架构前几天一个小伙子向我吐槽,准备了好久的面试,没想到问了一个HashMap就结束了,之后大概了解了一下面试过程。其实前几年对于HashMap,大家问的还是比较简单的,随着大家水平的提高,这种简单的问题已经拦不住大家了。
那么开始问一些经常被忽视比较关键的小细节,开始卷起来,比如说HashMap创建的时候,要不要指定容量?如果要指定的话,多少是合适的?为什么?如果我有100个hashcode 不同的元素需要放在HashMap 中,初始值设置100合适吗?
要设置HashMap的初始化容量吗?设置多少合适呢?
如果我们没有设置初始容量大小,随着元素的不断增加,HashMap会发生多次扩容,而HashMap中的扩容机制决定了每次扩容都需要重建hash表,是非常影响性能的。我们可以看看resize()代码:
final Node<K,V>[] resize() {
Node<K,V>[] oldTab = table;//首次初始化后table为Null
int oldCap = (oldTab == null) ? 0 : oldTab.length;
int oldThr = threshold;//默认构造器的情况下为0
int newCap, newThr = 0;
if (oldCap > 0) {//table扩容过
//当前table容量大于最大值得时候返回当前table
if (oldCap >= MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return oldTab;
}
else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY &&
oldCap >= DEFAULT_INITIAL_CAPACITY)
//table的容量乘以2,threshold的值也乘以2
newThr = oldThr << 1; // double threshold
}
else if (oldThr > 0) // initial capacity was placed in threshold
//使用带有初始容量的构造器时,table容量为初始化得到的threshold
newCap = oldThr;
else { //默认构造器下进行扩容
// zero initial threshold signifies using defaults
newCap = DEFAULT_INITIAL_CAPACITY;
newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY);
}
if (newThr == 0) {
//使用带有初始容量的构造器在此处进行扩容
float ft = (float)newCap * loadFactor;
newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ?
(int)ft : Integer.MAX_VALUE);
}
threshold = newThr;
@SuppressWarnings({"rawtypes","unchecked"})
Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap];
table = newTab;
if (oldTab != null) {
for (int j = 0; j < oldCap; ++j) {
HashMap.Node<K,V> e;
if ((e = oldTab[j]) != null) {
// help gc
oldTab[j] = null;
if (e.next == null)
// 当前index没有发生hash冲突,直接对2取模,即移位运算hash &(2^n -1)
// 扩容都是按照2的幂次方扩容,因此newCap = 2^n
newTab[e.hash & (newCap - 1)] = e;
else if (e instanceof HashMap.TreeNode)
// 当前index对应的节点为红黑树,这里篇幅比较长且需要了解其数据结构跟算法,因此不进行详解,当树的个数小于等于UNTREEIFY_THRESHOLD则转成链表
((HashMap.TreeNode<K,V>)e).split(this, newTab, j, oldCap);
else { // preserve order
// 把当前index对应的链表分成两个链表,减少扩容的迁移量
HashMap.Node<K,V> loHead = null, loTail = null;
HashMap.Node<K,V> hiHead = null, hiTail = null;
HashMap.Node<K,V> next;
do {
next = e.next;
if ((e.hash & oldCap) == 0) {
// 扩容后不需要移动的链表
if (loTail == null)
loHead = e;
else
loTail.next = e;
loTail = e;
}
else {
// 扩容后需要移动的链表
if (hiTail == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
}
} while ((e = next) != null);
if (loTail != null) {
// help gc
loTail.next = null;
newTab[j] = loHead;
}
if (hiTail != null) {
// help gc
hiTail.next = null;
// 扩容长度为当前index位置+旧的容量
newTab[j + oldCap] = hiHead;
}
}
}
}
}
return newTab;
}那么创建时到底指定多少合适呢?是不是用多少设置成多少呢?如果是这样还会这样问你吗。因为,当我们使用HashMap(int initialCapacity)来初始化容量的时候,HashMap并不会使用我们传进来的initialCapacity直接作为初始容量。
static final int tableSizeFor(int cap) {
int n = cap - 1;
n |= n >>> 1;
n |= n >>> 2;
n |= n >>> 4;
n |= n >>> 8;
n |= n >>> 16;
return (n < 0) ? 1 : (n >= MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : n + 1;
}所以当我们 初始化时:
new HashMap<>(cap)
JDK实际上是找到第一个比用户传入的值大的2的幂。
那么我们直接初始化为2的幂不就行了。那么也是不正确的,因为你忽略了一个因素:loadFactor。
loadFactor是负载因子,当HashMap中的元素个数(size)超过 threshold = loadFactor * capacity时,就会进行扩容。
也就是说,如果我们HashMap 中要保存7个元素,我们设置默认值为7后,JDK会默认处理为8。我们期望的是HashMap 在我们PUT 的时候不进行扩容,这样对性能就没有影响,但是事实不是这样的,这个HashMap在元素个数达到 8*0.75 = 6的时候就会进行一次扩容。
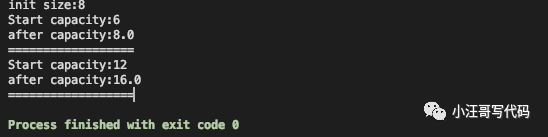
public static void main(String[] args) throws NoSuchFieldException, IllegalAccessException {
HashMap<String, Integer> hashMap = new HashMap<>(7);
Class clazz = HashMap.class;
// threshold是hashmap对象里的一个私有变量,若hashmap的size超过该数值,则扩容。这是通过反射获取该值
Field field = clazz.getDeclaredField("threshold");
field.setAccessible(true);
int threshold_begin = (int) field.get(hashMap);
System.out.println("init size:"+threshold_begin);
int threshold = 0;
for (int i = 0; i < 8; i++) {
hashMap.put(String.valueOf(i), 0);
if ((int) field.get(hashMap) != threshold) {
threshold = (int) field.get(hashMap);
System.out.println("Start capacity:"+threshold);
// 默认的负载因子是0.75,也就是说实际容量是/0.75
System.out.println("after capacity:"+(int) field.get(hashMap) / 0.75);
System.out.println("==================");
}
}
}
那么我们到底该怎么设置呢?其实可以参考JDK8中putAll方法中的实现:
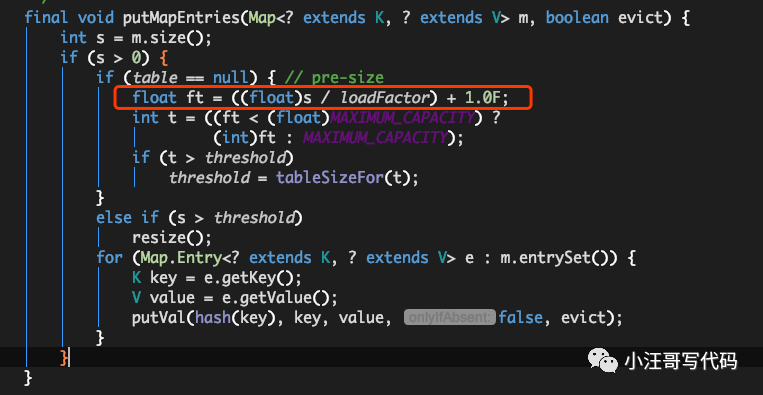
比如我们计划向HashMap中放入7个元素的时候,我们通过expectedSize / 0.75F + 1.0F计算,7/0.75 + 1 = 10 ,10经过JDK处理之后,会被设置成16,这就大大的减少了扩容的几率。但是会牺牲一些内存。
其实这个算法在guava 中已经有实现:
Map<String, String> map = Maps.newHashMapWithExpectedSize(7);
public static <K, V> HashMap<K, V> newHashMapWithExpectedSize(int expectedSize) {
return new HashMap(capacity(expectedSize));
}
static int capacity(int expectedSize) {
if (expectedSize < 3) {
CollectPreconditions.checkNonnegative(expectedSize, "expectedSize");
return expectedSize + 1;
} else {
return expectedSize < 1073741824 ? (int)((float)expectedSize / 0.75F + 1.0F) : 2147483647;
}
}其实这也就是一种内存换性能的做法,不过在目前的大环境中,算力成本的低廉和高网络带宽,使大部分开发人员在遇到性能问题时就无脑的通过增加服务器的CPU和内存来解决问题,其实一个大的优化都是通过一个个小优化累加起来的吧。不过现在来看问这些东西大部分还是为了筛选,金三银四祝大家面试顺利。