














前言
事务是 mongoDB 中非常核心的一个功能,在 4.0 版本以前,mongoDB 只支持单个文档的事务,在 4.0 和 4.2 版本之后,分别支持了复制集事务和分片事务,也可以说在大多数的数据库中都是非常重要的一个功能,值得我们单独拉一章去讲解。
那「怎么样在 mongoDB 中合理的使用事务来保证数据安全呢」?
后续我将会从读、写和多文档事务这三个方向去阐述。
写事务
使用 writeConcern 保证数据准确落盘。
writeConcern 中有两个选项。
w(决定一条数据落到写到多少个节点才算真正成功)。
- 0:不关心(最不安全)。
- 数字:写到 n 个节点才算成功(自定义)。
- majority:写入至少一半的节点才算成功(推荐,性能和安全均衡)。
- all:全部写完才算成功(性能差点,很安全,但是只要有一个失败就会失败)。
j(决定怎样才算真正成功)。
- true:写入 journal 日志 才算成功。
- false:写入内存就算成功。
db.collection.insert({a:1},{writeConcen:{w:"majority",j:true});
对于一些「普通数据可以使用 w:1 来确保最佳性能」,对于「重要数据可以用 w:majority 来保证数据安全」。
读事务
readPreference 来确定从哪里读。
readPreference 有几个属性。
- primary:只从主节点读。
- primaryPreferred:先读主节点,如果挂了再读从节点。
- secondary:只从从节点读。
- secondaryPreferred:先读从节点,如果挂了在读主节点。
- nearest:读最近的节点。
「primiry 和 primaryPreferred 适用于对延迟敏感读较高」的数据,比如订单信息。
「secondary 和 secondaryPreferred 适用于对延迟敏感度要求较低」的数据,比如日志信息。
「nearest 适用于业务域较广的应用」,比如将业务信息同步到全球各地的节点,「中国用户会访问中国的节点,俄罗斯用户会访问俄罗斯的节点」, nearest 的判断也是比较简单的,直接是使用应用到 mongo 服务器的的 ping time 来决定。
当然,还有一种是给「服务器打标签(tag) 的方式」,比如要将读取操作定向到标记有 "name": "a"和"key": "person"的辅助节点集:
db.collection.find({}).readPref( "secondary", [ { "name": "a", "key": "person" } ] )
readConcern 来确定可以读什么样的数据。
readConcern 有几个属性。
- available:读取所有可用的数据。
- loacl:读取所有可用且仅属于当前分片的数据。
- majority:读取大多数节点都写入的数据。
「通过快照来维护多个不同的版本,使用 MVCC 实现」,每个被大多数节点确认过的数据就是一个快照。
- linearizable:可线性化读取文档。
有时会被阻塞,其保证如果一个线程已经完成了写入并且告知了其他线程,那么这其他的线程就可以看到这些改动。如果某一瞬间你的副本集出现了两个主节点(有一个还未来得及降级)然后你从这个老的主节点上进行读取,与此同时新的主节点上已经有了新的数据,你读到的数据就是旧数据。
- snapshot:读取快照中的数据(类似于可串行化)。
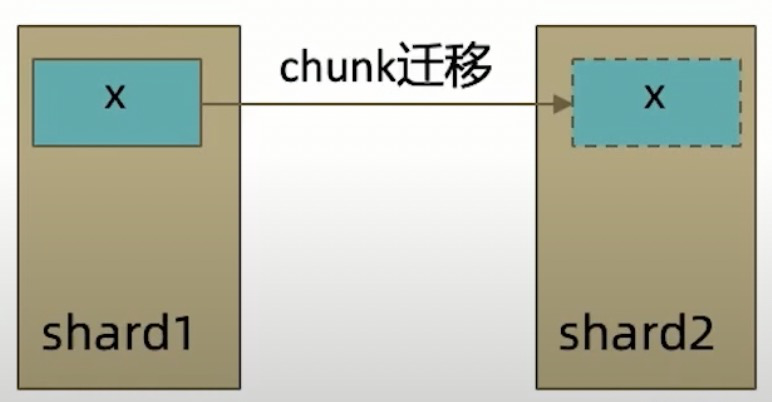
loacl 和 available 的区别体现在分片集群中的 chunk 迁移上,如果读 shard2 ,loacl 不能读到 x ,但是 available 可以读到。
多文档事务
- 4.0 版本 mongoDB 支持了复制集的多文档事务。
- 4.2 版本 mongoDB 支持了分片集群的多文档事务。
也就是说是说,mongoDB 在 4.2 版本的是有拥有了和 mysql 这种关系型数据库一样的事务能力,这对于业务的选择角度来讲,又给 mongoDB 添加了一笔浓重的色彩。
在整个数据库的分布式事务当中,还需要重点提一嘴的就是时间问题,我们先来看看会有什么问题存在。

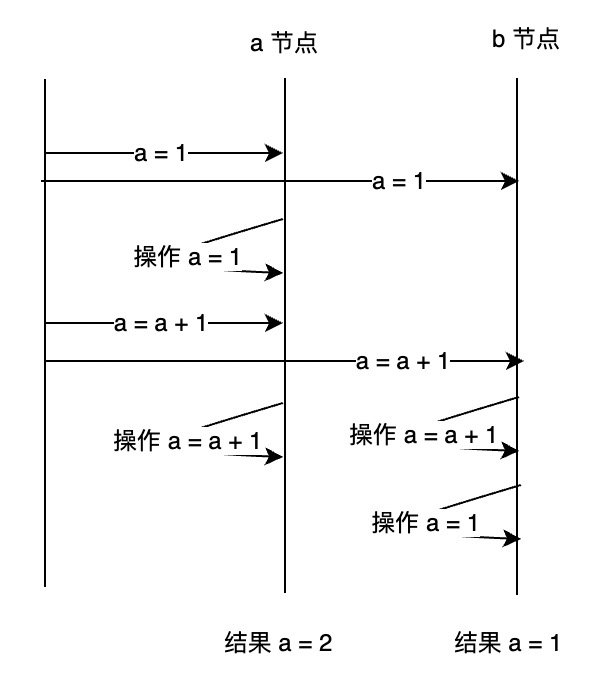
比如有两个操作发向 a、b 两个节点。
- 客户端将 a = 1 发向 a、b 节点。
- a 节点操作 a =1。
- 客户端将 a = a +1 发送给 a、b 节点。
- a 节点操作 a = a + 1。
- b 节点由于业务网络等原因先执行了 a = a + 1,后操作了 a = 1。
最后我们就发现,a、b 两个节点的数据不一致了,那么 mongo 是怎么解决的呢,一般是两种方式:
- 「全局授时」:;比如我们可以采用GPS时钟或者是NTP服务这种全局授时点。
- 「逻辑时钟」:也就是我们采用一种局部的时间戳的方式去演进,这个就叫逻辑时钟。
mongo 采用的是「混合逻辑时钟」:
在这个混合逻辑时钟中,将物理时钟和逻辑时钟混合起来做一个全局的时间出来处理。我们的混合逻辑时钟会采用一种本地的推进方式,这个就是刚才说的一个接受的时候,他会比较本地的时间戳,然后在本地时间戳、本地真实的物理时间和收到最短 request 的时间,「三者取最大的时间,作为本地时间的一个推进」,需要说明的是,这个时间戳的分配是取决于 oplog 的时间戳。只有「当 oplog 真正写入数据的时候,本地的逻辑时钟才会向前推进」。在整个混合逻辑时钟,在整个集群中采用动态推进的方式,「每一条发送和接收的请求,都会依据请求中的时间来推进本地的时钟」,这样在全局的情况下,每个节点的混合逻辑时钟最终会趋同,趋向同一个地址,趋向同一个时间。这样的话,刚才说的时间偏差就已经不存在了,才可以在集群中做分布式事务。
再说说 mongo 提交事务的过程吧。
mongoDb 的分布式事务和 mysql 一样,也是基于「两阶段协议」。
- 第一阶段就是 prepare 阶段,在 prepare 过程中,所有的 coordinator 会向所有的节点去发送 prepare 命令,所有的节点收到了这个命令以后会返回自己的 prepare timestamp,然后由协调节点去决定选取一个最大的 prepare ts 作为 commit timestamp。
coordinator 和所有的 shard 之间的通讯会促使所有的事务参与者得到一个协调一致的 HLC。在这种逻辑时钟一致的情况下,commit timestamp 就是全局顺序一致的。
- 第二阶段的话就是提交阶段, coordinator 会将刚刚的 committed ts 作为 commit timestamp 的时间戳,然后向所有的节点去广播。
需要关注一点,就是在对具有 prepare timestamp 的事务进行读取的时候,如果当前的事务是处于 prepare 状态的,并不确定自身的读时间戳和 prepare 状态的大小的话,需要去一直等待这个事务,等到事务提交或者 abort 以后才去会处理,这个就是刚才所说的。
- https://mongoing.com/archives/77608。
- 巨人的肩膀。
mongoDB 整个事务实现的方式都是按照「读提交」这种关系来设计的,也就是说,在客户端读取数据的时候,只能读到该事务节点前已经做了 commit 的数据。






























