












本文转自雷锋网,如需转载请至雷锋网官网申请授权。
1.Scaling Transformers:让大型语言模型更易于管理
近年来,基于Transformer架构的大型神经网络,自然语言处理领域取得了巨大的进步。前几年在Reddit上发布大量灌水贴的thegentlemetre账号一周后才被人类发觉:这竟然是一个应用程序在“作怪”!它正是以被称为地表最强的语言模型GPT-3为基础开发的程序。
GPT-3作为一个大型语言模型,可以创作出整篇文章,即使把这些文章和人类写的文章相比较的话,都很难被区分出来。
但是这种“聪明”的模型却有一个弊端。
因为它的训练成本极高,不是每个人都有资源来训练这种大型模型。
那么如何让大型语言模型更易于管理以适用日常需要呢?
华沙大学,谷歌研究和OpenAI的学者们提出一个新的模型族-Scaling Transformers。

论文地址:https://arxiv.org/abs/2111.12763
文章提出了一种通过稀疏化网络中线性层的激活(前馈和 Q、K、V 投影)来训练大规模稀疏模型的方法。该方法特别吸引人,因为它似乎不需要任何特定于硬件或低级别的优化即可有效。控制器网络在激活时生成一个块式 one-hot 掩码,并根据此掩码动态选择后续层的权重。当扩大模型大小时,用稀疏层来有效扩展并执行非批次解码的速度比标准Transformer模型快的多。在参数数量相同的情况下,稀疏层足以获得与标准Transformer相同的困惑度。
2.文章解读
Fabio Chiusano在NLP上发表了对这篇论文的正面评价。Fabio Chiusano是Digitiamo 数据科学主管,也是人工智能领域的顶级媒体作家。AI科技评论对Chiusano的点评做了不改原意的整理:
Scaling Transformer 真的很有趣,因为当我们扩大模型大小时,它们允许有效地缩放语言模型并且比标准 Transformer 更快地执行非批处理解码。严谨地说:
- 我们称其
d 为 Transformer 模型的参数个数。 - 然后,一个标准的密集 Transformer 将需要近似
d^2计算来进行预测。 - 相反,稀疏的 Scaling Transformer 将需要近似
d^1.5计算。
如果说这样的改进看起来不明显,请考虑一下这d通常是一个非常高的数字,大约数十亿,实际上实验表明,Scaling Transformer 为单个令牌带来了近 20 倍的预测加速(从 3.690s 到 0.183 s) 关于具有 17B 个参数的密集 Transformer。注意:这些加速是针对未批量预测的。
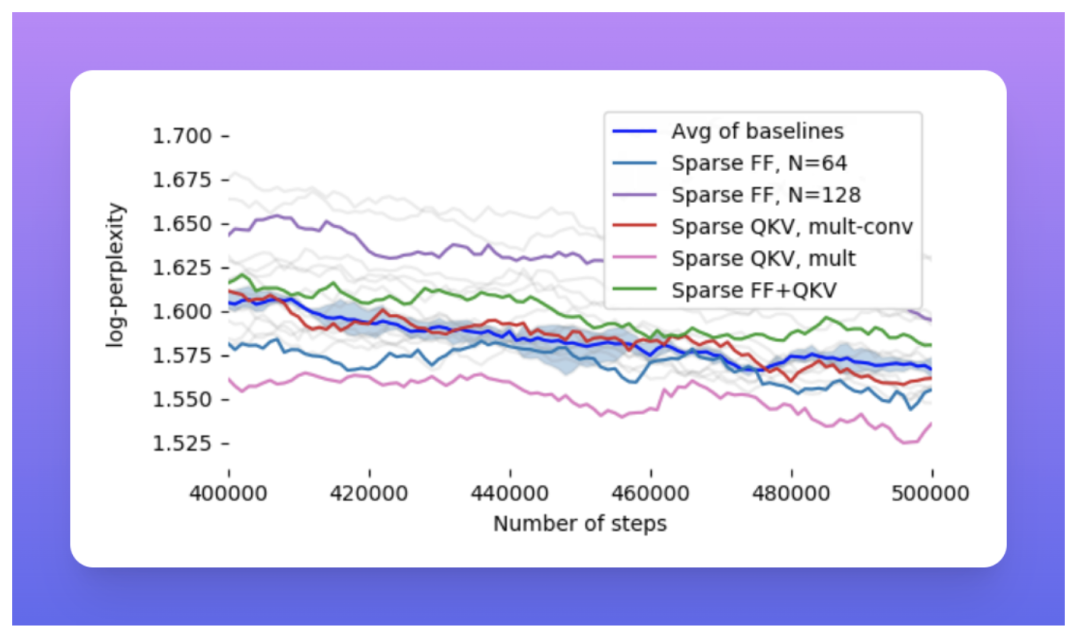
在具有建议的稀疏机制(FF、QKV、FF+QKV)的 C4 数据集上,Scaling Transformers(相当于 T5 大小,具有大约 800M 参数)的对数困惑度类似于基线密集模型。
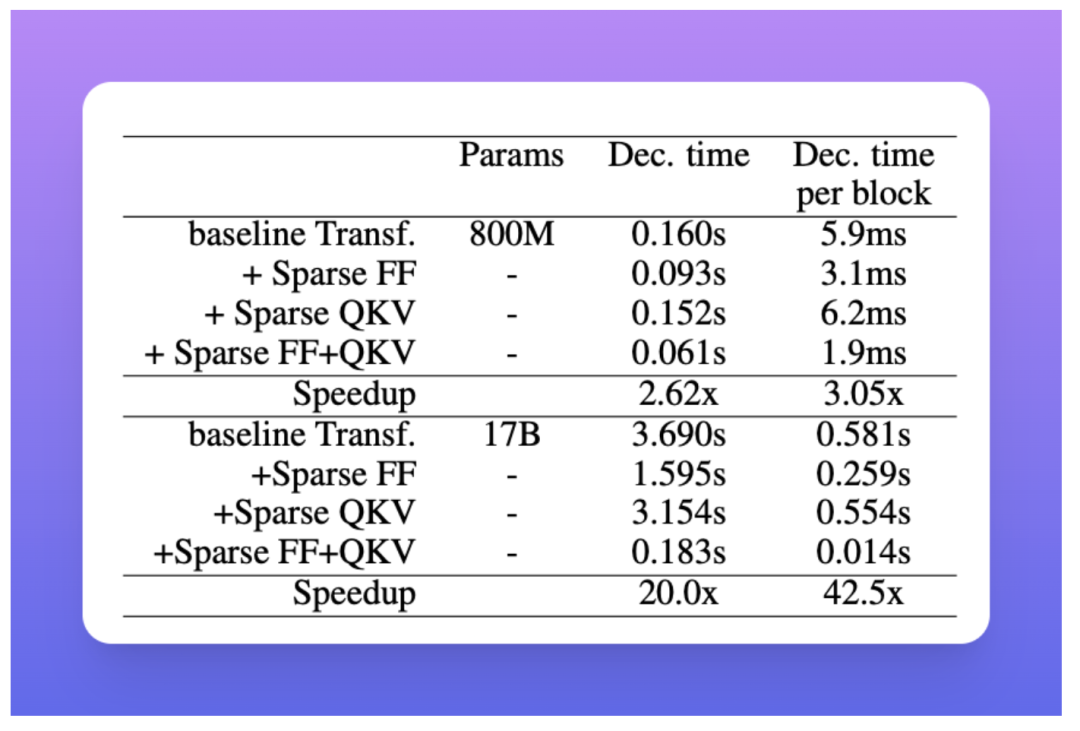
具有 17B 参数的 Terraformer 的单个令牌的解码速度比密集基线模型快 37 倍,推理所需的时间少于 100 毫秒/令牌。这里注意力稀疏 = 64,ff-稀疏 = 256,损失稀疏 = 4
稀疏化的收益非常好。然而,当解码较长的序列时,它们会更糟,因为解码时间将由注意力操作控制。
幸运的是,已经提出了许多方法来解决 Transformer 的这个问题,例如LSH(Locality-Sensitive Hashing)注意处理长序列和可逆层以提高内存效率。我会说这不是个微不足道的结果!
这篇论文还对用于提高 Transformer 效率的其他技术进行了有趣的概述。我在这里报告了它的一些摘录,我认为它可以作为那些不熟悉 Transformer 技术效率的人的参考。
- 模型压缩。模型修剪通过在训练之后或训练期间移除不需要的权重来使矩阵更小。
- 模型蒸馏。模型蒸馏包括在先前训练的大模型(即教师)的输出上训练一个小模型(即学生)。用于移动推理的几种自然语言模型依靠蒸馏来加速从预先训练的大型模型中进行推理。
- 稀疏注意力。基于稀疏注意力的方法通过合并额外的组合机制或选择该层所关注的标记子集,使注意力层更加高效,尤其是对于长序列。
- 稀疏前馈。关键思想是将前馈层划分为多个部分(称为专家),每个令牌只检索一个部分,这降低了前馈块的复杂性。这些加速主要以训练速度来衡量,并且该方法侧重于前馈块。专家方法的混合已被证明可以在训练中实现计算效率,扩展到一万亿个参数。
虽然目前的结果有许多局限性。尽管如此,这篇论文可以被认为是通往可持续大型模型的第一步。
大家怎么看?











