目前,Apache Kafka已成为了应用服务间通信的常见选择。Kafka不但能够通过消息并行处理的方式来聚合日志,而且能够应对低延迟、高吞吐量的需求。不过,对于许多微服务应用而言,Kafka的处理速度却不一定够快。

最近,异军突起的开源式Chronicle Queue却可以被用来开发一些只有微秒级延迟的消息传递框架。下面,我将和您深入地从微服务应用的吞吐量和可扩展性方面,比较Kafka与Chronicle Queue。
将延迟类比为距离
为了说明延迟,让我们来做一个类比:通常,光线会以大约三分之二的光速在真空的光纤和铜线中传输,由此产生的瞬间延迟,可以被理解为信号在这段时间内所传播的距离。
使用Chronicle的微服务延迟
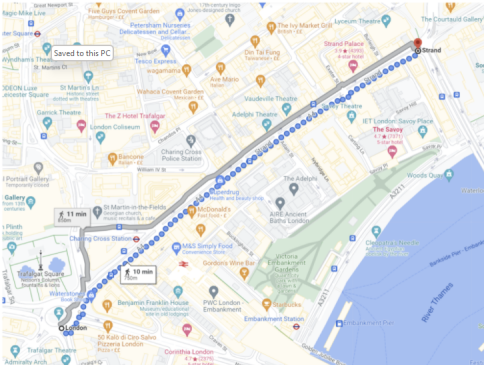
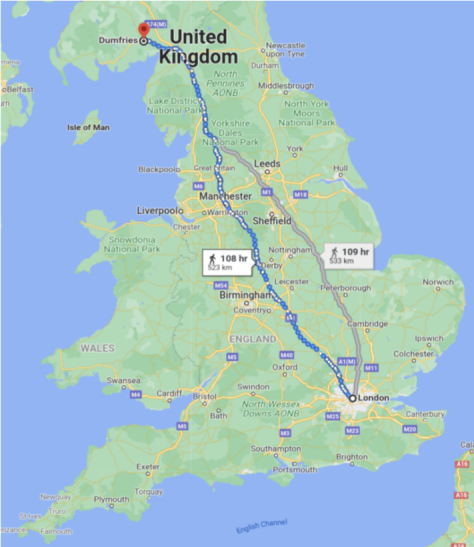
Chronicle Queue的企业版(Enterprise)在500k msg/s的低吞吐量下,99%ile(正态分布中的平均值)的单个微服务的端到端延迟为3.69微秒。这等同于信号传播了750米的距离,也就是普通人在伦敦市中心步行10分钟的直线距离(请参见下图)。
使用Kafka的微服务延迟
如果使用Kafka进行相同的测试,那么在100k 消息/秒(msg/s)的低吞吐量下,99%ile的单个微服务的端到端延迟约为2633微秒(如果是150k msg/s的话,延迟则会显著增加)。这等同于信号传播了526公里,也就是普通人花费100多个小时,从伦敦步行到达苏格兰的邓弗里斯(Dumfries)。
日志聚合
针对日志聚合的需求,Kafka在最初的设计中就能够提供多个连接器。因此,在典型的系统中,使用Kafka代替写入日志文件,能够达到提高性能、并显著提高可管理性的效果。
测试场景
我在Ryzen 9 5950X服务器上部署并运行着Ubuntu 21.04。为了保持一致性,所有测试均会使用相同的MP600 PRO XT 2TB M.2 NVMe驱动。您可以通过链接--https://github.com/OpenHFT/Microservice-Benchmark,获取基准测试的源代码。
开源式Chronicle Queue v5.22ea14会使用Chronicle Wire进行序列化,并以500k msg/s的速度写入。您可以针对单个生产者(Producer),以及下游的单个消费者(Consumer)进行如下配置:
-Dworkload=500kps.yaml chronicle.yaml
Chronicle Queue企业版v2.22ea72也使用Chronicle Wire进行序列化,并以500k msg/s的速度写入。您可以针对异步缓冲区模式下的单个生产者,以及下游的单个消费者,进行如下配置:
-Dworkload=500kps.yaml chronicle-async.yaml
而带有Jackson的Kafka 3.0.0在高吞吐量延迟的配置(主要是指linger.ms=1)下,可以100k msg/s的速度写入。您可以针对JSON的4个分区和8个消费者,进行如下配置:
-Dworkload=100kps.yamlKafka.yaml
带有Jackson的Kafka 3.0.0在高吞吐量延迟的配置(主要是指linger.ms=1)下,则可以250k msg/s的速度写入。您可以针对JSON的4个分区和8个消费者,进行如下配置:
-Dworkload=250kps.yamlKafka.yaml
比较
分区和消费者的数量会在一定程度上影响到延迟。对于Chronicle Queue而言,在100k msg/s和500k msg/s下的性能表现大致相同。也就是说,Chronicle Queue的一项重要特征便是:性能基本不会受到发布者和消费者数量的影响。因此,我们针对500k msg/s的需求,采取一个发布者(publisher)、一个消费者(consumer)和一个微服务。
如果以500k msg/s对Kafka进行基准测试,则会导致消息出现排队。而且基准运行的时间越长,延迟就会越明显。例如,一旦出现2分钟的突发流量峰值,就会导致接近1分钟的延迟。
而如果想让Kafka以250k msg/s的水平运行,则至少需要4个消费者。当然,如果设置8个消费者的基准,那么效果会更好,毕竟它会调用到Kafka的扩展技术。
发布延迟
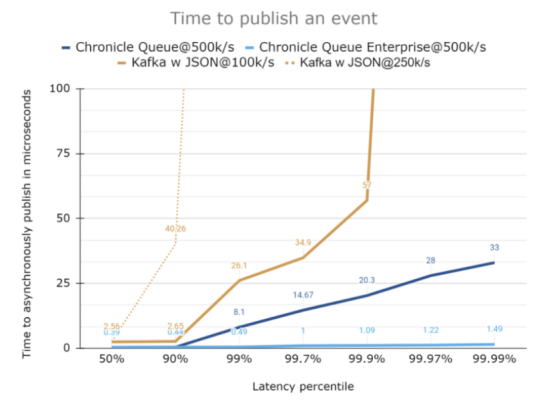
上图比较了两者在发布上的延迟。仅从图表看来,它们的差异可能十分明显,但是在实际测试用例中,其间的延迟不会超过2.6微秒。就测试用例而言,其代码如下。它在不同情况所发布的事件,都是512字节的JSON消息。而在消息被发送时,我们添加了两个字段以进行跟踪。
微服务消息传输
虽然我们在上面讨论的发布时间、以及收发预序列化消息的时间,能够很好地比较Kafka与Chronicle这两个消息传递方案。但是这只是延迟难题的一部分。对于微服务而言,您需要知道从描述待处理事件的DTO(数据传输对象)开始,到下游消费者从原始微服务中读取生成的DTO的时间。对此,我们需要通过针对微服务的基准测试,来获悉如下发送相同事件的各个端到端阶段的用时:
- 添加高精度的时间戳 (System.nanoTime())
- 序列化第一条消息
- 发布第一条消息
- 消费第一条消息
- 反序列化第一条消息
- 调用微服务
- 添加第二个高精度时间戳
- 序列化另一个主题/队列上的第二条消息
- 发布第二条消息
- 消费第二条消息
- 反序列化第二条消息
- 记录端到端延迟
注意:每条消息在生成时,都会创建第二条消息作为响应,因此与单跳跃(single-hop)消息传递基准相比,实际消息的数量会翻一倍。
Kafka在其已发布的基准测试中表现如何?
虽然在Kafka上发布事件通常需要几微秒的时间,但端到端传输则会扩大到几毫秒。根据Confluent发布的有关单跳跃复制消息基准的报告,有99%的端到端传输延迟为5毫秒。
而在我们的基准测试中,一台主机上有2个跳跃点、序列化和反序列化。它们在100k msg/s输出和100k msg/s返回的情况下,单个跳跃消息传输所出现的延迟与200k msg/s基本类似。
端到端延迟
为了进一步弄清楚到底Kafka与Chronicle在延迟上的差距有多大,我们需要通过下列图表来进一步分析。为了便于比较,后一张图表是前一张表放大10倍情况。
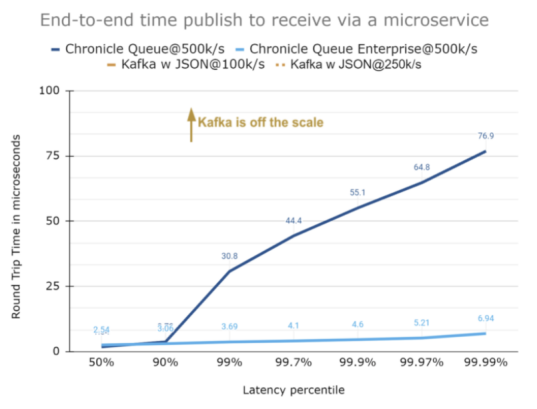
延迟达100微秒的情况
在保持与之前的规模相同的情况下,即使跨越了2个跳跃点(包括序列化),我们仍然可以看到:Chronicle Queue企业版保持着延迟的一致性;而开源式Chronicle Queue虽然在大部分时间内执行了相同的操作,但是它具有更高的延迟。这是因为Chronicle Queue企业版在开源的基础上,包含了一些特定的功能,可以更好地控制异常值。当然,由于延迟相当高,因此您在下图中看不到Kafka的相关曲线。
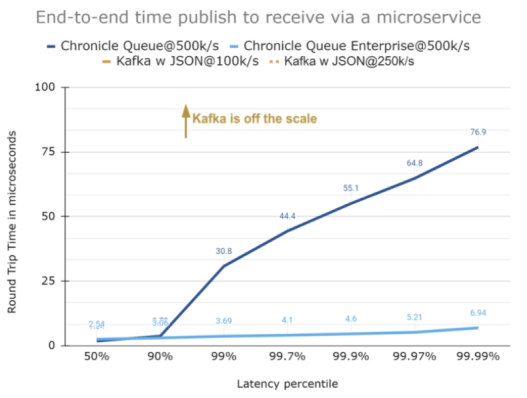
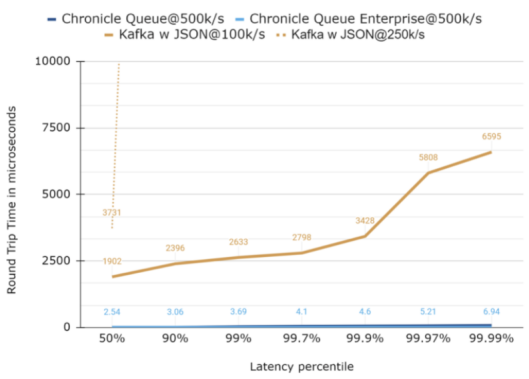
延迟达1000微秒的情况
下图是放大10倍比例的情况。如您所见,虽然Chronicle Queue带有更高的异常值,但是它们在99.99的分位上是相当一致的。同样,Kafka的曲线仍然没法显示。
延迟达10,000微秒的情况
下图是再放大10倍的情况。在这种规模下,我们无法看到Chronicle基准测试的太多细节,不过出现了两种Kafka配置的典型延迟。特别是在100k msg/s(总共200k msg/s)的情况下,99%延迟约为2,630微秒。这与Confluent的5毫秒基准测试非常相似。
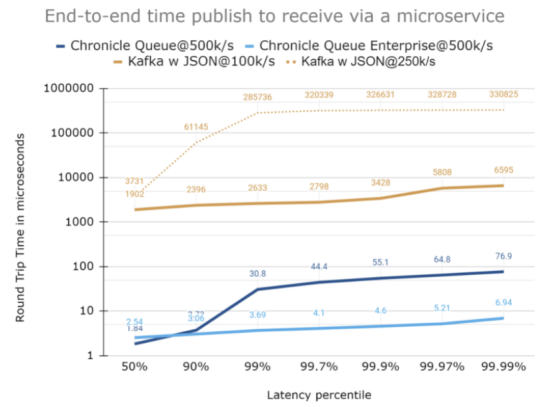
对延迟使用对数标度
对于较大范围的数值,使用对数标度往往非常实用。如下图所示,它虽然具有一定的可读性,但是由于多数人不太习惯认读对数比例图表,因此他们很难解读出延迟到底有多大的不同。
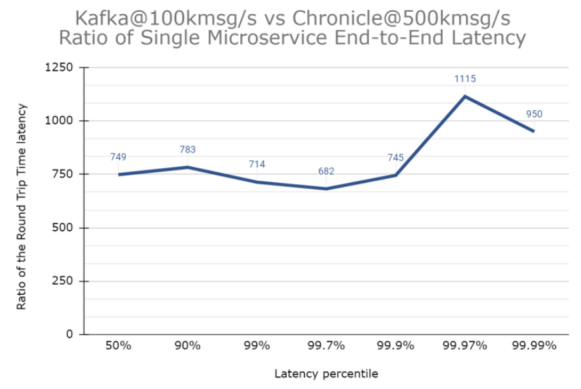
延迟到底有多大?
另一种可视化Kafka延迟的方法是绘制Kafka和Chronicle之间的延迟比率。下图是Kafka在100k msg/s(最佳结果之一)和Chronicle Queue企业版在500k msg/s(即负载为Kafka的5倍)之间的延迟比率图。在该基准测试中,即使其吞吐量只是Chronicle Queue的五分之一,Kafka仍然始终慢了至少680倍。
而且,为了让Kafka能够以100k msg/s的吞吐量实现其最低延迟,我们使用了4个分区和8个微服务。作为比较,Chronicle Queue在所有情况下都只需要1个足矣。
Chronicle Queue堆(Heap)的使用
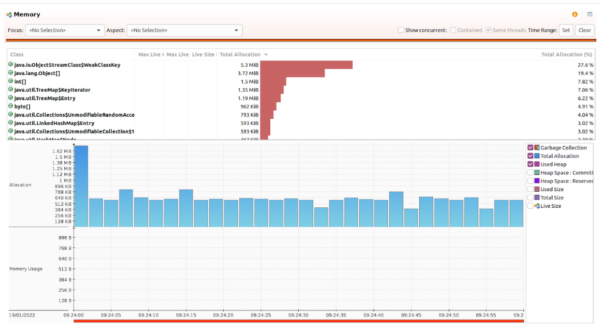
我们让Chronicle Queue以500k msg/s的消息写入速度,并通过使用G1收集器和默认的GC参数,产生40 MB的峰值堆大小,并持续运行了5分钟(总共3亿条消息)的基准测试。其结果如下图所示。当然,Chronicle Queue并没有使用到标准的Java序列化功能。
Kafka内存的使用
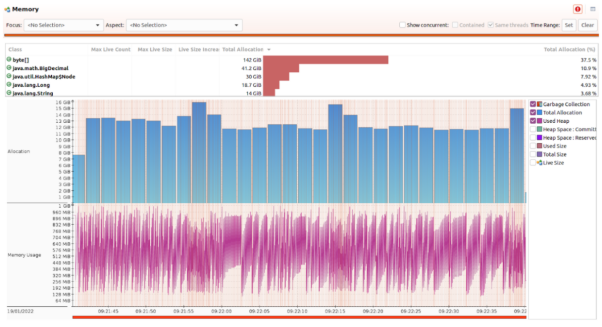
我们让Kafka以250k/s的消息写入速度,使用2.87 GB的堆峰值,持续了10分钟基准测试(总共3亿条消息)。在启动后,它触发了2,410个暂停收集,以及182个并发循环收集。下图展示了该测试在128 MB堆大小下运行时,所产生的超过139 k的GC。
小结
虽然Kafka是日志聚合的不错选择,但由于其相对较高的端到端延迟,对于许多涉及到微服务的用例而言,其延迟可能会比较明显。开源式的Chronicle Queue在超过99.99%的时间内,都能够实现低于100微秒的一致性延迟。而Kafka即使在吞吐量只有Chronicle的五分之一的情况下,也会有7毫秒的异常值。
译者介绍
陈峻 (Julian Chen),51CTO社区编辑,具有十多年的IT项目实施经验,善于对内外部资源与风险实施管控,专注传播网络与信息安全知识与经验;持续以博文、专题和译文等形式,分享前沿技术与新知;经常以线上、线下等方式,开展信息安全类培训与授课。
原文标题:Kafka vs Chronicle for Microservices,作者:Peter Lawrey