 提供了 GETBIT、SETBIT 操作,通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行读写操作,需要注意的是 offset 从 0 开始。
可以将 Bitmap 看成是一个 bit 为单位的数组,数组的每个单元只能存储 0 或者 1,数组的下标在 Bitmap 中叫做 offset 偏移量。
为了直观展示,我们可以理解成 buf 数组的每个字节用一行表示,每一行有 8 个 bit 位,8 个格子分别表示这个字节中的 8 个 bit 位,如下图所示:
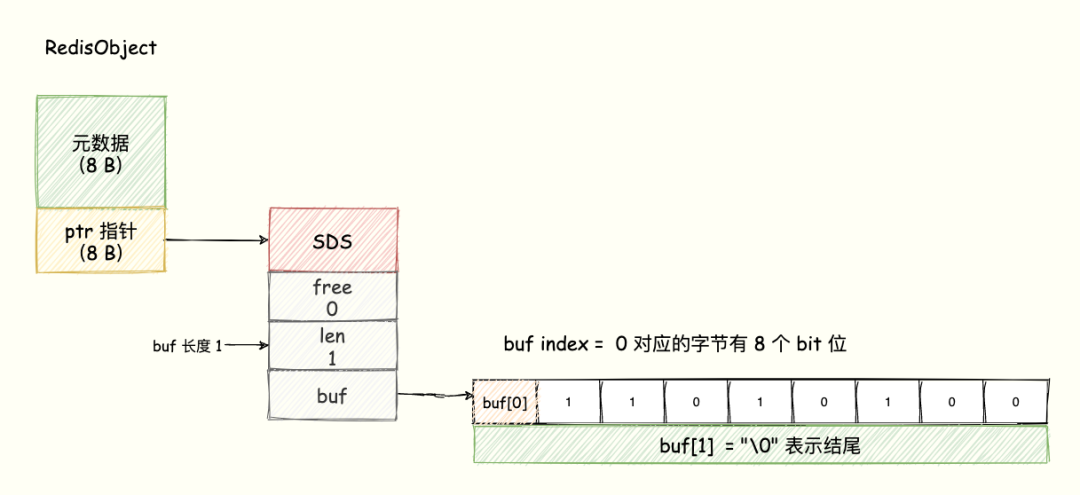
Bitmap
8 个 bit 组成一个 Byte,所以 Bitmap 会极大地节省存储空间。 这就是 Bitmap 的优势。
如何使用 Bitmap 来统计页面的独立用户访问量呢?
Bitmap 提供了 SETBIT 和 BITCOUNT 操作,前者通过一个偏移值 offset 对 bit 数组的 offset 位置的 bit 位进行写操作,需要注意的是 offset 从 0 开始。
后者统计给定指定的 bit 数组中,值 = 1 的 bit 位的数量。
需要注意的事,我们需要把「微信 ID」转换成数字,因为offset 是下标。
假设我们将「肖菜鸡」转换成编码6。
第一步,执行下面指令表示「肖菜鸡」的编码为 6 并 访问「巧用 Redis 数据类型实现亿级数据统计」这篇文章。
SETBIT 巧用Redis数据类型实现亿级数据统计 6 1
第二步,统计页面访问次数,使用 BITCOUNT 指令。该指令用于统计给定的 bit 数组中,值 = 1 的 bit 位的数量。
BITCOUNT 巧用Redis数据类型实现亿级数据统计
HyperLogLog 王者
Set 虽好,如果文章非常火爆达到千万级别,一个 Set 就保存了千万个用户的 ID,页面多了消耗的内存也太大了。
同理,Hash 数据类型也是如此。
至于 Bitmap,它更适合于「二值状态统计」的使用场景,统计精度高,虽然内存占用要比HashMap少,但是对于大量数据还是会占用较大内存。
咋办呢?
这些就是典型的「基数统计」应用场景,基数统计:统计一个集合中不重复元素的个数。
HyperLogLog 的优点在于它所需的内存并不会因为集合的大小而改变,无论集合包含的元素有多少个,HyperLogLog 进行计算所需的内存总是固定的,并且是非常少的。
每个 HyperLogLog 最多只需要花费 12KB 内存,在标准误差 0.81%的前提下,就可以计算 2 的 64 次方个元素的基数。
Redis 实战
HyperLogLog 使用太简单了。PFADD、PFCOUNT、PFMERGE三个指令打天下。
PFADD
将访问页面的每个用户 ID 添加到 HyperLogLog 中。
PFADD Redis主从同步原理:uv userID1 userID 2 useID3
PFCOUNT
利用 PFCOUNT 获取 「Redis 主从同步原理」文章的 UV 值。
PFCOUNT Redis主从同步原理:uv
PFMERGE 使用场景
HyperLogLog 除了上面的 PFADD 和 PFCOIUNT 外,还提供了 PFMERGE
语法
PFMERGE destkey sourcekey [sourcekey ...]
比如在网站中我们有两个内容差不多的页面,运营说需要这两个页面的数据进行合并。
其中页面的 UV 访问量也需要合并,那这个时候 PFMERGE 就可以派上用场了,也就是同样的用户访问这两个页面则只算做一次。
如下所示:Redis、MySQL 两个 HyperLogLog 集合分别保存了两个页面用户访问数据。
PFADD Redis数据 user1 user2 user3
PFADD MySQL数据 user1 user2 user4
PFMERGE 数据库 Redis数据 MySQL数据
PFCOUNT 数据库 // 返回值 = 4
将多个 HyperLogLog 合并(merge)为一个 HyperLogLog , 合并后的 HyperLogLog 的基数接近于所有输入 HyperLogLog 的可见集合(observed set)的并集。
user1、user2 都访问了 Redis 和 MySQL,只算访问了一次。
Redission 实战
详细源码「码哥」上传到 GitHub 了:https://github.com/MageByte-Zero/springboot-parent-pom.git。
pom 依赖
<dependency>
<groupId>org.redisson</groupId>
<artifactId>redisson-spring-boot-starter</artifactId>
<version>3.16.7</version>
</dependency>
添加数据到 Log
// 添加单个元素
public <T> void add(String logName, T item) {
RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName);
hyperLogLog.add(item);
}
// 将集合数据添加到 HyperLogLog
public <T> void addAll(String logName, List<T> items) {
RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName);
hyperLogLog.addAll(items);
}
合并
/**
* 将 otherLogNames 的 log 合并到 logName
*
* @param logName 当前 log
* @param otherLogNames 需要合并到当前 log 的其他 logs
* @param <T>
*/
public <T> void merge(String logName, String... otherLogNames) {
RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName);
hyperLogLog.mergeWith(otherLogNames);
}
统计基数
public <T> long count(String logName) {
RHyperLogLog<T> hyperLogLog = redissonClient.getHyperLogLog(logName);
return hyperLogLog.count();
}单元测试
@Slf4j
@RunWith(SpringRunner.class)
@SpringBootTest(classes = RedissionApplication.class)
public class HyperLogLogTest {
@Autowired
private HyperLogLogService hyperLogLogService;
@Test
public void testAdd() {
String logName = "码哥字节:Redis为什么这么快:uv";
String item = "肖菜鸡";
hyperLogLogService.add(logName, item);
log.info("添加元素[{}]到 log [{}] 中。", item, logName);
}
@Test
public void testCount() {
String logName = "码哥字节:Redis为什么这么快:uv";
long count = hyperLogLogService.count(logName);
log.info("logName = {} count = {}.", logName, count);
}
@Test
public void testMerge() {
ArrayList<String> items = new ArrayList<>();
items.add("肖菜鸡");
items.add("谢霸哥");
items.add("陈小白");
String otherLogName = "码哥字节:Redis多线程模型原理与实战:uv";
hyperLogLogService.addAll(otherLogName, items);
log.info("添加 {} 个元素到 log [{}] 中。", items.size(), otherLogName);
String logName = "码哥字节:Redis为什么这么快:uv";
hyperLogLogService.merge(logName, otherLogName);
log.info("将 {} 合并到 {}.", otherLogName, logName);
long count = hyperLogLogService.count(logName);
log.info("合并后的 count = {}.", count);
}
}
基本原理
HyperLogLog 是一种概率数据结构,它使用概率算法来统计集合的近似基数。而它算法的最本源则是伯努利过程。
伯努利过程就是一个抛硬币实验的过程。抛一枚正常硬币,落地可能是正面,也可能是反面,二者的概率都是 1/2 。
伯努利过程就是一直抛硬币,直到落地时出现正面位置,并记录下抛掷次数k。
比如说,抛一次硬币就出现正面了,此时 k 为 1; 第一次抛硬币是反面,则继续抛,直到第三次才出现正面,此时 k 为 3。
对于 n 次伯努利过程,我们会得到 n 个出现正面的投掷次数值 k1, k2 ... kn, 其中这里的最大值是 k_max。
根据一顿数学推导,我们可以得出一个结论:2^{k_ max} 来作为 n 的估计值。
也就是说你可以根据最大投掷次数近似的推算出进行了几次伯努利过程。
所以 HyperLogLog 的基本思想是利用集合中数字的比特串第一个 1 出现位置的最大值来预估整体基数,但是这种预估方法存在较大误差,为了改善误差情况,HyperLogLog 中引入分桶平均的概念,计算 m 个桶的调和平均值。
Redis 中 HyperLogLog 一共分了 2^14 个桶,也就是 16384 个桶。每个桶中是一个 6 bit 的数组,如下图所示。
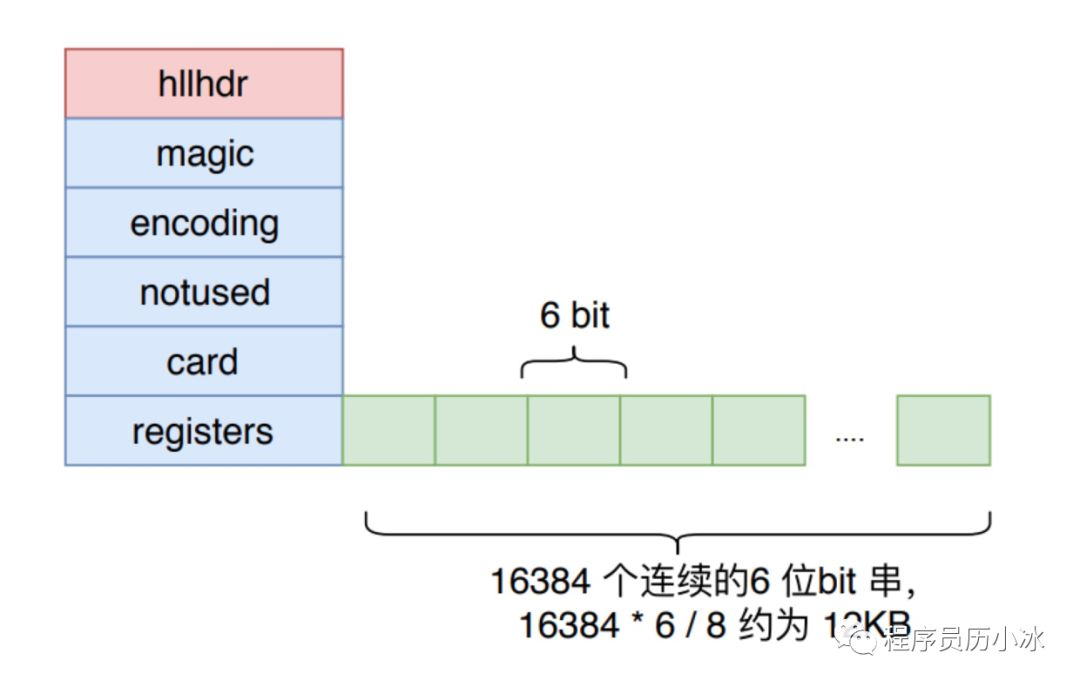
图片来源:程序员历小冰
关于 HyperLogLog 的原理过于复杂,如果想要了解的请移步:
- https://www.zhihu.com/question/53416615
- https://en.wikipedia.org/wiki/HyperLogLog
- 用户日活月活怎么统计 - Redis HyperLogLog 详解
Redis 对 HyperLogLog 的存储进行了优化,在计数比较小的时候,存储空间采用系数矩阵,占用空间很小。
只有在计数很大,稀疏矩阵占用的空间超过了阈值才会转变成稠密矩阵,占用 12KB 空间。
为何只需要 12 KB 呀?
HyperLogLog 实现中用到的是 16384 个桶,也就是 2^14,每个桶的 maxbits 需要 6 个 bits 来存储,最大可以表示 maxbits=63,于是总共占用内存就是2^14 * 6 / 8 = 12k字节。
总结
分别使用了 Hash、Bitmap、HyperLogLog 来实现:
- Hash:算法简单,统计精度高,少量数据下使用,对于海量数据会占据大量内存;
- Bitmap:位图算法,适合用于「二值统计场景」,具体可参考我这篇文章,对于大量不同页面数据统计还是会占用较大内存。
- Set:利用去重特性实现,一个 Set 就保存了千万个用户的 ID,页面多了消耗的内存也太大了。
在 Redis 里面,每个 HyperLogLog 键只需要花费 12 KB 内存,就可以计算接近2^64 个不同元素的基数。
因为 HyperLogLog 只会根据输入元素来计算基数,而不会储存输入元素本身,所以 HyperLogLog 不能像集合那样,返回输入的各个元素。
- HyperLogLog是一种算法,并非 Redis 独有。
- 目的是做基数统计,故不是集合,不会保存元数据,只记录数量而不是数值。
- 耗空间极小,支持输入非常体积的数据量。
- 核心是基数估算算法,主要表现为计算时内存的使用和数据合并的处理。最终数值存在一定误差。
- Redis中每个Hyperloglog key 占用了 12K 的内存用于标记基数(官方文档)。
- pfadd 命令并不会一次性分配 12k 内存,而是随着基数的增加而逐渐增加内存分配;而 pfmerge 操作则会将 sourcekey 合并后存储在 12k 大小的 key 中,由hyperloglog合并操作的原理(两个Hyperloglog合并时需要单独比较每个桶的值)可以很容易理解。
- 误差说明:基数估计的结果是一个带有 0.81% 标准错误(standard error)的近似值。是可接受的范围Redis 对 HyperLogLog 的存储进行优化,在计数比较小时,存储空间采用稀疏矩阵存储,空间占用很小,仅仅在计数慢慢变大,稀疏矩阵占用空间渐渐超过了阈值时才会一次性转变成稠密矩阵,才会占用 12k 的空间。