自动驾驶汽车上路时,不可避免的需要学习一些道路上的“潜规则”。自动驾驶系统需要察言观色,随机应变地及时发现什么时候应该减速礼让,什么时候又应该发现别人正在礼让而尽快加速通过。由于道路环境的复杂性,很多新手司机都未必能够做出合适的判断。
这种复杂性导致基于规则的方法很难在覆盖到全部情况的同时不出现互相冲突的情况。来自清华大学的研究团队提出了一种基于自监督学习的方法,从已有的轨迹预测数据集中学得道路上的各种“礼仪”,并正确判断出冲突中的礼让关系。该研究将预测的关系在充满复杂交互的 Waymo Interactive Motion Prediction 数据集上进行了测试,并提出了 M2I 框架来使用预测出的关系进行场景级别的交互轨迹预测。
该项目主要由清华大学孙桥和MIT黄昕合作完成,清华MARS Lab赵行老师给予指导。

- 论文地址:https://arxiv.org/abs/2202.11884
- 项目地址:https://tsinghua-mars-lab.github.io/M2I/
轨迹预测问题是自动驾驶系统中的重要一环,对自动驾驶车辆安全行驶不可或缺。轨迹预测模块通常作为识别 (Detection) 和跟踪 (Tracking) 的下游系统,使用已有的高精地图和识别到的周围的其他车辆或行人的信息来预测他们未来可能会做出哪些行为。轨迹预测系统会以轨迹或热力图的形式输出预测结果,以便下游的规划 (Planning) 系统规划出一条对于自动驾驶车自身最为合理的下一步的决策或轨迹。
尽管大多数轨迹预测方法都通过 GNN 或基于 Attention 的方法尝试学习道路上的车辆和行人之间的关系,但是这些方法通常面对以下一些难以克服的挑战:
1. 模型预测的关系是隐式的所以缺乏可解释性,也难以确定模型是否真的学习到了这些关系;
2. 模型预测的关系和最终输出的轨迹之间并不统一(如图 1 第一行所示),会天然出现重叠的情况,无法确保场景级别的合理性;
3. 道路使用者的决策存在顺序关系,模型预测无法区别逻辑上的预测顺序,而是只能并行逐个预测。
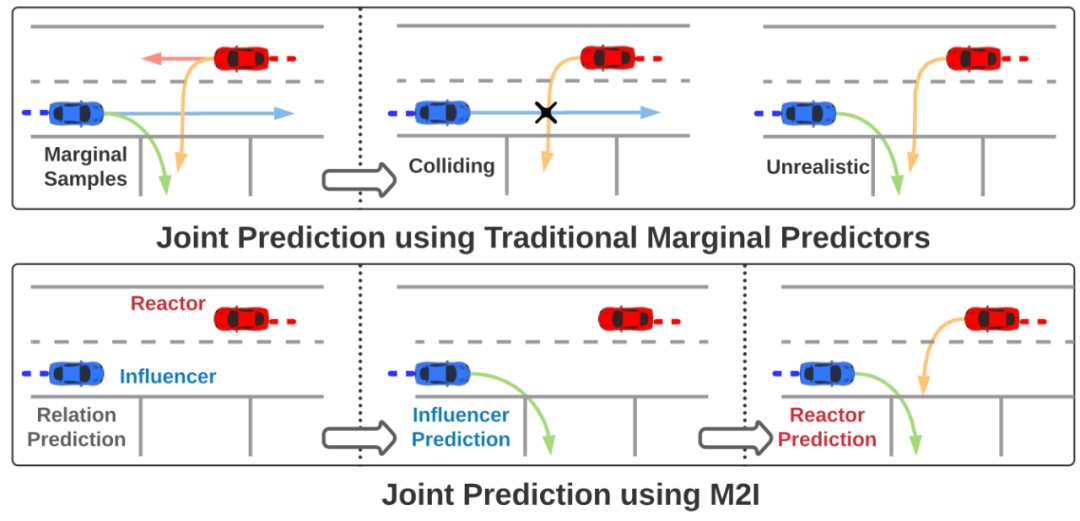
图 1: 逐车进行轨迹预测的方法输出的轨迹之间会存在碰撞
为了解决这些问题,研究者提出了一个简单且有效的框架 M2I(如图 1 第二行)。使用 M2I 框架,你可以快速的将手头已有的任何轨迹预测模型进行改造后,获得场景级别的关系预测能力以及基于一辆车的轨迹预测另一辆车的轨迹的能力。使用这两种能力即可确保你的新模型获得针对交互场景的更好预测效果。
多智能体轨迹预测转单智能体轨迹预测
首先让我们来看一下 M2I 的整体框架。M2I 由三个模块组成, 如图 2。这三个模块分别是关系预测模块,单智能体轨迹预测,条件轨迹预测。
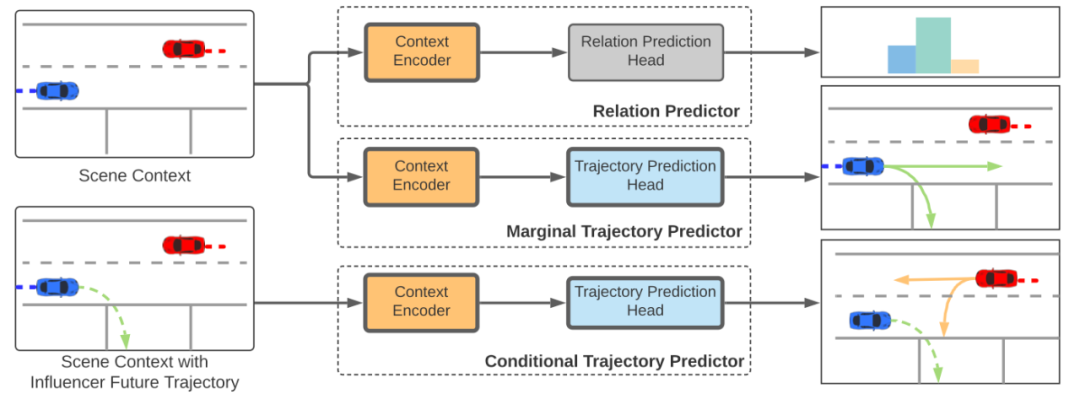
图 2: M2I 轨迹预测框架
关系预测
复杂的道路使用者之间的关系可以被抽象为多个关系对,该研究将每一对道路使用者分类为一个 影响者 (Influencer) 和一个 响应者 (Reactor),将响应者定义为冲突中的需要礼让的一方,而影响者则是不需要礼让的一方。由此可以将交互中的轨迹预测问题抽象成两次轨迹预测,一次是预测影响者的轨迹,一次是使用预测好的影响者的轨迹去预测响应者的轨迹。这样的方法确保了两者在场景级别上预测的轨迹的一致性从而最大程度上避免了重叠等不合理的情况。
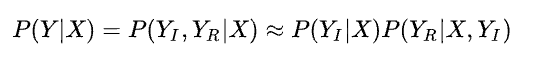
那么如何预测谁是影响者谁是响应者呢?或者说预测冲突中谁应该礼让。该研究提出了一种基于时空轨迹交错的方法从已有数据集中挖掘 Ground Truth 标签的方法。具体来说,在数据集中,如果任意两个道路使用者的轨迹在不同时间上产生了交叉,该方法则标记优先通过这个交叉点的智能体为影响者,后通过的标记为响应者。通过对这个自动生成的标签的学习,该模型可以学习到冲突时的先行关系。
该研究使用的关系预测模型是将 DenseTNT 的 Trajectory Prediction Head 换为一个普通的分类 Classification Head 改造得到的。研究者发现不对已有模型的其他部分进行任何修改,就可以将关系预测的准确率达到 90% 以上。对比实验显示,使用准确率越高的关系进行 Conditional Trajectory Prediction 可以获得越好的效果。
研究者还将关系预测拓展到多智能体的关系预测上。针对多智能体,该研究将他们两两成对进行预测,并将预测结果组成一个有向图来表示他们之间的关系,结果如图 3 所示,M2I 的关系预测模块可以很好地拓展到多智能体的关系预测上。
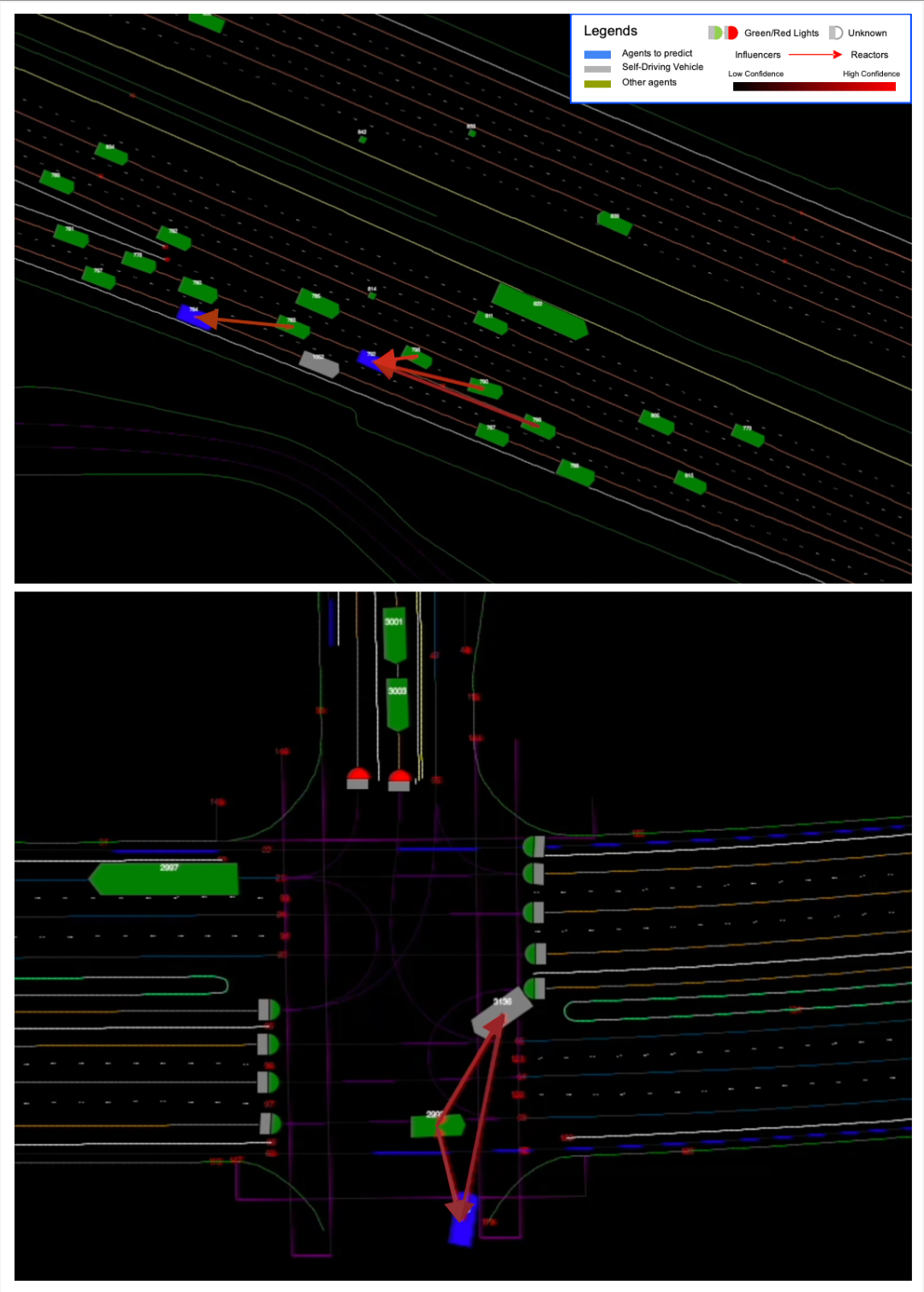
图 3: 复杂场景下的多智能体的关系预测
轨迹预测
可以使用任何常见的轨迹预测模块来替换 M2I 框架中的单智能体轨迹预测模块,在该论文的实验中,研究者使用了 DenseTNT 进行单智能体轨迹预测。对于 Conditional Trajectory Prediction,研究者修改了 DenseTNT 的 Encoder,将影响者的未来的轨迹(在使用的 Waymo 数据集中,未来轨迹为 8s,共 80 帧)与其他信息共同进行编码供模型进行学习。训练时影响者未来的轨迹是数据集中的 ground truth 轨迹,预测时影响者未来的轨迹是单智能体模块输出的轨迹。对于 Conditional Trajectory Prediction,该研究没有修改除了 Encoder 之外模型的其他结构。
实验结果
实验结果证明,相比于其他几个在 leaderboard 上的方法,使用了 M2I 框架的 DenseTNT 模型表现明显优于其他方法。尤其是在车辆之间的交互上,使用 M2I 预测在 mAP 上相比其他模型性能提升明显。
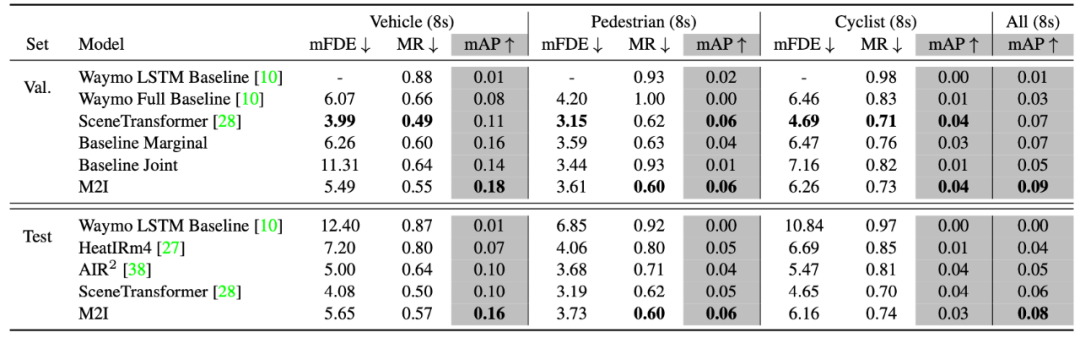
图 4: M2I 在 Interactive Motion Prediction 上的表现明显优于其他已有方法
该研究还尝试了使用 TNT 作为 Backbone。实验结果显示,使用 M2I 框架同样可以帮助 TNT 提升在交互场景中的性能表现,从而证明了 M2I 框架可以不受限于某个指定的 backbone。
定性分析显示,使用 M2I 框架后,预测轨迹在场景级别上表现的更为接近真实的交互轨迹,如图 5 所示。
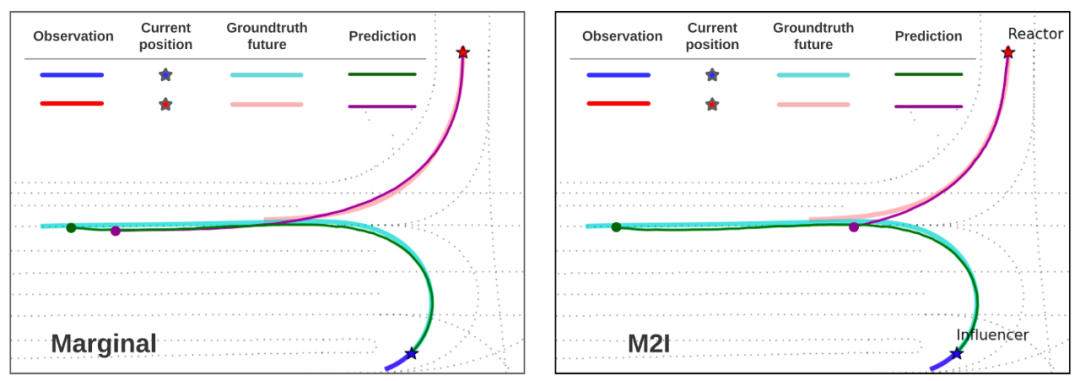
图 5: M2I 更好的学习到了场景中两辆正在交互的车辆应该如何先后完成转弯