作者 | kylinkzhang,腾讯 CSIG 后台开发工程师

一致性 Hash 算法背景
考虑这么一种场景:
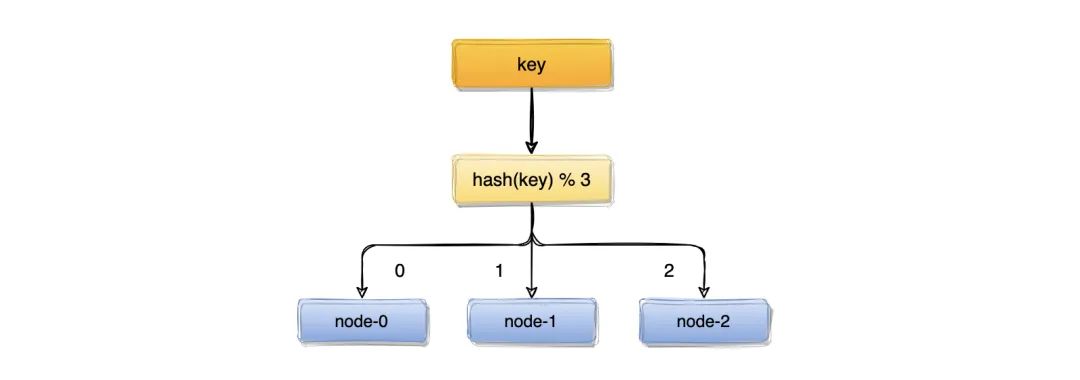
我们有三台缓存服务器编号node0、node1、node2,现在有 3000 万个key,希望可以将这些个 key 均匀的缓存到三台机器上,你会想到什么方案呢?
我们可能首先想到的方案是:取模算法hash(key)% N,即:对 key 进行 hash 运算后取模,N 是机器的数量;
这样,对 key 进行 hash 后的结果对 3 取模,得到的结果一定是 0、1 或者 2,正好对应服务器node0、node1、node2,存取数据直接找对应的服务器即可,简单粗暴,完全可以解决上述的问题;
取模算法虽然使用简单,但对机器数量取模,在集群扩容和收缩时却有一定的局限性:因为在生产环境中根据业务量的大小,调整服务器数量是常有的事;
而服务器数量 N 发生变化后hash(key)% N计算的结果也会随之变化!
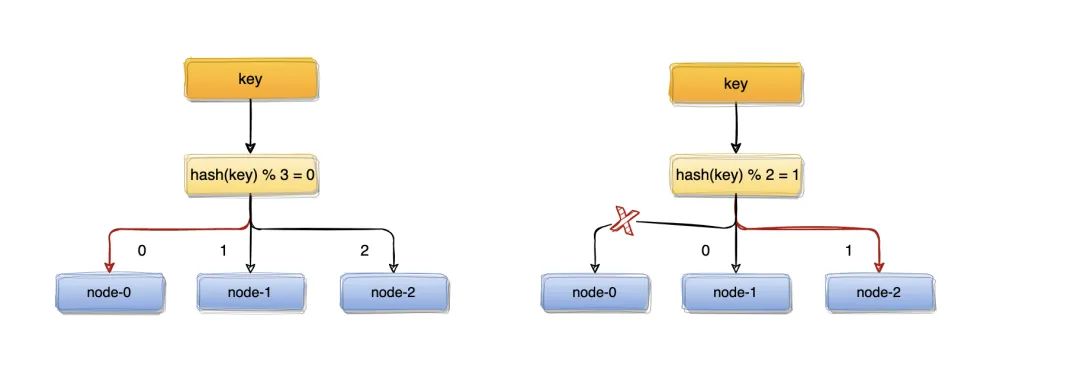
比如:一个服务器节点挂了,计算公式从hash(key)% 3变成了hash(key)% 2,结果会发生变化,此时想要访问一个 key,这个 key 的缓存位置大概率会发生改变,那么之前缓存 key 的数据也会失去作用与意义;
大量缓存在同一时间失效,造成缓存的雪崩,进而导致整个缓存系统的不可用,这基本上是不能接受的;
为了解决优化上述情况,一致性 hash 算法应运而生~
一致性 Hash 算法详述
算法原理
一致性哈希算法在 1997 年由麻省理工学院提出,是一种特殊的哈希算法,在移除或者添加一个服务器时,能够尽可能小地改变已存在的服务请求与处理请求服务器之间的映射关系;一致性哈希解决了简单哈希算法在分布式哈希表(Distributed Hash Table,DHT)中存在的动态伸缩等问题;
一致性 hash 算法本质上也是一种取模算法;
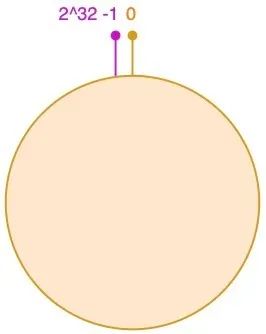
不过,不同于上边按服务器数量取模,一致性 hash 是对固定值 2^32 取模;
IPv4 的地址是 4 组 8 位 2 进制数组成,所以用 2^32 可以保证每个 IP 地址会有唯一的映射;
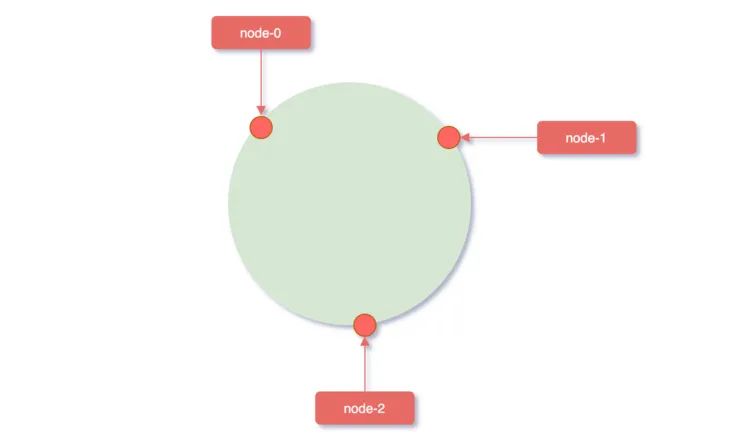
① hash 环
我们可以将这2^32个值抽象成一个圆环 ⭕️,圆环的正上方的点代表 0,顺时针排列,以此类推:1、2、3…直到2^32-1,而这个由 2 的 32 次方个点组成的圆环统称为hash环;
② 服务器映射到 hash 环
在对服务器进行映射时,使用hash(服务器ip)% 2^32,即:
- 使用服务器 IP 地址进行 hash 计算,用哈希后的结果对2^32取模,结果一定是一个 0 到2^32-1之间的整数;
- 而这个整数映射在 hash 环上的位置代表了一个服务器,依次将node0、node1、node2三个缓存服务器映射到 hash 环上;
③ 对象 key 映射到服务器
在对对应的 Key 映射到具体的服务器时,需要首先计算 Key 的 Hash 值:hash(key)% 2^32;
注:此处的 Hash 函数可以和之前计算服务器映射至 Hash 环的函数不同,只要保证取值范围和 Hash 环的范围相同即可(即:2^32);
将 Key 映射至服务器遵循下面的逻辑:
- 从缓存对象 key 的位置开始,沿顺时针方向遇到的第一个服务器,便是当前对象将要缓存到的服务器;
- 假设我们有 "semlinker"、"kakuqo"、"lolo"、"fer" 四个对象,分别简写为 o1、o2、o3 和 o4;
首先,使用哈希函数计算这个对象的 hash 值,值的范围是 [0, 2^32-1]:

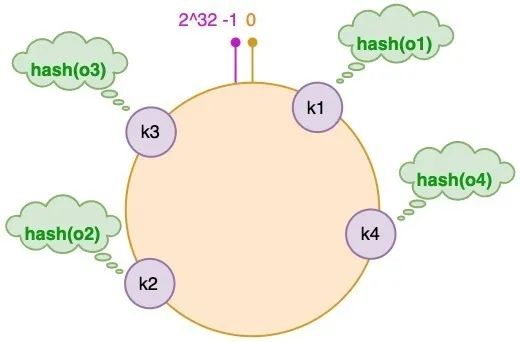
图中对象的映射关系如下:
hash(o1) = k1; hash(o2) = k2;
hash(o3) = k3; hash(o4) = k4;
同时 3 台缓存服务器,分别为 CS1、CS2 和 CS3:
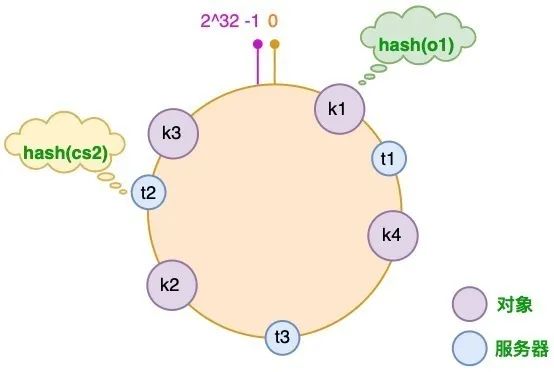
则可知,各对象和服务器的映射关系如下:
K1 => CS1
K4 => CS3
K2 => CS2
K3 => CS1
即:
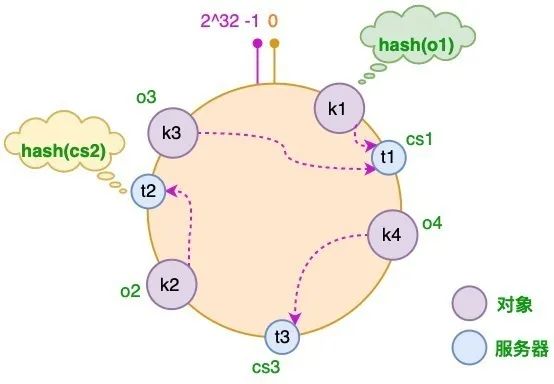
以上便是一致性 Hash 的工作原理。
可以看到,一致性 Hash 就是:将原本单个点的 Hash 映射,转变为了在一个环上的某个片段上的映射!
下面我们来看几种服务器扩缩容的场景:
服务器扩缩容场景
① 服务器减少
假设 CS3 服务器出现故障导致服务下线,这时原本存储于 CS3 服务器的对象 o4,需要被重新分配至 CS2 服务器,其它对象仍存储在原有的机器上:
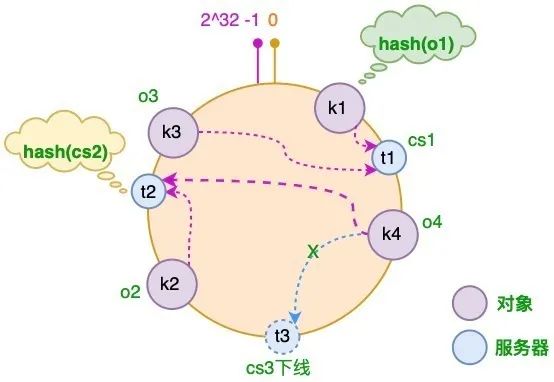
此时受影响的数据只有 CS2 和 CS3 服务器之间的部分数据!
② 服务器增加
假如业务量激增,我们需要增加一台服务器 CS4,经过同样的 hash 运算,该服务器最终落于 t1 和 t2 服务器之间,具体如下图所示:

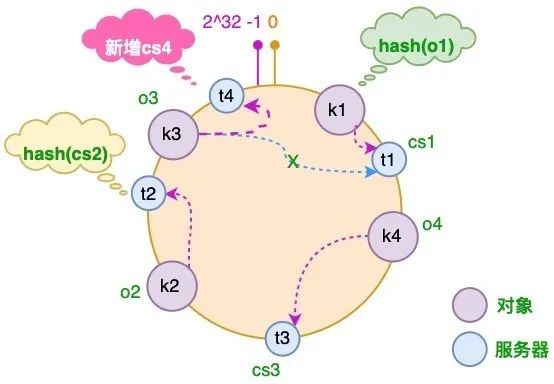
- 此时,只有 t1 和 t2 服务器之间的部分对象需要重新分配;
- 在以上示例中只有 o3 对象需要重新分配,即它被重新到 CS4 服务器;
在前面我们已经说过:如果使用简单的取模方法,当新添加服务器时可能会导致大部分缓存失效,而使用一致性哈希算法后,这种情况得到了较大的改善,因为只有少部分对象需要重新分配!
数据偏斜&服务器性能平衡问题
(1) 引出问题
在上面给出的例子中,各个服务器几乎是平均被均摊到 Hash 环上,但是在实际场景中很难选取到一个 Hash 函数这么完美的将各个服务器散列到 Hash 环上。
此时,在服务器节点数量太少的情况下,很容易因为节点分布不均匀而造成数据倾斜问题。
如下图被缓存的对象大部分缓存在node-4服务器上,导致其他节点资源浪费,系统压力大部分集中在node-4节点上,这样的集群是非常不健康的:
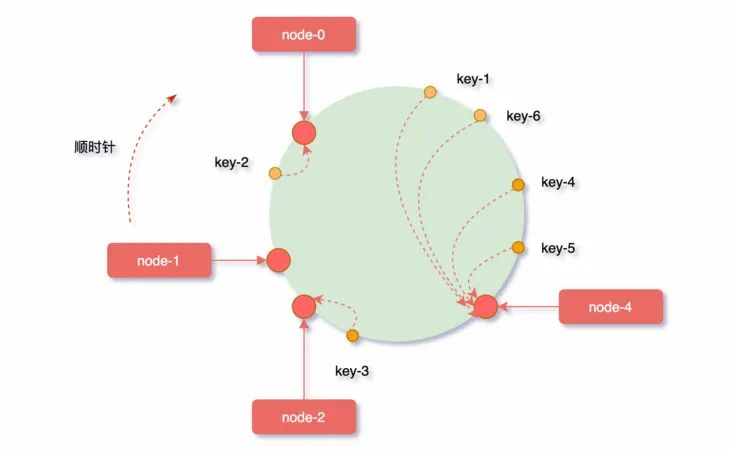
同时,还有另一个问题:
在上面新增服务器 CS4 时,CS4 只分担了 CS1 服务器的负载,服务器 CS2 和 CS3 并没有因为 CS4 服务器的加入而减少负载压力;如果 CS4 服务器的性能与原有服务器的性能一致甚至可能更高,那么这种结果并不是我们所期望的;
(2) 虚拟节点
针对上面的问题,我们可以通过:引入虚拟节点来解决负载不均衡的问题:
即将每台物理服务器虚拟为一组虚拟服务器,将虚拟服务器放置到哈希环上,如果要确定对象的服务器,需先确定对象的虚拟服务器,再由虚拟服务器确定物理服务器。
如下图所示:
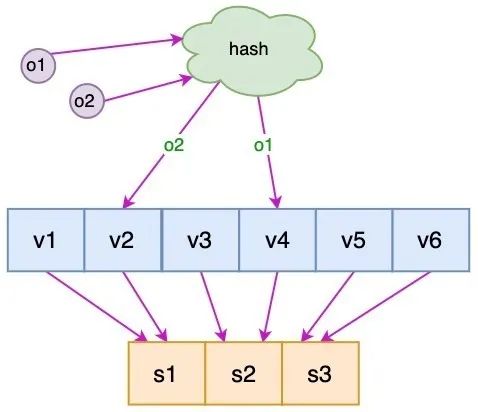
在图中:o1 和 o2 表示对象,v1 ~ v6 表示虚拟服务器,s1 ~ s3 表示实际的物理服务器。
(3) 虚拟节点的计算
虚拟节点的 hash 计算通常可以采用:对应节点的 IP 地址加数字编号后缀 hash(10.24.23.227#1) 的方式。
举个例子,node-1 节点 IP 为 10.24.23.227,正常计算node-1的 hash 值:
- hash(10.24.23.227#1)% 2^32
假设我们给 node-1 设置三个虚拟节点,node-1#1、node-1#2、node-1#3,对它们进行 hash 后取模:
- hash(10.24.23.227#1)% 2^32
- hash(10.24.23.227#2)% 2^32
- hash(10.24.23.227#3)% 2^32
注意:
- 分配的虚拟节点个数越多,映射在 hash 环上才会越趋于均匀,节点太少的话很难看出效果;
- 引入虚拟节点的同时也增加了新的问题,要做虚拟节点和真实节点间的映射,对象key->虚拟节点->实际节点之间的转换;
(4) 使用场景
一致性 hash 在分布式系统中应该是实现负载均衡的首选算法,它的实现比较灵活,既可以在客户端实现,也可以在中间件上实现,比如日常使用较多的缓存中间件memcached和redis集群都有用到它。
memcached 的集群比较特殊,严格来说它只能算是伪集群,因为它的服务器之间不能通信,请求的分发路由完全靠客户端来的计算出缓存对象应该落在哪个服务器上,而它的路由算法用的就是一致性 hash。
还有 redis 集群中 hash 槽的概念,虽然实现不尽相同,但思想万变不离其宗,看完本篇的一致性 hash,你再去理解 redis 槽位就轻松多了。
其它的应用场景还有很多:
- RPC框架Dubbo用来选择服务提供者
- 分布式关系数据库分库分表:数据与节点的映射关系
- LVS负载均衡调度器
- ……
一致性 Hash 算法实现
下面我们根据上面的讲述,使用 Golang 实现一个一致性 Hash 算法,这个算法具有一些下面的功能特性:
- 一致性 Hash 核心算法;
- 支持自定义 Hash 算法;
- 支持自定义虚拟节点个数;
具体源代码见:https://github.com/JasonkayZK/consistent-hashing-demo
下面开始实现吧!
结构体、错误以及常量定义
① 结构体定义
首先定义每一台缓存服务器的数据结构:
core/host.go
type Host struct {
// the host id: ip:port
Name string
// the load bound of the host
LoadBound int64
}
其中:
- Name:缓存服务器的 Ip 地址 + 端口,如:127.0.0.1:8000
- LoadBound:缓存服务器当前处理的“请求”缓存数,这个字段在后文含有负载边界值的一致性 Hash中会用到;
其次,定义一致性 Hash 的结构:
core/algorithm.go
// Consistent is an implementation of consistent-hashing-algorithm
type Consistent struct {
// the number of replicas
replicaNum int
// the total loads of all replicas
totalLoad int64
// the hash function for keys
hashFunc func(key string) uint64
// the map of virtual nodes to hosts
hostMap map[string]*Host
// the map of hashed virtual nodes to host name
replicaHostMap map[uint64]string
// the hash ring
sortedHostsHashSet []uint64
// the hash ring lock
sync.RWMutex
}
其中:
- replicaNum:表示每个真实的缓存服务器在 Hash 环中存在的虚拟节点数;
- totalLoad:所有物理服务器对应的总缓存“请求”数(这个字段在后文含有负载边界值的一致性 Hash中会用到);
- hashFunc:计算 Hash 环映射以及 Key 映射的散列函数;
- hostMap:物理服务器名称对应的 Host 结构体映射;
- replicaHostMap:Hash 环中虚拟节点对应真实缓存服务器名称的映射;
- sortedHostsHashSet:Hash 环;
- sync.RWMutex:操作 Hash 环时用到的读写锁;
大概的结构如上所示,下面我们来看一些常量和错误的定义。
② 常量和错误定义
常量的定义如下:
core/algorithm.go
const (
// The format of the host replica name
hostReplicaFormat = `%s%d`
)
var (
// the default number of replicas
defaultReplicaNum = 10
// the load bound factor
// ref: https://research.googleblog.com/2017/04/consistent-hashing-with-bounded-loads.html
loadBoundFactor = 0.25
// the default Hash function for keys
defaultHashFunc = func(key string) uint64 {
out := sha512.Sum512([]byte(key))
return binary.LittleEndian.Uint64(out[:])
}
)
分别表示:
- defaultReplicaNum:默认情况下,每个真实的物理服务器在 Hash 环中虚拟节点的个数;
- loadBoundFactor:负载边界因数(这个字段在后文含有负载边界值的一致性 Hash中会用到);
- defaultHashFunc:默认的散列函数,这里用到的是 SHA512 算法,并取的是unsigned int64,这一点和上面介绍的0~2^32-1有所区别!
- hostReplicaFormat:虚拟节点名称格式,这里的虚拟节点的格式为:%s%d,和上文提到的10.24.23.227#1的格式有所区别,但是道理是一样的!
还有一些错误的定义:
core/error.go
var (
ErrHostAlreadyExists = errors.New("host already exists")
ErrHostNotFound = errors.New("host not found")
)
分别表示服务器已经注册,以及缓存服务器未找到;
下面来看具体的方法实现!
注册/注销缓存服务器
① 注册缓存服务器
注册缓存服务器的代码如下:
core/algorithm.go
func (c *Consistent) RegisterHost(hostName string) error {
c.Lock()
defer c.Unlock()
if _, ok := c.hostMap[hostName]; ok {
return ErrHostAlreadyExists
}
c.hostMap[hostName] = &Host{
Name: hostName,
LoadBound: 0,
}
for i := 0; i < c.replicaNum; i++ {
hashedIdx := c.hashFunc(fmt.Sprintf(hostReplicaFormat, hostName, i))
c.replicaHostMap[hashedIdx] = hostName
c.sortedHostsHashSet = append(c.sortedHostsHashSet, hashedIdx)
}
// sort hashes in ascending order
sort.Slice(c.sortedHostsHashSet, func(i int, j int) bool {
if c.sortedHostsHashSet[i] < c.sortedHostsHashSet[j] {
return true
}
return false
})
return nil
}
代码比较简单,简单说一下:
首先,检查服务器是否已经注册,如果已经注册,则直接返回已经注册的错误,随后,创建一个 Host 对象,并且在 for 循环中创建多个虚拟节点:
- 根据 hashFunc 计算服务器散列值【注:此处计算的散列值可能和之前的值存在冲突,本实现中暂不考虑这种场景】;
- 将散列值加入 replicaHostMap 中;
- 将散列值加入 sortedHostsHashSet 中;
最后,对 Hash 环进行排序:
- 这里使用数组作为 Hash 环只是为了便于说明,在实际实现中建议选用其他数据结构进行实现,以获取更好的性能;
- 当缓存服务器信息写入 replicaHostMap 映射以及 Hash 环后,即完成了缓存服务器的注册。
② 注销缓存服务器
注销缓存服务器的代码如下:
core/algorithm.go
func (c *Consistent) UnregisterHost(hostName string) error {
c.Lock()
defer c.Unlock()
if _, ok := c.hostMap[hostName]; !ok {
return ErrHostNotFound
}
delete(c.hostMap, hostName)
for i := 0; i < c.replicaNum; i++ {
hashedIdx := c.hashFunc(fmt.Sprintf(hostReplicaFormat, hostName, i))
delete(c.replicaHostMap, hashedIdx)
c.delHashIndex(hashedIdx)
}
return nil
}
// Remove hashed host index from the hash ring
func (c *Consistent) delHashIndex(val uint64) {
idx := -1
l := 0
r := len(c.sortedHostsHashSet) - 1
for l <= r {
m := (l + r) / 2
if c.sortedHostsHashSet[m] == val {
idx = m
break
} else if c.sortedHostsHashSet[m] < val {
l = m + 1
} else if c.sortedHostsHashSet[m] > val {
r = m - 1
}
}
if idx != -1 {
c.sortedHostsHashSet = append(c.sortedHostsHashSet[:idx], c.sortedHostsHashSet[idx+1:])
}
}
和注册缓存服务器相反,将服务器在 Map 映射以及 Hash 环中去除即完成了注销。
这里的逻辑和上面注册的逻辑极为类似,这里不再赘述!
查询 Key(核心)
查询 Key 是整个一致性 Hash 算法的核心,但是实现起来也并不复杂,代码如下:
core/algorithm.go
func (c *Consistent) GetKey(key string) (string, error) {
hashedKey := c.hashFunc(key)
idx := c.searchKey(hashedKey)
return c.replicaHostMap[c.sortedHostsHashSet[idx]], nil
}
func (c *Consistent) searchKey(key uint64) int {
idx := sort.Search(len(c.sortedHostsHashSet), func(i int) bool {
return c.sortedHostsHashSet[i] >= key
})
if idx >= len(c.sortedHostsHashSet) {
// make search as a ring
idx = 0
}
return idx
}
代码首先计算 key 的散列值,
随后,在 Hash 环上“顺时针”寻找可以缓存的第一台缓存服务器:
idx := sort.Search(len(c.sortedHostsHashSet), func(i int) bool {
return c.sortedHostsHashSet[i] >= key
})
注意到,如果 key 比当前 Hash 环中最大的虚拟节点的 hash 值还大,则选择当前 Hash 环 中 hash 值最小的一个节点(即“环形”的逻辑):
if idx >= len(c.sortedHostsHashSet) {
// make search as a ring
idx = 0
}
- searchKey 返回了虚拟节点在 Hash 环数组中的 index;
- 随后,我们使用 map 返回 index 对应的缓存服务器的名称即可。
至此,一致性 Hash 算法基本实现,接下来我们来验证一下。
一致性 Hash 算法实践与检验
算法验证前准备
① 缓存服务器准备
在验证算法之前,我们还需要准备几台缓存服务器,为了简单起见,这里使用了 HTTP 服务器作为缓存服务器,具体代码如下所示:
server/main.go
package main
import (
"flag"
"fmt"
"net/http"
"sync"
"time"
)
type CachedMap struct {
KvMap sync.Map
Lock sync.RWMutex
}
var (
cache = CachedMap{KvMap: sync.Map{}}
port = flag.String("p", "8080", "port")
regHost = "http://localhost:18888"
expireTime = 10
)
func main() {
flag.Parse()
stopChan := make(chan interface{})
startServer(*port)
<-stopChan
}
func startServer(port string) {
hostName := fmt.Sprintf("localhost:%s", port)
fmt.Printf("start server: %s\n", port)
err := registerHost(hostName)
if err != nil {
panic(err)
}
http.HandleFunc("/", kvHandle)
err = http.ListenAndServe(":"+port, nil)
if err != nil {
err = unregisterHost(hostName)
if err != nil {
panic(err)
}
panic(err)
}
}
func kvHandle(w http.ResponseWriter, r *http.Request) {
_ = r.ParseForm()
if _, ok := cache.KvMap.Load(r.Form["key"][0]); !ok {
val := fmt.Sprintf("hello: %s", r.Form["key"][0])
cache.KvMap.Store(r.Form["key"][0], val)
fmt.Printf("cached key: {%s: %s}\n", r.Form["key"][0], val)
time.AfterFunc(time.Duration(expireTime)*time.Second, func() {
cache.KvMap.Delete(r.Form["key"][0])
fmt.Printf("removed cached key after 3s: {%s: %s}\n", r.Form["key"][0], val)
})
}
val, _ := cache.KvMap.Load(r.Form["key"][0])
_, err := fmt.Fprintf(w, val.(string))
if err != nil {
panic(err)
}
}
func registerHost(host string) error {
resp, err := http.Get(fmt.Sprintf("%s/register?host=%s", regHost, host))
if err != nil {
return err
}
defer resp.Body.Close()
return nil
}
func unregisterHost(host string) error {
resp, err := http.Get(fmt.Sprintf("%s/unregister?host=%s", regHost, host))
if err != nil {
return err
}
defer resp.Body.Close()
return nil
}
- 代码接受由命令行指定的 -p 参数指定服务器端口号;
- 代码执行后,会调用 startServer 函数启动一个 http 服务器;
在 startServer 函数中,首先调用 registerHost 在代理服务器上进行注册(下文会讲),并监听 / 路径,具体代码如下:
func startServer(port string) {
hostName := fmt.Sprintf("localhost:%s", port)
fmt.Printf("start server: %s\n", port)
err := registerHost(hostName)
if err != nil {
panic(err)
}
http.HandleFunc("/", kvHandle)
err = http.ListenAndServe(":"+port, nil)
if err != nil {
err = unregisterHost(hostName)
if err != nil {
panic(err)
}
panic(err)
}
}
kvHandle 函数对请求进行处理:
func kvHandle(w http.ResponseWriter, r *http.Request) {
_ = r.ParseForm()
if _, ok := cache.KvMap.Load(r.Form["key"][0]); !ok {
val := fmt.Sprintf("hello: %s", r.Form["key"][0])
cache.KvMap.Store(r.Form["key"][0], val)
fmt.Printf("cached key: {%s: %s}\n", r.Form["key"][0], val)
time.AfterFunc(time.Duration(expireTime)*time.Second, func() {
cache.KvMap.Delete(r.Form["key"][0])
fmt.Printf("removed cached key after 3s: {%s: %s}\n", r.Form["key"][0], val)
})
}
val, _ := cache.KvMap.Load(r.Form["key"][0])
_, err := fmt.Fprintf(w, val.(string))
if err != nil {
panic(err)
}
}
- 首先,解析来自路径的参数:?key=xxx;
随后,查询服务器中的缓存(为了简单起见,这里使用 sync.Map 来模拟缓存):如果缓存不存在,则写入缓存,并通过 time.AfterFunc 设置缓存过期时间(expireTime);
最后,返回缓存。
② 缓存代理服务器准备
有了缓存服务器之后,我们还需要一个代理服务器来选择具体选择哪个缓存服务器来请求;
代码如下:
proxy/proxy.go
package proxy
import (
"fmt"
"github.com/jasonkayzk/consistent-hashing-demo/core"
"io/ioutil"
"net/http"
"time"
)
type Proxy struct {
consistent *core.Consistent
}
// NewProxy creates a new Proxy
func NewProxy(consistent *core.Consistent) *Proxy {
proxy := &Proxy{
consistent: consistent,
}
return proxy
}
func (p *Proxy) GetKey(key string) (string, error) {
host, err := p.consistent.GetKey(key)
if err != nil {
return "", err
}
resp, err := http.Get(fmt.Sprintf("http://%s?key=%s", host, key))
if err != nil {
return "", err
}
defer resp.Body.Close()
body, _ := ioutil.ReadAll(resp.Body)
fmt.Printf("Response from host %s: %s\n", host, string(body))
return string(body), nil
}
func (p *Proxy) RegisterHost(host string) error {
err := p.consistent.RegisterHost(host)
if err != nil {
return err
}
fmt.Println(fmt.Sprintf("register host: %s success", host))
return nil
}
func (p *Proxy) UnregisterHost(host string) error {
err := p.consistent.UnregisterHost(host)
if err != nil {
return err
}
fmt.Println(fmt.Sprintf("unregister host: %s success", host))
return nil
}
代理服务器的逻辑很简单,就是创建一个一致性 Hash 结构:Consistent,把 Consistent 和请求缓存服务器的逻辑进行了一层封装。
算法验证
启动代理服务器
启动代理服务器的代码如下:
package main
import (
"fmt"
"github.com/jasonkayzk/consistent-hashing-demo/core"
"github.com/jasonkayzk/consistent-hashing-demo/proxy"
"net/http"
)
var (
port = "18888"
p = proxy.NewProxy(core.NewConsistent(10, nil))
)
func main() {
stopChan := make(chan interface{})
startServer(port)
<-stopChan
}
func startServer(port string) {
http.HandleFunc("/register", registerHost)
http.HandleFunc("/unregister", unregisterHost)
http.HandleFunc("/key", getKey)
fmt.Printf("start proxy server: %s\n", port)
err := http.ListenAndServe(":"+port, nil)
if err != nil {
panic(err)
}
}
func registerHost(w http.ResponseWriter, r *http.Request) {
_ = r.ParseForm()
err := p.RegisterHost(r.Form["host"][0])
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
_, _ = fmt.Fprintf(w, err.Error())
return
}
_, _ = fmt.Fprintf(w, fmt.Sprintf("register host: %s success", r.Form["host"][0]))
}
func unregisterHost(w http.ResponseWriter, r *http.Request) {
_ = r.ParseForm()
err := p.UnregisterHost(r.Form["host"][0])
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
_, _ = fmt.Fprintf(w, err.Error())
return
}
_, _ = fmt.Fprintf(w, fmt.Sprintf("unregister host: %s success", r.Form["host"][0]))
}
func getKey(w http.ResponseWriter, r *http.Request) {
_ = r.ParseForm()
val, err := p.GetKey(r.Form["key"][0])
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
_, _ = fmt.Fprintf(w, err.Error())
return
}
_, _ = fmt.Fprintf(w, fmt.Sprintf("key: %s, val: %s", r.Form["key"][0], val))
}
和缓存服务器类似,这里采用 HTTP 服务器来模拟,
代理服务器监听 18888 端口的几个路由:
- /register:注册缓存服务器;
- /unregister:注销缓存服务器;
- /key:查询缓存 Key;
这里为了简单起见,使用了这种方式进行服务注册,实际使用时请使用其他组件进行实现!
接下来启动缓存服务器:
start proxy server: 18888
启动缓存服务器
分别启动三个缓存服务器:
$ go run server/main.go -p 8080
start server: 8080
$ go run server/main.go -p 8081
start server: 8081
$ go run server/main.go -p 8082
start server: 8082
同时,代理服务器输出:
register host: localhost:8080 success
register host: localhost:8081 success
register host: localhost:8082 success
可以看到缓存服务器已经成功注册。
请求代理服务器获取 Key
可以使用 curl 命令请求代理服务器获取缓存 key:
$ curl localhost:18888/key?key=123
key: 123, val: hello: 123
此时,代理服务器输出:
Response from host localhost:8080: hello: 123
同时,8000 端口的缓存服务器输出:
cached key: {123: hello: 123}
removed cached key after 10s: {123: hello: 123}
可以看到,8000 端口的服务器对 key 值进行了缓存,并在 10 秒后清除了缓存。
尝试多次获取 Key
尝试获取多个 Key:
Response from host localhost:8082: hello: 45363456
Response from host localhost:8080: hello: 4
Response from host localhost:8082: hello: 1
Response from host localhost:8080: hello: 2
Response from host localhost:8082: hello: 3
Response from host localhost:8080: hello: 4
Response from host localhost:8082: hello: 5
Response from host localhost:8080: hello: 6
Response from host localhost:8082: hello: sdkbnfoerwtnbre
Response from host localhost:8082: hello: sd45555254tg423i5gvj4v5
Response from host localhost:8081: hello: 0
Response from host localhost:8082: hello: 032452345
可以看到不同的 key 被散列到了不同的缓存服务器,
接下来我们通过 debug 查看具体的变量来一探究竟。
通过 Debug 查看注册和 Hash 环
开启 debug,并注册单个缓存服务器后,查看 Consistent 中的值:
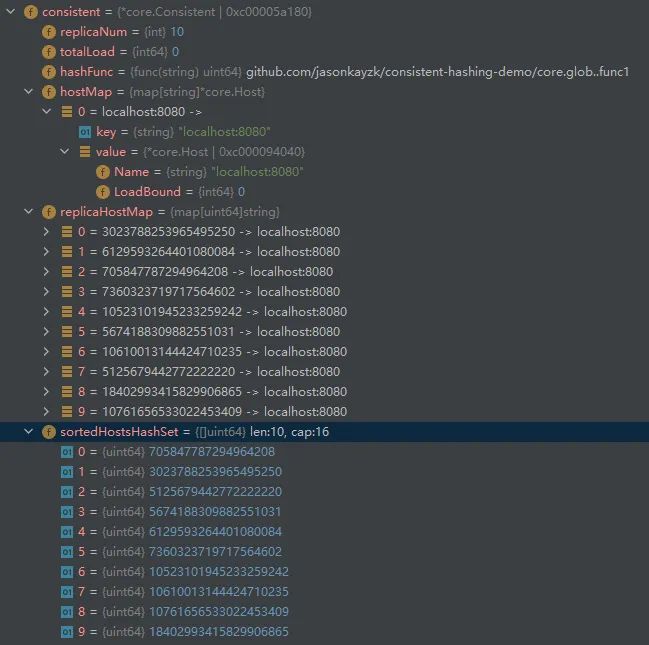
注册三个缓存服务器后,查看 Consistent 中的值:
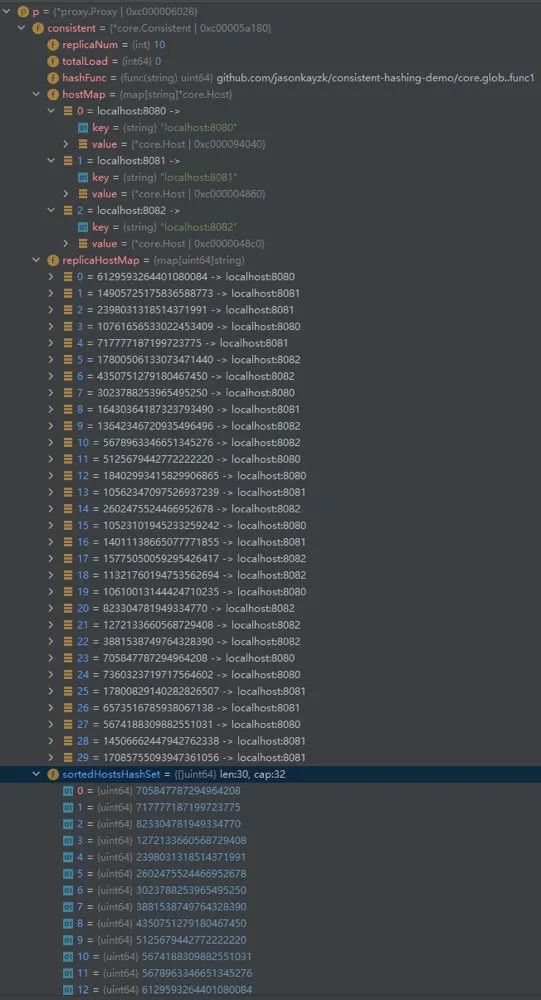
从 debug 中的变量,我们就可以很清楚的看到注册不同数量的服务器时,一致性 Hash 上服务器的动态变化!
以上就是基本的一致性 Hash 算法的实现了!
但是很多时候,我们的缓存服务器需要同时处理大量的缓存请求,而通过上面的算法,我们总是会去同一台缓存服务器去获取缓存数据。
如果很多的热点数据都落在了同一台缓存服务器上,则可能会出现性能瓶颈。
Google 在 2017 年提出了:含有负载边界值的一致性 Hash 算法,下面我们在基本的一致性 Hash 算法的基础上,实现含有负载边界值的一致性 Hash!
含有负载边界值的一致性 Hash
算法描述
17 年时,Google 提出了含有负载边界值的一致性 Hash 算法,此算法主要应用于在实现一致性的同时,实现负载的平均性,此算法最初由 Vimeo 的 Andrew Rodland 在 haproxy 中实现并开源。
参考:https://ai.googleblog.com/2017/04/consistent-hashing-with-bounded-loads.html
arvix 论文地址:https://arxiv.org/abs/1608.01350
这个算法将缓存服务器视为一个含有一定容量的桶(可以简单理解为 Hash 桶),将客户端视为球,则平均性目标表示为:所有约等于平均密度(球的数量除以桶的数量)。
实际使用时,可以设定一个平均密度的参数 ε,将每个桶的容量设置为平均加载时间的 下上限 (1+ε)。
具体的计算过程如下:
- 首先,计算 key 的 Hash 值;
- 随后,沿着 Hash 环顺时针寻找第一台满足条件(平均容量限制)的服务器;
- 获取缓存;
例如下面的图:

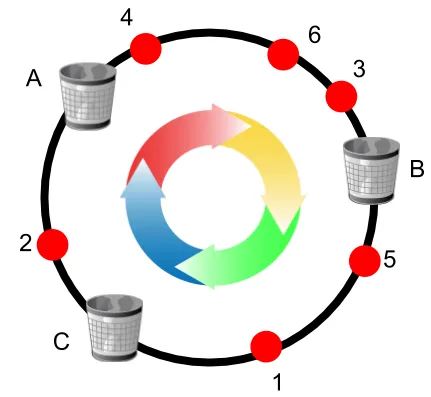
使用哈希函数将 6 个球和 3 个桶分配给 Hash 环 上的随机位置,假设每个桶的容量设置为 2,按 ID 值的递增顺序分配球:
- 1 号球顺时针移动,进入 C 桶;
- 2 号球进入 A 桶;
- 3 号和 4 号球进入 B 桶;
- 5 号球进入 C 桶;
- 然后 6 号球顺时针移动,首先击中 B 桶;但是桶 B 的容量为 2,并且已经包含球 3 和 4,所以球 6 继续移动到达桶 C,但该桶也已满;
- 最后,球 6 最终进入具有备用插槽的桶 A;
算法实现
在上面基本一致性 Hash 算法实现的基础上,我们继续实现含有负载边界值的一致性 Hash 算法,在核心算法中添加根据负载情况查询 Key 的函数,以及增加/释放负载值的函数。
根据负载情况查询 Key 的函数:
core/algorithm.go
func (c *Consistent) GetKeyLeast(key string) (string, error) {
c.RLock()
defer c.RUnlock()
if len(c.replicaHostMap) == 0 {
return "", ErrHostNotFound
}
hashedKey := c.hashFunc(key)
idx := c.searchKey(hashedKey) // Find the first host that may serve the key
i := idx
for {
host := c.replicaHostMap[c.sortedHostsHashSet[i]]
loadChecked, err := c.checkLoadCapacity(host)
if err != nil {
return "", err
}
if loadChecked {
return host, nil
}
i++
// if idx goes to the end of the ring, start from the beginning
if i >= len(c.replicaHostMap) {
i = 0
}
}
}
func (c *Consistent) checkLoadCapacity(host string) (bool, error) {
// a safety check if someone performed c.Done more than needed
if c.totalLoad < 0 {
c.totalLoad = 0
}
var avgLoadPerNode float64
avgLoadPerNode = float64((c.totalLoad + 1) / int64(len(c.hostMap)))
if avgLoadPerNode == 0 {
avgLoadPerNode = 1
}
avgLoadPerNode = math.Ceil(avgLoadPerNode * (1 + loadBoundFactor))
candidateHost, ok := c.hostMap[host]
if !ok {
return false, ErrHostNotFound
}
if float64(candidateHost.LoadBound)+1 <= avgLoadPerNode {
return true, nil
}
return false, nil
}
在 GetKeyLeast 函数中,首先根据 searchKey 函数,顺时针获取可能满足条件的第一个虚拟节点,
随后调用 checkLoadCapacity 校验当前缓存服务器的负载数是否满足条件:
candidateHost.LoadBound+1 <= (c.totalLoad + 1) / len(hosts) * (1 + loadBoundFactor)
如果不满足条件,则沿着 Hash 环走到下一个虚拟节点,继续判断是否满足条件,直到满足条件。
这里使用的是无条件的 for 循环,因为一定存在低于 平均负载*(1 + loadBoundFactor) 的虚拟节点!
增加/释放负载值的函数:
core/algorithm.go
func (c *Consistent) Inc(hostName string) {
c.Lock()
defer c.Unlock()
atomic.AddInt64(&c.hostMap[hostName].LoadBound, 1)
atomic.AddInt64(&c.totalLoad, 1)
}
func (c *Consistent) Done(host string) {
c.Lock()
defer c.Unlock()
if _, ok := c.hostMap[host]; !ok {
return
}
atomic.AddInt64(&c.hostMap[host].LoadBound, -1)
atomic.AddInt64(&c.totalLoad, -1)
}
逻辑比较简单,就是原子的对对应缓存服务器进行负载加减一操作。
算法测试
修改代理服务器代码
在代理服务器中增加路由:
proxy/proxy.go
func (p *Proxy) GetKeyLeast(key string) (string, error) {
host, err := p.consistent.GetKeyLeast(key)
if err != nil {
return "", err
}
p.consistent.Inc(host)
time.AfterFunc(time.Second*10, func() { // drop the host after 10 seconds(for testing)!
fmt.Printf("dropping host: %s after 10 second\n", host)
p.consistent.Done(host)
})
resp, err := http.Get(fmt.Sprintf("http://%s?key=%s", host, key))
if err != nil {
return "", err
}
defer resp.Body.Close()
body, _ := ioutil.ReadAll(resp.Body)
fmt.Printf("Response from host %s: %s\n", host, string(body))
return string(body), nil
}
注意:这里模拟的是单个 key 请求可能会持续 10s 钟。
启动代理服务器时增加路由:
main.go
func startServer(port string) {
// ......
http.HandleFunc("/key_least", getKeyLeast)
// ......
}
func getKeyLeast(w http.ResponseWriter, r *http.Request) {
_ = r.ParseForm()
val, err := p.GetKeyLeast(r.Form["key"][0])
if err != nil {
w.WriteHeader(http.StatusInternalServerError)
_, _ = fmt.Fprintf(w, err.Error())
return
}
_, _ = fmt.Fprintf(w, fmt.Sprintf("key: %s, val: %s", r.Form["key"][0], val))
}
测试
启动代理服务器,并开启三台缓存服务器,通过下面的命令获取含有负载边界的 Key:
$ curl localhost:18888/key_least?key=123
key: 123, val: hello: 123
多次请求后的结果如下:
```
start proxy server: 18888
register host: localhost:8080 success
register host: localhost:8081 success
register host: localhost:8082 success
Response from host localhost:8080: hello: 123
Response from host localhost:8080: hello: 123
Response from host localhost:8082: hello: 123
Response from host localhost:8082: hello: 123
Response from host localhost:8081: hello: 123
Response from host localhost:8080: hello: 123
Response from host localhost:8082: hello: 123
Response from host localhost:8081: hello: 123
Response from host localhost:8080: hello: 123
Response from host localhost:8082: hello: 123
Response from host localhost:8081: hello: 123
Response from host localhost:8080: hello: 123
Response from host localhost:8082: hello: 123
Response from host localhost:8081: hello: 123
Response from host localhost:8080: hello: 123
Response from host localhost:8080: hello: 123
Response from host localhost:8082: hello: 123
Response from host localhost:8080: hello: 123
Response from host localhost:8082: hello: 123
Response from host localhost:8082: hello: 123
```
可以看到,缓存被均摊到了其他服务器(这是由于一个缓存请求会持续 10s 导致的)!
总结
本文抛砖引玉的讲解了一致性 Hash 算法的原理,并提供了 Go 的实现,在此基础之上,根据 Google 的论文实现了带有负载边界的一致性 Hash 算法。
当然上面的代码在实际生产环境下仍然需要部分改进,如:
- 服务注册;
- 缓存服务器实现;
- 心跳检测;
- ……
大家在实际使用时,可以根据需要,搭配实际的组件!
附录
源代码:https://github.com/JasonkayZK/consistent-hashing-demo