












本文转自雷锋网,如需转载请至雷锋网官网申请授权。
近日,「黑客组织」EleutherAI 在打破 OpenAI 对 GPT-3 的垄断上又迈出了关键的一步:
发布全新 200 亿参数模型,名曰「GPT-NeoX-20B」。
众所周知,自 2020 年微软与 OpenAI 在 GPT-3 源代码独家访问权上达成协议以来,OpenAI 就不再向社会大众开放 GPT-3 的模型代码(尽管 GPT-1 和 GPT-2 仍是开源项目)。
出于对科技巨头霸权的「反叛」,一个由各路研究人员、工程师与开发人员志愿组成的计算机科学家协会成立,立志要打破微软与 OpenAI 对大规模 NLP 模型的垄断,且取得了不错的成果。
这个协会,就是:EleutherAI。
它以古罗马自由女神 Eleutheria 的名字命名,透露出对巨头的不屑与反抗。
与 1750 亿参数的 GPT-3 相比,GPT-NeoX-20B 的参数显然是小巫见大巫。但 EleutherAI 对该成果十分自豪,为什么?
1 EleutherAI 的由来
首先介绍一下 EleutherAI 的发展历史。
人工智能威胁论是一个老生常谈的问题。霍金曾在《独立报》上这样形容人工智能的威胁:「尽管人工智能的短期影响取决于控制它的人,但长期影响却取决于它究竟能否被控制。」
EleutherAI 的成立始于 2020 年 7 月,主要发起人是一群号称自学成才的黑客,主要领导人包括 Connor Leahy、Leo Gao 和 Sid Black。
当时,微软与 OpenAI 达成对 GPT-3 的控制访问协议。听闻风声,一群反叛极客就在 Discord(一个社交媒体平台 )上说:「让我们给 OpenAI 一个教训吧!」
于是,他们就基于 Discord 成立了 EleutherAI,希望建立一个能够与 GPT-3 相媲美的机器学习模型。
创始人 Connor Leahy 在接受 IEEE Spectrum 的采访时说道:
「起初这真的只是一个有趣的业余爱好,但在疫情封城期间我们没有更好的事情可做,它的吸引力很快就变得大起来。」
「我们认为自己是几十年前经典黑客文化的后裔,只是在新的领域,出于好奇和对挑战的热爱而对技术进行试验。」
Discord 服务器现在有大约 10,000 名成员,但只有大约 100 或 200 人经常活跃,由一个 10 到 20 人组成的团队在开发新模型。
自成立以来,EleutherAI 的研究团队首先开源了基于 GPT-3 的、包含 60 亿参数的 NLP 模型 GPT-J,2021 年 3 月又发布类 GPT 的27 亿参数模型 GPT-Neo,可以说成长迅速。
今年2月9日,他们又与 CoreWeave 合作发布了 GPT-Neo 的升级版——GPT-NeoX-20B,官方代码地址如下,现可从 The Eye on the Eye 公开下载。
- 代码地址:https://mystic.the-eye.eu/public/AI/models/GPT-NeoX-20B/
它也是目前最大的可公开访问的预训练通用自回归语言模型。
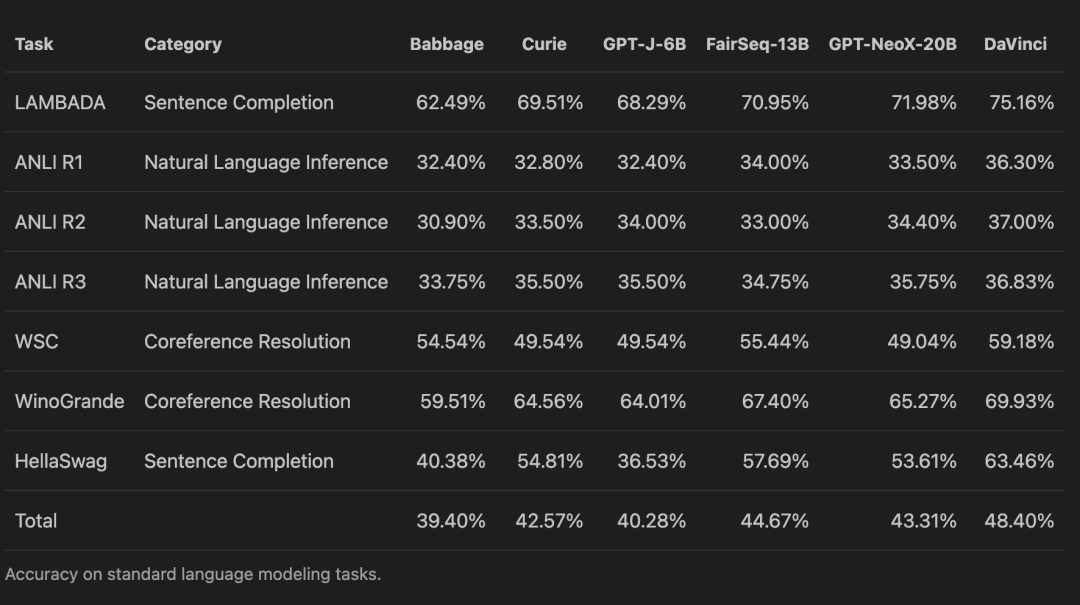
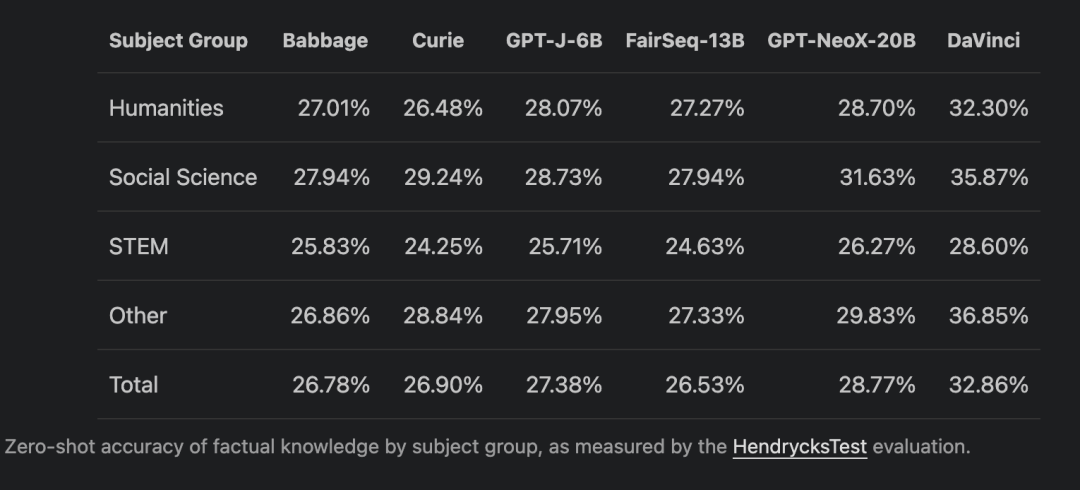
在发布声明中,Leahy 特别标注了「标准语言建模任务的准确性」和「由 HendrycksTest 评估衡量的按主题组划分的事实知识的零样本准确性」:
2 GPT-NeoX-20B 的优势:免费开放
简单来说,GPT-NeoX-20B 是一个包含 200 亿参数、预训练、通用、自回归大规模语言模型。
如果你不知道是什么,想想 OpenAI 的 GPT-3,它是近两年前震惊世界的大型语言模型,语言能力神通广大,包括编写计算机代码、创作诗歌、生成风格难以区分的带有权威语气的假新闻,甚至给它一个标题、一句话,它就可以生成一篇文章,因为它可以根据很少的输入信息自行「创作」,而且创作出来的东西还可以文意皆通。(题外话:就像漫威低配版的贾维斯)

必须承认的是,OpenAI 的模型比 EleutherAI 更大,有 1750 亿个参数(模型内部编码信息的节点或数字)。参数越多,模型吸收的信息就越多、越细化,因此模型就越「聪明」。
但 EleutherAI 是世界上同类模型中最大、性能最好的模型,可免费公开获得。
「我们希望更多的安全研究人员能够使用这项技术。」Leahy 说。
此外,EleutherAI 与 OpenAI 在训练大规模模型所需的计算能力上有所不同。
OpenAI 在数量不详的 Nvidia V100 Tensor Core GPU 上训练了 GPT-3。此后,OpenAI 的合作伙伴微软开发了一个用于大型模型训练的单一系统,该系统具有超过 285000 个 CPU 内核、10000 个 GPU,以及每个 GPU 服务器每秒 400 Gb 的网络连接。
这并没有阻止 EleutherAI 在反 GPT-3 垄断上的努力。他们最初使用谷歌提供的硬件作为其 TPU 研究云计划的一部分,构建了一个具有 60 亿个参数的大型语言模型 GPT-J。对于 GPT-NeoX-20B,该小组得到了 CoreWeave 的帮助,CoreWeave 是一家专门针对基于 GPU 的工作负载的云服务提供商。
虽然 OpenAI 号称是人工智能非盈利组织,但目前来看,其本质还是由科技公司主导开发的私有模型。
EleutherAI 的数学家和人工智能研究员 Stella Biderman 对 IEEE Spectrum 表示:
「这些私有模型限制了我们这种独立的科研人员权限,如果我们不了解它的工作原理,科学家、伦理学家、整个社会就无法就这项技术应该如何融入我们的生活进行必要的对话。」
EleutherAI 的工作促进了对大型语言模型的可解释性、安全性和伦理的研究,受到外界肯定。
机器学习安全领域的主要人物 Nicholas Carlini 在最近的一篇论文中表示:「如果没有 EleutherAI 完全公开发布 The Pile 数据集及其 GPT-Neo 系列模型,我们的研究是不可能实现的。」Pile 数据集是一个 825 GB 的英文文本语料库,用于训练大规模语言模型。
3 开放模型访问权限是 AI 发展的必要条件
马斯克不只一次发表人工智能比人类强这一观点。他认为人是碳基生物自带上限。而人类进化的速度很明显比不上人工智能,所以人工智能迟早超过人类,这是AI最大的潜在威胁。OpenAI 也是他基于这个考量和其他科技大亨共同创立的。
Leahy 认为 AI 的最大风险不是有人利用它作恶,而是构建一个非常强大的 AI 系统,无人知道如何控制。
他说:「我们必须将人工智能视为不像我们思考的奇怪外星人。」他补充说,「人工智能擅长优化目标,但如果给定一个愚蠢的目标,结果可能是不可预测的。他担心研究人员会在创造越来越强大的人工智能的竞赛中过度自信,在这个过程中偷工减料。」
其实任何志同道合的计算机科学家都可以构建一个大型语言模型,但很难获得合适的硬件来训练大型语言模型,因为这需要非常高的资本投资,而如今只有几百家公司拥有这种硬件。
「我们需要研究这些系统,以了解我们如何控制它们。」EleutherAI的创作初衷正是通过使这种规模的模型易于访问,从而让有兴趣的人们进一步研究人工智能系统的安全使用。
反观 OpenAI,「Open」怕不是只对金钱 Open 吧?
























