












其基本信息如表2-2所示。
▼表2-2 Knative基本信息

Knative一个很重要的目标就是制定云原生、跨平台的Serverless编排标准。Knative是通过整合容器构建(或者函数)、工作负载管理(和动态扩缩)以及事件模型来实现Serverless标准的。Knative社区的主要贡献者有Google、Pivotal、IBM、Red Hat。CloudFoundry、OpenShift这些PaaS提供商都在积极地参与Knative的建设。
1.工作原理
如图2-14所示,Knative是建立在Kubernetes和Istio平台之上的,使用了Kubernetes提供的容器管理组件(deployment、replicaset和pod等),以及Istio提供的网络管理组件(ingress、LB、dynamic route等)。
Knative中有两个重要的组件,分别是为其提供流量的Serving(服务)组件以及确保应用程序能够轻松地生产和消费事件的Event(事件)组件。
其中,Serving组件基于负载自动伸缩,包括在没有负载时缩减到零,允许使用者为多个修订版本应用创建流量策略,从而通过URL轻松路由到目标应用程序;而Event组件的作用是使生产和消费事件变得容易,允许操作人员使用自己选择的消息传递层。
除了Serving和Event组件之外,Build也是Kantive的组件之一。其提供“运行至完成”的显示功能,这对创建CI/CD工作流程很有用,通过灵活的插件化的构建系统将用户源代码构建成容器。
目前,其已经支持多个构建系统,比如Google的Kaniko,它无须运行Docker Daemon就可以在Kubernetes集群上构建容器镜像。Serving使用它将源存储库转换为包含应用程序的容器镜像。
在诸多Serverless开源项目中,Knative的优势也是较为明显的。一方面,Knative以Kubernetes为底层框架,与Kubernetes生态结合得更紧密。无论是云上Kubernetes服务还是自建Kubernetes集群,都能通过安装Knative插件快速地搭建Serverless平台。
另一方面,Knative联合CNCF,把所有事件标准化为CloudEvent,提供事件的跨平台运行,同时让函数和具体的调用方法解耦。在弹性层面,Knative可以监控应用的请求,并自动扩缩容,借助于Istio(Ambassador、Gloo等)支持蓝绿发布、回滚的功能,方便应用发布。
同时,Knative支持日志的收集、查找和分析,并支持VAmetrics数据展示、调用关系跟踪等。
Knative工作原理如图2-14所示。
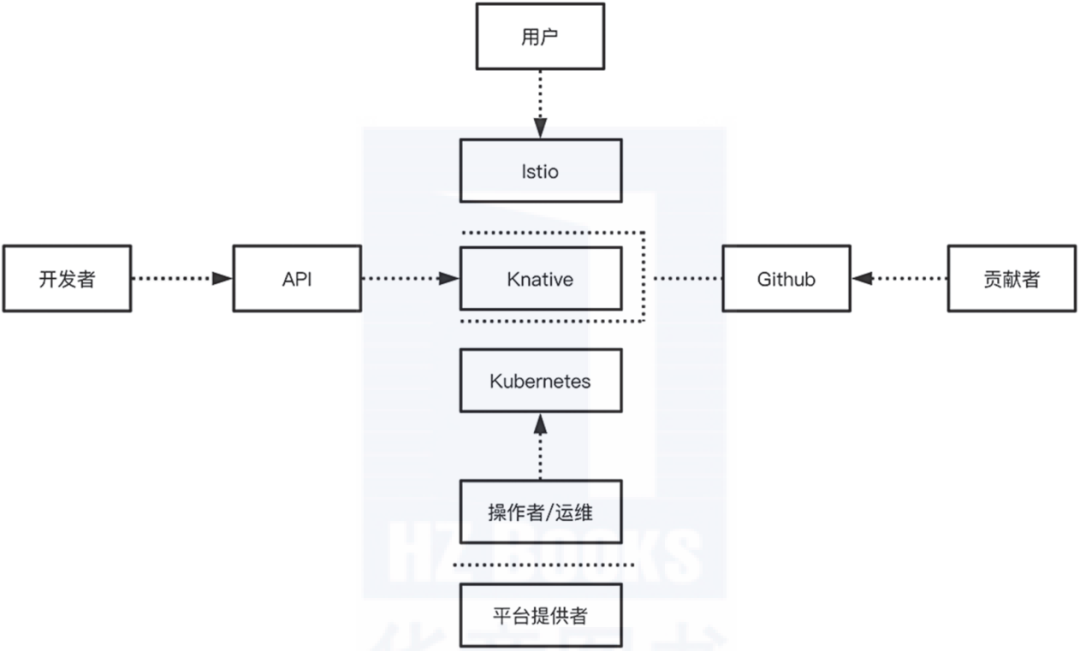
▲图2-14 Knative工作原理
2.功能与策略
(1)Serving(服务)
Serving模块定义了一组特定的对象,包括Revision(修订版本)、Configuration(配置)、Route(路由)和Service(服务)。Knative通过Kubernetes CRD(自定义资源)的方式实现这些Kubernetes对象。所有Serving组件对象间的关系可以参考图2-15。
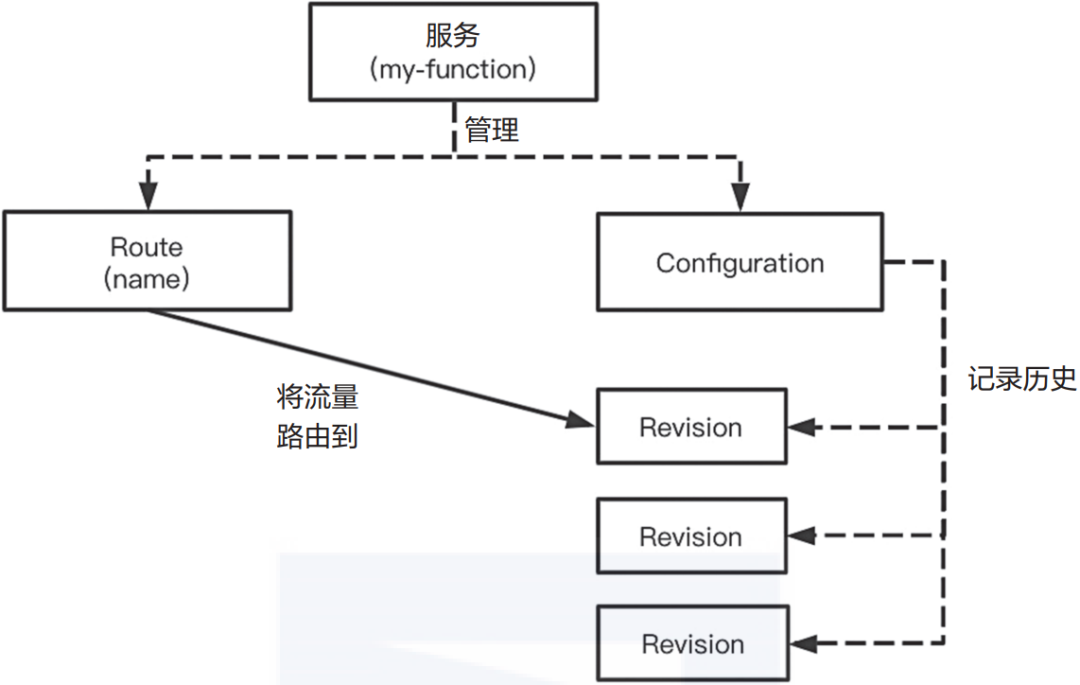
▲图2-15 Serving组件对象间的关系
Knative Serving始于Configuration。使用者在Configuration中为部署容器定义所需的状态。最小化Configuration至少包括一个配置名称和一个要部署容器镜像的引用。
在Knative中,定义的引用为Revision。Revision代表一个不变的、某一时刻的代码和Configuration的快照。每个Revision引用一个特定的容器镜像和运行它所需要的特定对象(例如环境变量和卷)。然而,使用者不必显式创建Revision。Revision是不变的,它们从不会被改变和删除。
相反,当使用者修改Configuration的时候,Knative会创建一个Revision。这使得一个Configuration既可以反映工作负载的当前状态,也可以用于维护一个历史的Revision列表。
Knative中的Route提供了一种将流量路由到正在运行的代码的机制。它将一个HTTP可寻址端点映射到一个或者多个Revision。Configuration本身并不定义Route。
(2)弹性伸缩
Serverless架构的一个关键原则是可以按需扩容,以满足需要和节省资源。Serverless负载应当可以一直缩容至零。这意味着如果没有请求进入,则不会运行容器实例。如图2-16所示,Knative使用两个关键组件实现该功能。它将Autoscaler和Activator实现为集群中的Pod。
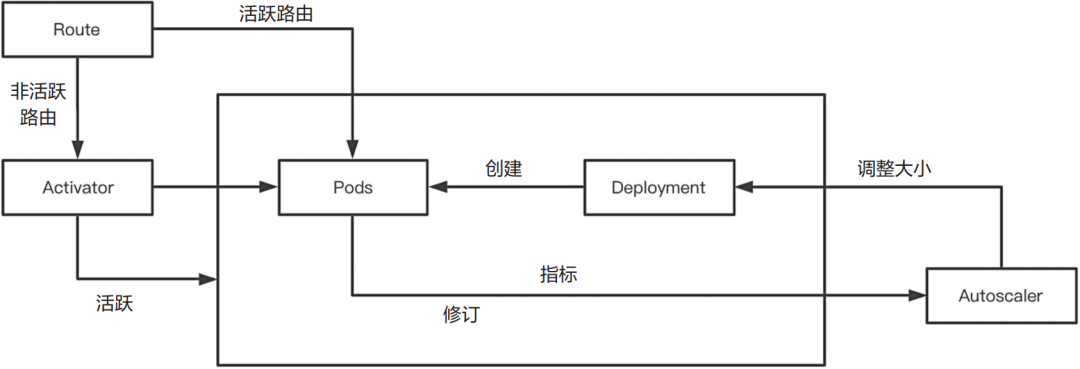
▲图2-16 Knative弹性伸缩原理简图
用户可以看到它们伴随其他Serving组件一起运行在knative-serving命名空间中。Autoscaler收集达到Revision并发请求数量的有关信息。为了做到这一点,它在Revision Pod内运行一个名为queue-proxy的容器。该Pod中也运行用户提供的镜像。
queue-proxy检测该Revision上观察到的并发量,然后每隔一秒将此数据发送到Autoscaler。Autoscaler每隔两秒对这些指标进行评估,并基于评估的结果增加或者减少Revision部署的规模。默认情况下,Autoscaler尝试维持每Pod每秒平均接收100个并发请求。这些并发目标和平均并发窗口均可以变化。
Autoscaler也可以利用Kubernetes HPA(Horizontal Pod Autoscaler)来替代该默认配置。这将基于CPU使用率实现自动伸缩,但不支持缩容至零。这些设定都能够通过Revision元数据注解(Annotation)定制。
Autoscaler采用的伸缩算法针对两个独立的时间间隔计算所有数据点的平均值。它维护两个时间窗,分别是60秒和6秒。Autoscaler以两种模式运作:Stable Mode(稳定模式)和Panic Mode(恐慌模式)。在稳定模式下,它使用60秒时间窗的平均值决定如何伸缩部署以满足期望的并发量。
如果6秒时间窗的平均并发量两次达到期望目标,Autoscaler转换为恐慌模式并使用6秒时间窗。这让它更加快捷地响应瞬间流量的增长。它也仅仅在恐慌模式下扩容以防止Pod数量快速波动。如果超过60秒没有发生扩容,Autoscaler会转换回稳定模式。
(3)Build(构建)
Knative的Serving(服务)组件是解决如何从容器到URL的,而Build组件是解决如何从源代码到容器的。Build资源允许用户定义如何编译代码和构建容器。这确保了在将代码发送到容器镜像库之前以一种一致的方式编译和打包代码。下面介绍一些新的组件。
- Build:驱动构建过程的自定义Kubernetes资源。在定义构建时,用户需要定义如何
获取源代码以及如何创建容器镜像来运行代码。
- Build Template:封装可重复构建步骤以及允许对构建进行参数化的模板。
- Service Account:允许对私有资源(如Git仓库或容器镜像库)进行身份验证。
(4)Event(事件)
到目前为止,向应用程序发送基本的HTTP请求是一种有效使用Knative函数的方式。无服务器的松耦合特性同时也适用于事件驱动架构。也就是说,可能在文件上传到FTP服务器时需要调用一个函数;或者任何时间发生一笔物品销售时需要调用一个函数来处理支付和库存更新的操作。
与其让应用程序或函数考虑监听事件的逻辑,不如当那些被关注的事件发生时,让Knative去处理并通知我们。
自己实现这些功能则需要做很多工作并要编写实现特定功能的代码。幸运的是,Knative提供了一个抽象层使消费事件处理变得更容易。
Knative直接提供了一个“事件”,而不需要编写特定的代码来选择消息代理。当事件发生时,应用程序无须关心它来自哪里或发到哪里,只需要知道事件发生了即可。如图2-17所示,为实现这一目标,Knative引入了三个新的概念:Source(源)、Channel(通道)和Subscription(订阅)。
- Source(源):事件的来源,用于定义事件在何处生成以及如何将事件传递给关注对象的方式。
- Channel(通道):通道处理缓冲和持久性,即使该服务已被关闭,也可确保将事件传递到预期的服务。另外,通道是代码和底层消息传递解决方案之间的一个抽象层。这意味着可以像Kafka和RabbitMQ一样在某些服务之间进行消息交换,但在这两种情况下都不需要编写特定的实现代码。
- Subscription(订阅):将事件源发送到通道,并准备好处理它们的服务,但目前没有办法获取从通道发送到服务的事件。为此,Knative设计了订阅功能。订阅是通道和服务之间的纽带,指示Knative如何在整个系统中管理事件。
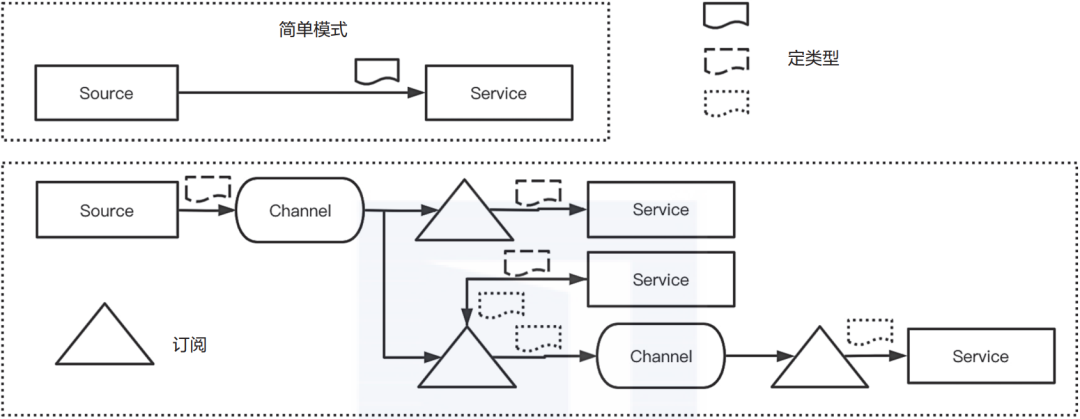
▲图2-17 Knative事件处理模型简图
Knative中的服务不关心事件和请求是如何获取的。它可以获取来自入口网关的HTTP请求,也可以获取从通道发送来的事件。无论通过何种方式获取,服务仅接收HTTP请求。这是Knative中一个重要的解耦方式。它确保将代码编写到架构中,而不是在底层创建订阅、通道向服务发送事件。
关于作者:刘宇(花名:江昱),国防科技大学电子信息专业博士,阿里云Serverless产品体验侧负责人,从事Serverless相关的工作多年,负责阿里云函数计算(FC)、Serverless工作流(FNF)等产品的体验工作,有丰富的实践经验。阿里云战略级开源项目Serverless Devs发起人和负责人,Serverless Framework、Kubevela等开源项目贡献者,社区项目Anycodes在线编程负责人。
本文摘编自《Serverless工程实践:从入门到进阶》,经出版方授权发布。




















