组织多年来的一贯做法是将所有数据整合到单一位置,例如数据仓库或近年来兴起的数据湖。但是,集中式数据基础架构的一些弊端已初现端倪:
1. 集中式数据团队对数据的了解程度无法与只专注于全部数据中特定部分的具体业务团队相提并论。
2. 集中式数据基础架构缺乏灵活性,难以满足组织内所有不同部门的需求。
3. 集中多个数据源的数据不仅会耗费大量时间,而且还会导致数据使用者无法按需访问数据。
为了克服这些问题,技术顾问 Zhamak Dehghani 提议采用一种名为“数据网格”的分散式数据基础架构。
在数据网格配置中,组织内的不同部门或群组将拥有单独的“数据域”,由中央自助式数据平台提供支持,并按照一套总体标准进行管理,以确保互操作性。每个数据域都将提供“数据产品”,设计上方便目标受众使用,且符合组织全局标准。
值得一提的是,尽管所有权分散,但预配和治理保持集中。此架构具有直观意义,并有望克服完全集中式基础架构的局限性,但组织如何在获得中央数据平台支持与保持域的独立性之间实现一种微妙的平衡呢?
进入数据虚拟化
Denodo数据虚拟化作为一种数据集成技术,堪称实现数据网格的完美选择。与提取、转换和加载 (ETL) 流程以及其他面向批处理的数据集成方法不同,数据虚拟化让数据使用者无需先将数据复制到集中式存储库即可访问数据。因此,数据虚拟化在本质上可以被视为一种“分散式”数据集成策略。
数据虚拟化是一个建立在组织内不同数据源之上的企业范围的层。要在不同数据源之间进行查询时,数据使用者只需查询数据虚拟化层,然后该层便会检索所需数据,让使用者不必受困于访问的复杂性。
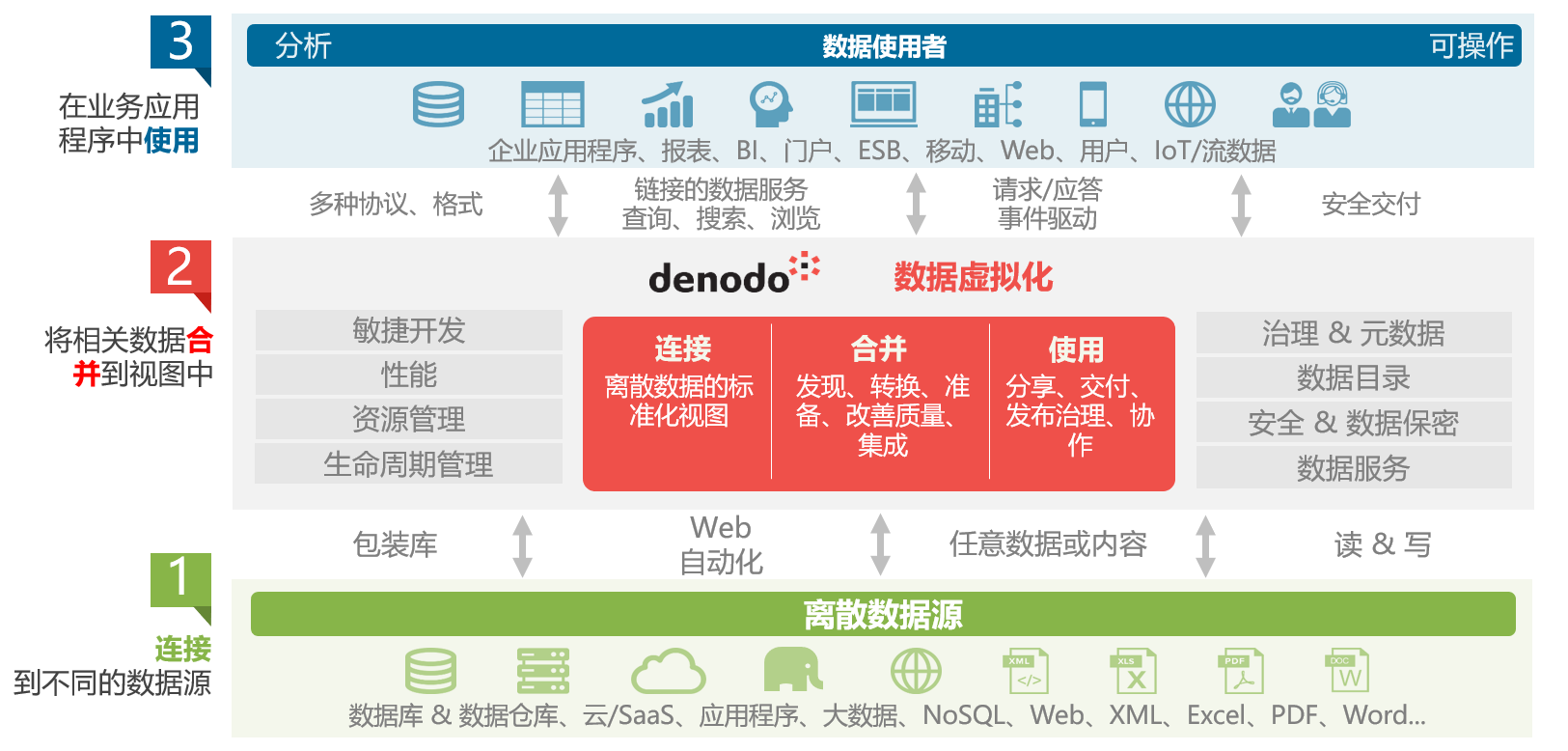
数据虚拟化层不含实际数据;但其存储了访问各种数据源所需的所有元数据。数据虚拟化提供单一位置来存储元数据,支持组织从单一控制点,在整个组织范围内自动实现基于角色的安全性和执行数据治理协议。例如,组织可以自动脱敏处理薪资数据,用户必须拥有必要凭据才可查看此类信息。
数据虚拟化层提供数据网格架构中所需的“自助式数据平台”的所有必要功能。组织可在数据虚拟化层之上实施多个语义层,由不同部门架构,并作为半自治数据域运行。每一个语义层都可以灵活地调整、更改或移除,而不会改变或影响底层数据。此外,组织可以轻松地建立支持跨域重用的标准数据定义。
数据虚拟化和数据产品
数据虚拟化完全适用于数据产品开发。即使编码能力有限,利益相关者也可利用数据虚拟化层创建虚拟模型,无需了解为之馈送信息的数据源的复杂性。随后,他们可以利用一系列灵活的方法(例如 SQL、REST、OData、GraphQL 或 MDX),使这些虚拟模型作为数据产品被访问,此过程同样不需要编写代码。
“开箱即用”型数据虚拟化设置的初衷是为数据产品提供支持,使其兼容数据沿袭跟踪、自主记录、变更影响分析、身份管理和单点登录 (SSO) 等功能。
此外,数据虚拟化还支持在组织范围内的数据产品目录中注册数据产品。通过集中存储元数据,数据虚拟化层可向组织中按域有序排列的数据资产提供全功能综合目录的所有必要成分。
数据虚拟化和数据域自治
数据虚拟化使组织能够在不影响底层数据的情况下,在源数据之上构建视图和语义模型,因此,数据虚拟化为数据域自治提供了现成的基础。
在基于数据虚拟化的架构中,数据域利益相关者将能够选择为其产品馈送数据的数据源,并根据需要更改这一组合。许多业务部门已经在运营自己的数据集市和满足偏好的 SaaS 应用程序,并且在数据网格配置中重用这些内容易如反掌。数据域可以通过数据虚拟化独立扩展。
请务必注意,数据虚拟化不能取代数据仓库和数据湖等单体存储库;数据虚拟化处理此类存储库的方式与任何其他数据源相同,在数据网格配置中,它们将成为网格中的节点。这意味着与现有数据仓库或数据湖联系紧密的数据域可以继续通过这种方式为某些数据产品提供服务,例如需要机器学习的数据产品。在这种情况下,数据产品仍将通过虚拟层被访问,管理数据产品的协议也与管理数据网格其余部分的协议相同。
编织网格
数据网格可以避开高度集中型数据基础架构的许多陷阱,是一种前景广阔的新架构。幸运的是,数据虚拟化作为一种现代数据集成和数据管理技术,有望以一种简单明了的方式落实数据网格理念,而无需更换旧硬件。