统计网站:https://mlcontests.com/作者得出了几个重要结论:
1、在所有竞赛中,Kaggle上的竞赛数量仍然占据1/3,而且奖金数量占270万美元总奖金池的一半;
2、在所有比赛中,有67场比赛是在前5大平台(Kaggle、AIcrowd、Tianchi、DrivenData 和 Zindi)上举行的,有8场比赛是在去年只举办了一场比赛的平台上举行的;
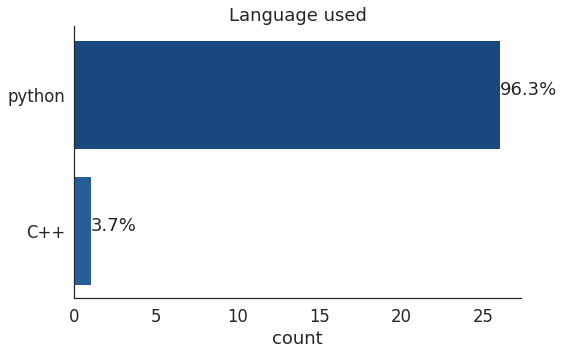
3、几乎所有的冠军都使用了Python,只有一个冠军使用了C++;
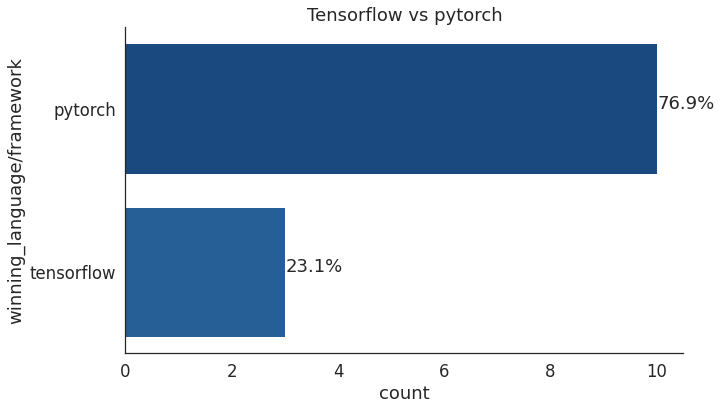
4、77%的深度学习解决方案使用了PyTorch(去年高达72%);
5、所有获奖的CNN解决方案都使用了CNN;
6、所有获奖的NLP解决方案都使用了Transformer。
以下是这次调查的详细信息:
平台类型
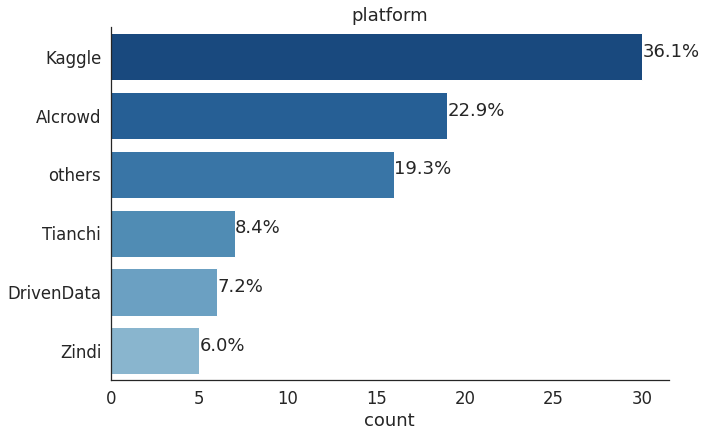
在本次调查中,作者总共统计了16个平台上的83场竞赛。这些竞赛的总奖金池超过270万美元,其中奖金最丰厚的比赛是由Driven data举办的Facebook AI Image Similarity Challenge: Matching Track,奖金高达20万美元。
竞赛类型
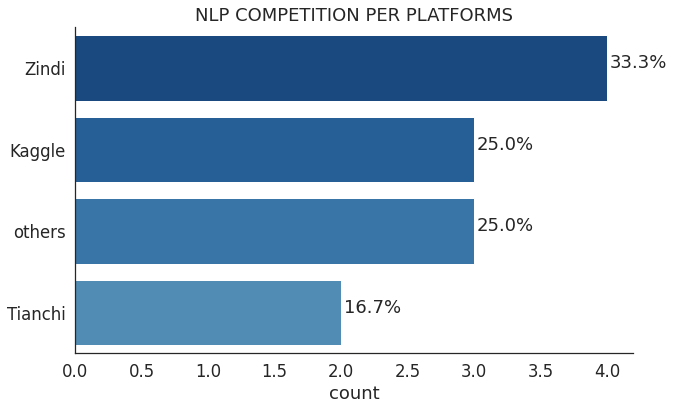
此次调查显示,2021年最常见的竞赛类型是计算机视觉和自然语言处理。与2020年相比,这部分变化很大,当时NLP竞赛仅占竞赛总数的7.5%。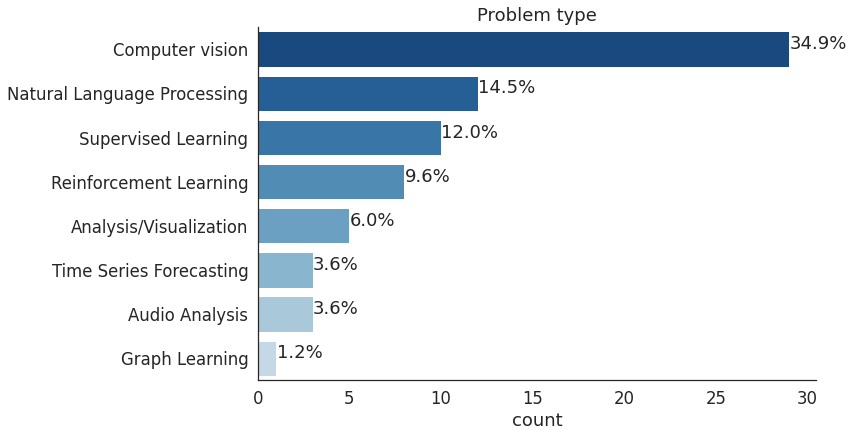
在众多NLP竞赛中,Zindi与AI4D(Artificial Intelligence for Development Africa)合作举办的竞赛数量最多,比赛内容包括将一种非洲语言翻译成英语或其他语言以及针对一种非洲语言进行情感分析。
语言与框架
在这次调查中,主流的机器学习框架依然是基于Python的。Scikit-learn非常通用,几乎被用于每个领域。
不出所料,两个最流行的机器学习库是Tensorflow和Pytorch。其中,Pytorch在深度学习比赛中最受欢迎。与2020年相比,在深度学习竞赛中使用PyTorch的人数突飞猛进,PyTorch框架每年都在快速发展。
冠军模型
监督学习
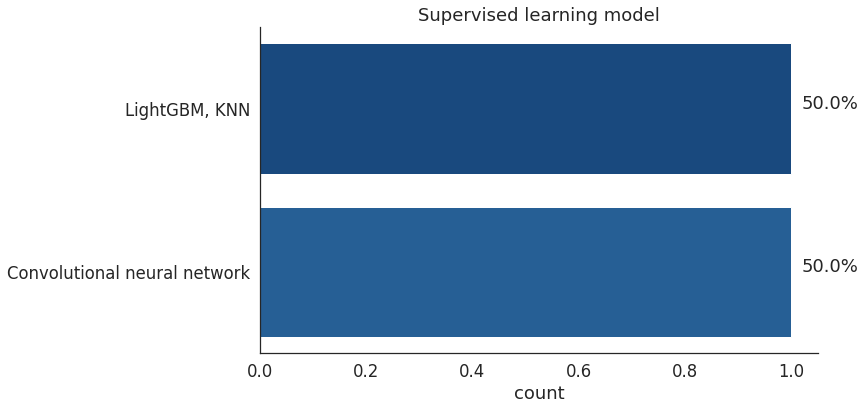
在经典机器学习问题中,Catboost、LightGBM等梯度提升模型占据主流。举个例子,在一个室内定位和导航的Kaggle竞赛中,选手需要设计算法,基于实时传感器数据预测智能手机在室内的位置。冠军解决方案考虑了三种建模方法:神经网络、LightGBM和K-Nearest Neighbors。但在最后的pipeline中,他们只用LightGBM和K-Nearest Neighbours达到了最高分。
计算机视觉
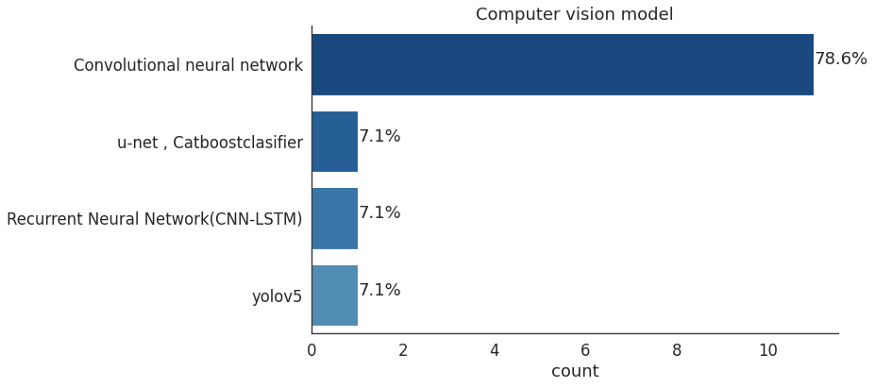
自从AlexNet在2012年赢得ImageNet竞赛以来,CNN算法已经成为很多深度学习问题都在用的算法,特别是在计算机视觉方面。
循环神经网络和卷积神经网络并不相互排斥。尽管它们似乎被用来解决不同的问题,但重要的是这两个架构都可以处理某些类型的数据。例如,RNN使用序列作为输入。值得注意的是,序列并不局限于文本或音乐。视频是图像的集合,也可以用作序列。循环神经网络,如LSTM,被用于数据具有时间特征的情况(如时间序列),以及数据上下文敏感的情况(如句子补全),其中反馈循环的记忆功能是达到理想性能的关键。RNN还在计算机视觉的下列领域中得到了成功的应用:
- 「日间图片」与「夜间图片」是图像分类的一个例子(一对一RNN);
- 图像描述(一对多RNN)是根据图像的内容为图像分配标题的过程,例如「狮子猎鹿」;
- 手写体识别;
最后,RNN和CNN的结合是可能的,这可能是计算机视觉的最先进的应用。当数据适合CNN,但包含时间特征时,混合RNN和CNN的技术可能是有利的策略。
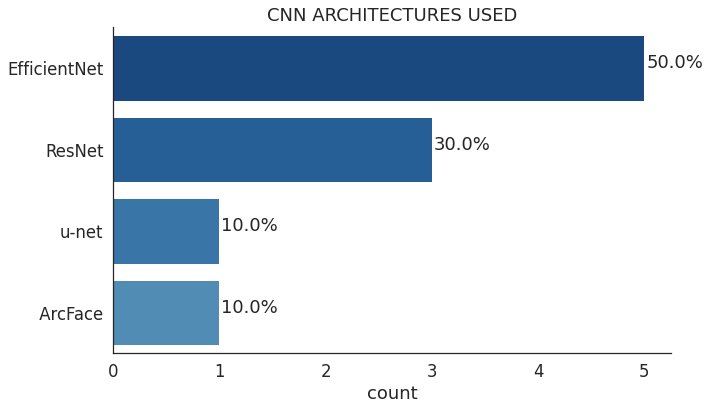
在其他架构中,EfficientNet脱颖而出,因为它专注于提高模型的准确性和效率。EfficientNet使用一种简单而有效的技术——复合系数(compound coefficient)来放大模型,使用缩放策略创建了7个不同维度的模型,其精度超过了大多数卷积神经网络的SOTA水平。
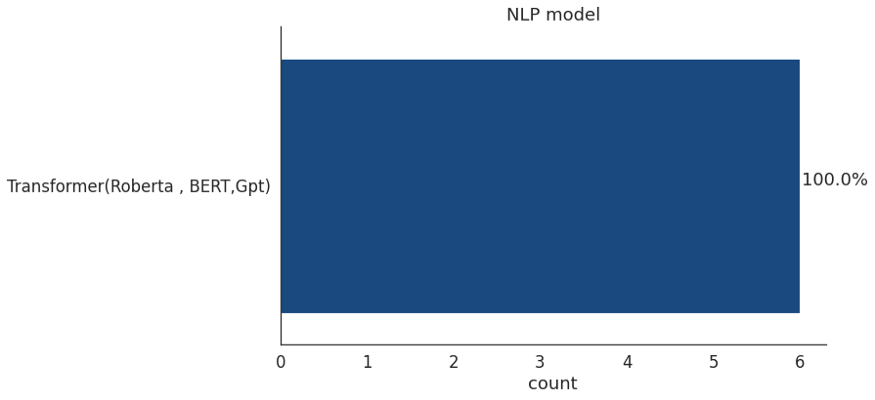
NLP
像2020年一样,2021年NLP领域大型语言模型(如Transformer)的采用比例显著增加,创历史新高。作者找到了大约6个NLP解决方案,它们全都基于transformer。
获胜团队情况
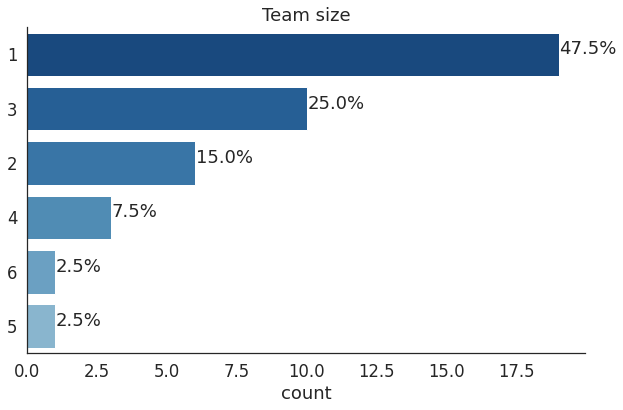
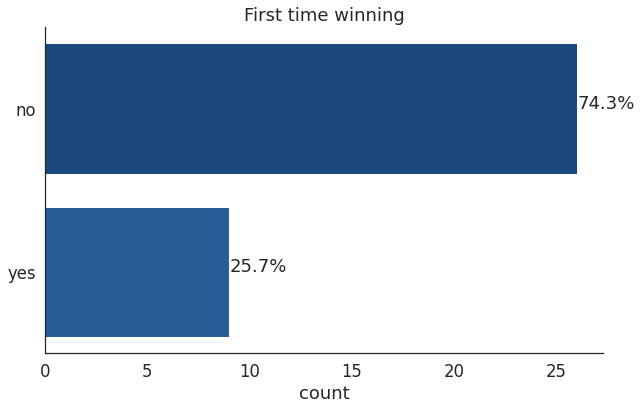
作者在数据集中追踪了35场比赛的获胜者。其中,只有9人之前从未在比赛中获奖。与2020年相比,可以看到赢得很多比赛的老参与者一次又一次获胜,只有少数几人首次得奖,在百分比上没有真正明显的变化。
优势方案
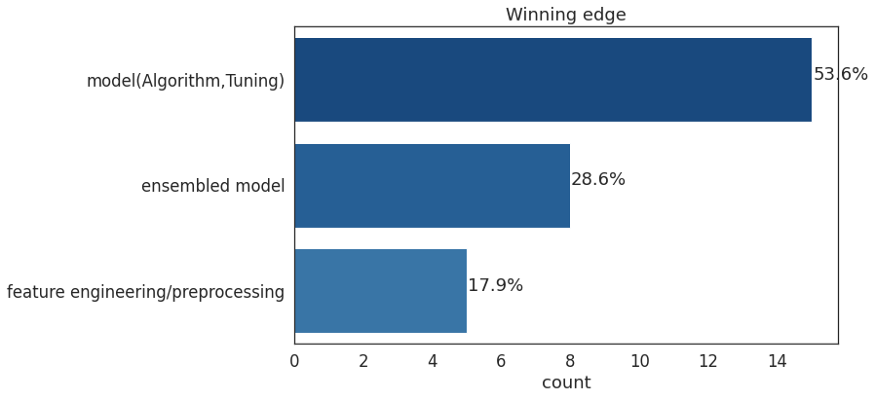
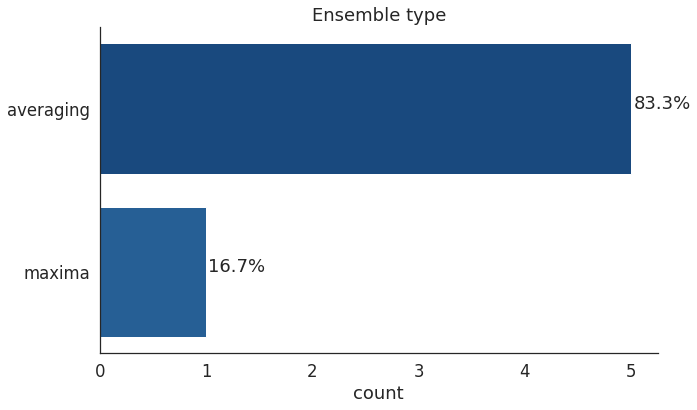
在机器学习竞赛的优胜方案中,集成模型成为了首选方法之一。集成方法中最常用的方法是求平均,即构建多个模型并通过将输出和的平均值相加将其组合在一起,从而达到更稳健的性能。
在调整一个模型时,一旦你达到了一个收益率下降的点,通常最好重新开始构建一个产生不同类型错误的新模型,并将它们的预测求平均。
集成方法应用示例
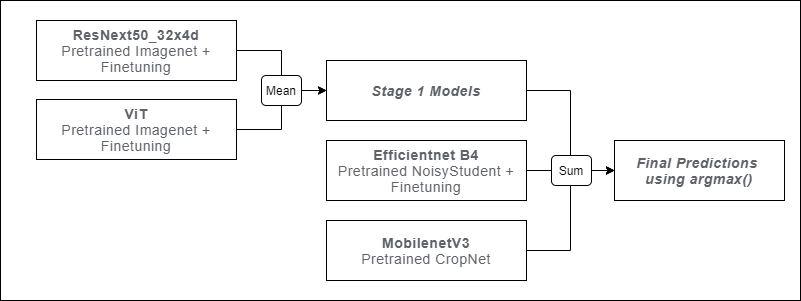
在一个kaggle「木薯叶病分类」比赛中,选手要将木薯叶子图像分类为健康或四类疾病。冠军解决方案包括4个不同的模型CropNet、EfficientNet B4、ResNext50和Vit,并采用了平均方法。
获胜者从ResNext和ViT模型中取类权重的平均值,并在第二阶段将这种组合与MobileNet和EfficientnetB4结合。