译者 | 谭剑
审校 | 孙淑娟 梁策
对于云原生的应用来说,一个现代化的GraphQL API层需要具备两个特征:水平可扩展性以及高可用性。
比如说,给一台运行API层的现有机器设备增加更多的CPU、内存和其他资源,这是垂直扩展性。而水平扩展性会为你的API基础设施添加更多的机器设备。
垂直扩展性主要是为了实现某种特定的扩展,而一个具备水平扩展性的API层可以发挥超越单台机器的容积能力。
当谈到高可用性的时候,GraphQL层需要无差错地持续运转(甚至在一些超出我们可控范围的突发情况中)。这是判断一个系统是否具备99.999%高可用特征的最佳考核指标。
这篇文章将为你介绍:如何使用一个基础数据库在几分钟内迅速搭建一个跨越同一个公共云片区的多个可用区域的GraphQL层。
最终的解决方案将会横跨多个可用区域,并且可以经受区域级别的故障,以及水平地扩展。
下面我们拿AWS、Hasura云,以及Yugabyte云作为参考平台来做案例演示。
跨多个可用区域来部署YugabyteDB
就从数据库层开始吧,我们选择YugabyteDB——一个开源的分布式SQL数据库。
对于可扩展性和可快速恢复的API来说,它是一个理想的支撑服务。
YugabyteDB同时也是符合PostgreSQL语法习惯的一个数据库。这意味着我们不需要学习另外一门SQL方言或者从零开始地重写现有的应用。
那么需要花费多少时间来部署一个有弹性、跨多区域的YugabyteDB集群呢?
这要看情况而定,但如果你像我一样懒,或者更倾向于直接使用云原生服务的话,那么Yugabyte云将会是完成这项任务的最简单的方式:
1.对于初学者来说,创建或者注册你的Yugabyte云账号。
2.然后,准备一个多节点的跨越若干个可用区域的YugabyteDB集群:
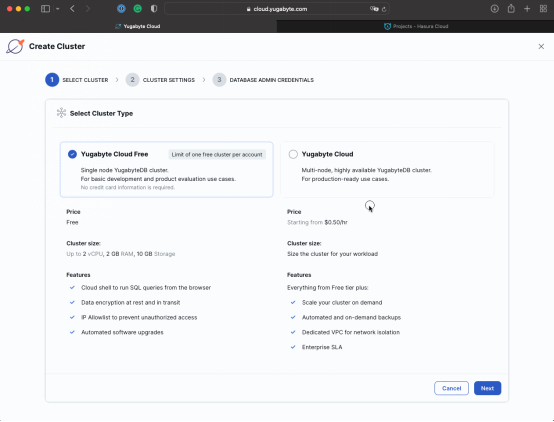
a. 选用一个自定义的集群名字,比如 multi-zone-cluster,把集群服务安放在离你最近的AWS片区(对我来说,N.Virginia - us-east-1是最近的),然后确保把Fault Tolerance这项参数设置为Availability Zone Level。
b. 点击Download credentials下载证书。然后点击"Create Cluster"(创建集群)。
那我们怎么利用YugabyteDB来实现高可用呢?
这个集群有三个节点,部署在三个可用区域的其中一个里面。备份因子同样已设置为3。
这意味着每一个节点(而实际上是在每个区域)都会维护着一份数据记录的拷贝。在我的例子中,分别位于us-east-1b、us-east-1c、以及us-east-1a等可用区域里都分别有一个节点:
节点
YugabyteDB是基于Raft一致性协议的。因此,按当前已有三个节点的配置,我们可以释放为一个节点(或者说,一个可用区间——只要在每个片区都有一个节点),这个节点仍然是可运行的。
为什么YugabyteDB不选择只用一个节点来处理请求服务呢?
依据CAP定理(又称作布鲁尔定理),YugabyteDB是一个遵循一致性和分区容错性(CP)的数据库。
下面的公式定义了容错变量K和备份因子RF之前的依赖关系:
RF=(2k + 1)
在我的例子中,K=1(意思是,集群可以释放为1个节点),而因此,RF结果为3(3份数据拷贝)。
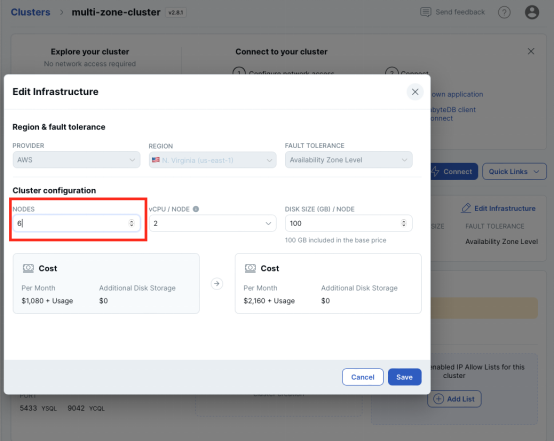
问题来了,如果数据库需要处理100倍的查询次数或者存储更多的数据,那我们怎么样利用YugabyteDB来完成水平扩展呢?只需要在集群的Setting界面添加更多的节点到基础设施里。
打造一个可扩展以及富有弹性的 Hasura GraphQL层
Hasura 是一个高级的GraphQL服务器,它基于符合PostgreSQL方言的数据库(比如YugabyteDB),提供了快速实时的GraphQL API。
Hasura有一个完全可管理的云版本。创建一个Hasura项目,具有水平扩展性和高可用性,开箱即用:
- 创建或登录你的Hasura Cloud账号;
- 创建一个Standard Tier项目:
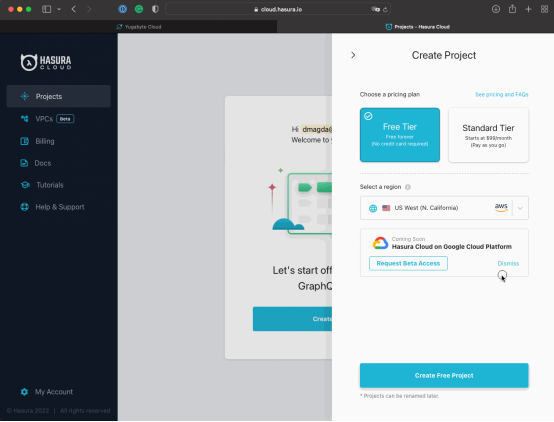
- 选择一个AWS片区,类似部署YugabyteDB那样——在我的例子中,是US East (N. Virginia)。
- 点击Create Project按钮,继续部署操作。
就像我们所看到的,Hasura没有任何与扩展性或区域级别可用性相关的设置。那么,在可能发生区域故障或者哪天有必要做水平扩展的时候,我们如何确定API层能够继续保持可运行呢?
实际上,只要我们选择了Standard Tier,这两个特性就都会有的。这就是Hasura在文档所说的:
- 水平扩展:Hasura Cloud能够自动地扩展你的应用而不用去考虑实例的数量、内核、内存或者阈值。你可以保持增加并发用户的数量以及API的调用次数,同时,Hasura Cloud将会自动帮你实现优化。
- **高可用:**Hasura的多实例可以运行于graphql引擎。在Hasura Cloud里,自动化的扩展处理以及支持运行所必需的基础设施,都会被安排妥当,不需要人工干预。
把Hasura链接到YugabyteDB
到目前为止,我们已经部署了一个Hasura GraphQL层和YugabyteDB集群,可以支撑水平扩展以及区域级别的突发故障了。剩下要做的,就是把这两个组件连接起来,为我们的应用提供一个最终解决方案。
把Hasura添加到YugabyteDB白名单里
YugabyteDB集群实例要求我们设定所访问数据库的应用IP地址。对我们的Hasura实例来说这并不难。
把Hasura Cloud IP添加到Yugabyte Cloud终端的Allow IP List里:
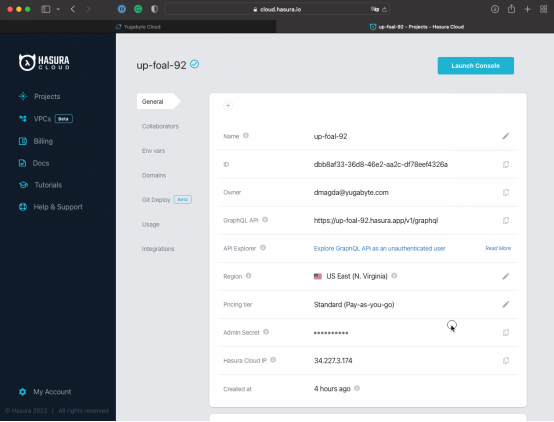
- 从你的Hasura项目界面里复制Hasura Cloud IP。
- 转到YugabyteDB Cloud,把IP添加到IP Allow List里。
建立连接
在授权Hasura访问YugabyteDB实例后,我们需要在两个服务之间建立连接。这需要两个步骤:
1. 打开Yugabyte Cloud,然后复制一个链接URL:
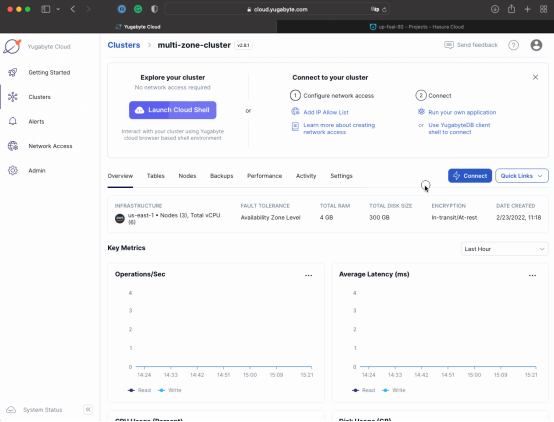
- 点击Connect按钮,选择Connect to your Application选项。
- 勾选Optimize。
- 复制链接YSQL(Yugabyte SQL)的唯一URL。
- 确保使用之前从YugabyteDB集群部署那个步骤下载的证书里面的信息,替换掉数据库用户和密码。
3. 转到Hasura云,与YugabyteDB建立一个连接:
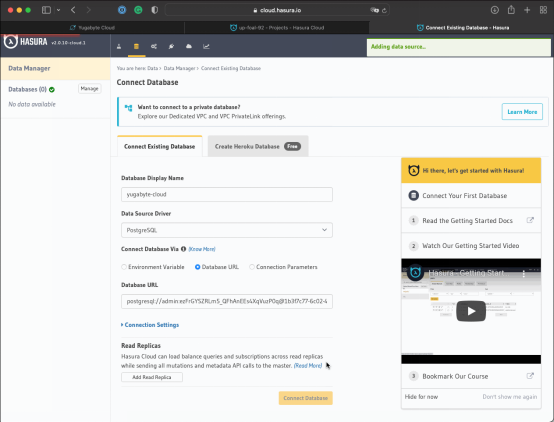
- 点击Launch Console按钮,跳转到Data & Schema 管理界面。
- 填写YugabyteDB链接参数,建立一个链接。
- 点击Connect Database按钮,建立链接。
我们刚刚已经完成一个Graphql API层的搭建,它可以支撑区域级别的故障以及水平扩展能力。现在,我们用一些样例数据和请求来做一个健全性测试。
创建一个样例数据库
按照以下的步骤,在YugabyteDB里创建用户表和消息表:
1. 在YugabyteDB Cloud终端里,点击Launch the Cloud Shell。
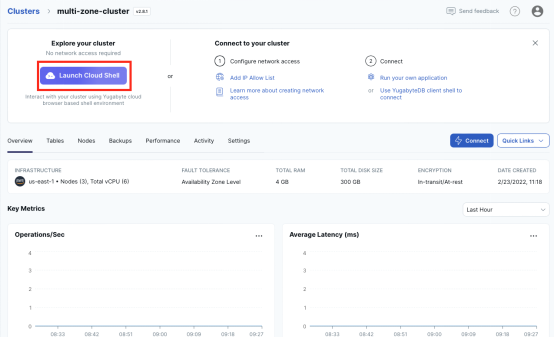
2. 创建用户表Users和消息表Messages:
3. SQL:
CREATE SEQUENCE users_pk_seq CACHE 100;
CREATE SEQUENCE messages_pk_seq CACHE 100;
CREATE TABLE Users (
id int NOT NULL DEFAULT nextval('users_pk_seq'),
name text,
age int,
city text,
PRIMARY KEY(id));
CREATE TABLE Messages (
id int NOT NULL DEFAULT nextval('messages_pk_seq'),
sender_id int REFERENCES Users(id),
recipient_id int REFERENCES Users(id),
payload text,
PRIMARY KEY (id)
);
4.最后,初始化用户表,创建两条记录:
SQL:
INSERT INTO USERS (name, age, city) VALUES
('John', 35, 'Austin'),
('Mark', 36, 'Seattle');
用GraphQL来查询数据
往YugabyteDB里载入样例数据库后,我们可以体验到Hasura提供的GraphQL API层带来的便利。
把数据表暴露到GraphQL层
即使Hasura自动检测数据库端的结构更改,我们仍然需要明确指定哪些表可以通过GraphQL API查询:
1. 在Hasura Console里打开Data & Schema Management。
2. 点击Track All按钮,通过YugabyteDB API展示出两个数据表:
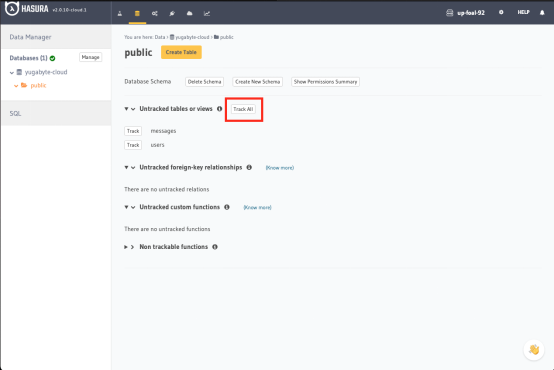
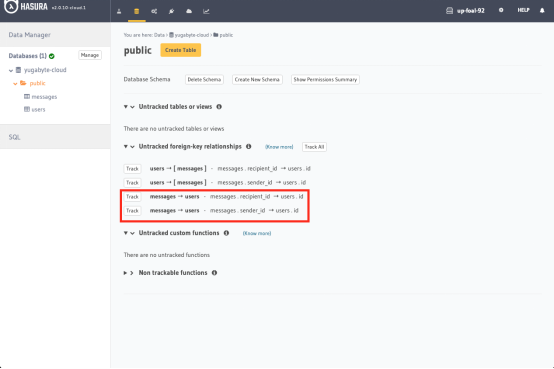
3. 最后,点击Track按钮,建立从message表到users表的外键关联关系:
查询数据
下一步,我们来用GraphQL读取用户表里面的记录:
1. 打开Hasura Console界面的Api Explorer标签:

2. 查询全部用户:
query {
users {
id
name
age
city
}
}
3.最后,确认输出如下:
{
"data": {
"users": [
{
"id": 1,
"name": "John",
"age": 35,
"city": "Austin"
},
{
"id": 2,
"name": "Mark",
"age": 36,
"city": "Seattle"
}
]
}
}
更新数据
最后,来确认一下我们的GraphQL API能够顺利处理写入问题。
1. 使用以下的GraphQL变种语法,添加一条消息记录到数据库里:
mutation {
insert_messages_one(object: {recipient_id: 2, sender_id: 1, payload: "Hi, Mark! How are you doing?"}) {
id
}
}
2.从YugabyteDB反向读取消息:
query {
messages {
payload
userBySenderId {
name
city
}
user {
name
city
}
}
}
3.确认输出如下:
{
"data": {
"messages": [
{
"payload": "Hi, Mark! How are you doing?",
"userBySenderId": {
"name": "John",
"city": "Austin"
},
"user": {
"name": "Mark",
"city": "Seattle"
}
}
]
}
}
结论
正如我们在这篇文章里所看到的,正确地融合现代的云原生服务,可以搭建一个水平可扩展和一个高可用的GraphQL API层。
在几分钟的时间里,我们已经得到一个可以处理请求增加的API层,并把它的容积能力从10GB扩展到100GB,甚至更大的容量。此外,最重要的是,它能够持续服务应用的请求,哪怕突发区域级别故障也可以做到。
最后,如果你的GraphQL API层需要跨多个云片区工作,并能实现片区级别的突发状况容错,那么你仍然可以使用Hasura和YugabyteDB。目前,这项能力可在自管理安装选项中获取(可参考 YugabyteDB的多区域部署)。
相信在不久的将来,它也会往完全管理版本的技术方向发展。
译者介绍
谭剑,毕业于广东财经大学,现自主创业。喜欢编程、外语、阅读。
原文标题:How To Set Up a Scalable and Highly-Available GraphQL API in Minutes,作者:Denis Magda