如果你想周期性的做一些事情,那么必然,会与时间产生联系。比如,每天早晨7点吃早餐,每天晚上10点进入梦乡。当然,如果你有伴侣的话,晚上这个时间可能不会这么固定。
计算机对时间的控制比人的感觉更加准确一些,但我们依然难以做到绝对精确的调度,这涉及到了终极的哲学问题。了解问题产生的原因,比问题本身的现象更加有难度,下面我们就来聊一下这个问题。
假设,我有一个任务,要求每60秒执行一次,你要如何设计?
很多Javaer会自然的想到Timer和ScheduledExecutorService,不过,这也只能说明你了解一些API而已,在绝对精度的调度面前,它们都不能满足需求。
一个例子
下面这段代码,将开启一个5秒间隔的执行器,然后记录实际的间隔时间和期望的偏移量。
public class Main {
private static ScheduledExecutorService schedule = Executors.newScheduledThreadPool(1);
private static LinkedBlockingDeque<Long> q = new LinkedBlockingDeque<>();
public static void main(String[] args) {
final long rateNano = TimeUnit.SECONDS.toNanos(5);
final Random r = new Random();
final AtomicLong offset = new AtomicLong(0);
final AtomicLong max = new AtomicLong(0);
schedule.scheduleAtFixedRate(()->{
try {
long eventTime = System.nanoTime();
long nanoOffset = q.size() == 0 ? rateNano : (eventTime - q.pollLast());
offset.addAndGet(nanoOffset);
offset.addAndGet(-rateNano);
max.set(Math.max(max.get(), Math.abs(offset.get())));
System.out.println(TimeUnit.NANOSECONDS.toSeconds(eventTime)+ "(s) #"
+ nanoOffset + "(us),"
+ offset.get() + "(us),"
+ max.get() + "(us)"
);
q.offer(eventTime);
Thread.sleep(r.nextInt(500));
} catch (InterruptedException e) {
e.printStackTrace();
}
}, 0, rateNano, TimeUnit.NANOSECONDS);
}
}
我们把时间细分一下,然后打印每个间隔之间的秒数和纳秒数,你将发现一些不同寻常的东西。
978048(s) #4996295958(us),-688459(us),57185541(us)
978053(s) #5002982917(us),2294458(us),57185541(us)
978058(s) #5000489208(us),2783666(us),57185541(us)
978063(s) #4997937167(us),720833(us),57185541(us)
978068(s) #5002287042(us),3007875(us),57185541(us)
978073(s) #4999411375(us),2419250(us),57185541(us)
可以看到,秒数是以5秒5秒的速度增长,但实际的执行时间,如果放大到纳秒,它表现出很没有规律的分布。
为了得到较为可信的数据,实际上,我把这个任务跑了1天,到最后,整个偏移量最大达了57ms。
先不谈Java线程的调度,在操作系统上有误差。就拿操作系统本身来说,由于有虚拟内存、线程池、各种驱动的存在,我们常用的Windows和Linux,都不是实时操作系统。
其主要等待方法,就是在DelayedWorkQueue的take方法里,使用了ConditionObject的awaitNanos方法。
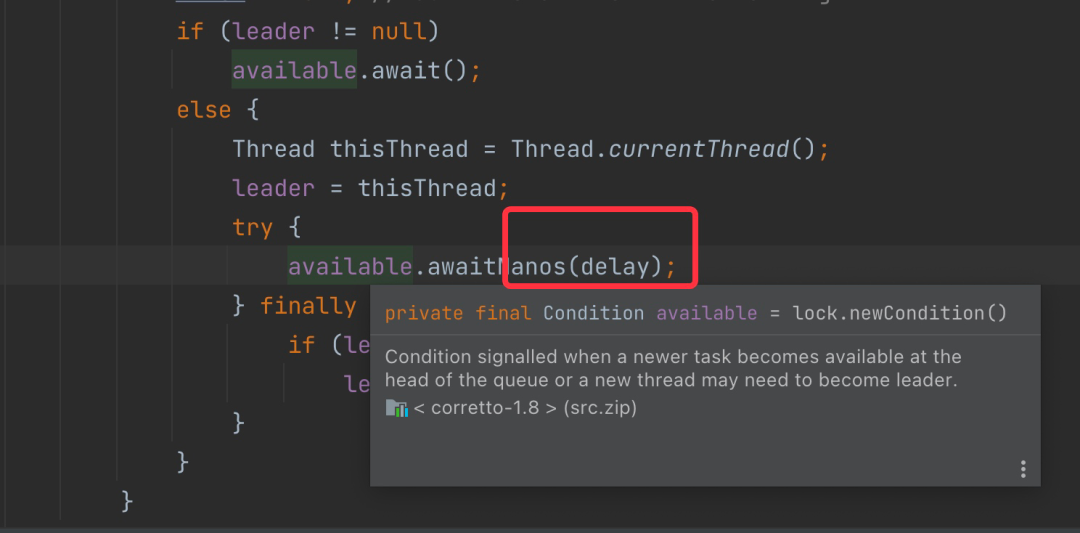
再往下找的话,那就是LockSupport的parkNanos方法。继续向下跟,那就是unsafe,本质上是一个native函数。
public native void park(boolean isAbsolute, long time);
第一个参数是是否是绝对时间,第二个参数是等待时间值。如果isAbsolute是true则会实现毫秒定时。如果isAbsolute是false则会实现纳秒定时。纳秒,可以说是精度很高了。
在jdk源码中,我们找到了具体的native函数。就拿linux来说,文件就躺在./os/posix/os_posix.cpp,最终就是调用pthread_cond_timedwait。
所有的编程都是面向glibc编程,没跑了。
pthread_cond_timedwait
一般来说,平台会提供sleep、pthread_cond_wait、pthread_cond_timedwait等函数供用户使用,实现线程的等待和唤醒。
其中pthread_cond_timedwait就是使用最广泛的那一枚。通过使用perf记录堆栈调用,我们可以看到大体的函数调用栈。
javac Main
java Main
ps -ef| grep java
perf record -g -a -p 2019961
perf report
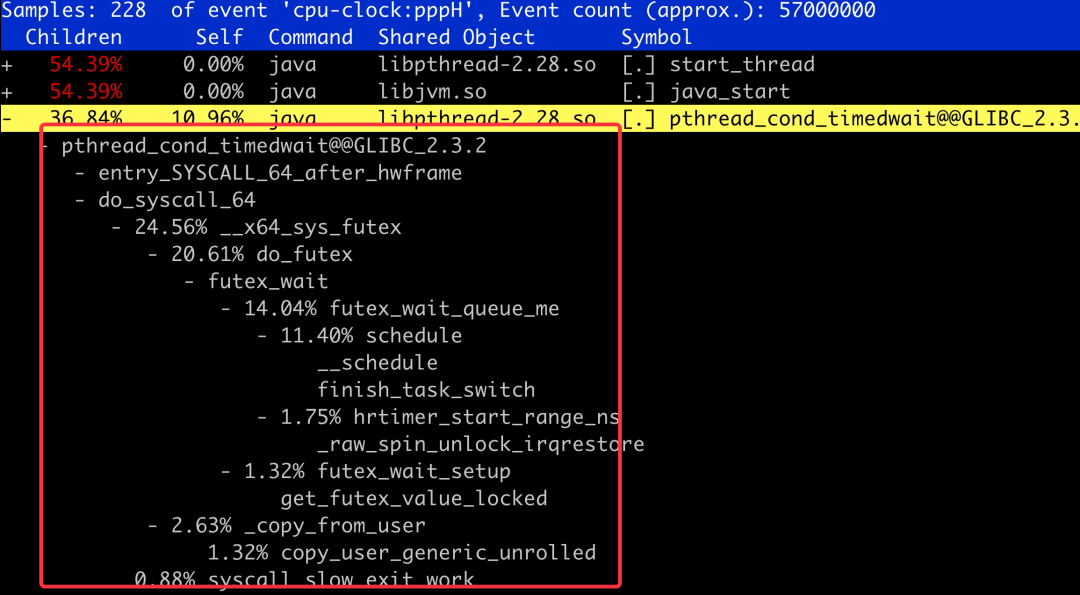
对于了解Linux内部运行原理的同学来说,通过上面的函数调用,就可以看出这里主要是使用了Linux的futex机制,而futex的两个主要方法就是futex_wait和futex_wake。
我们先不管这些乱七八糟的同步术语和函数的版本差异,在kernel/futex/waitwake.c (Linux-5.16.12)中,我们能够看到相关的函数调用。
所谓的等待计数器,就是在下面这段代码中设置的。
struct hrtimer_sleeper *
futex_setup_timer(ktime_t *time, struct hrtimer_sleeper *timeout,
int flags, u64 range_ns)
{
if (!time)
return NULL;
hrtimer_init_sleeper_on_stack(timeout, (flags & FLAGS_CLOCKRT) ?
CLOCK_REALTIME : CLOCK_MONOTONIC,
HRTIMER_MODE_ABS);
/*
* If range_ns is 0, calling hrtimer_set_expires_range_ns() is
* effectively the same as calling hrtimer_set_expires().
*/
hrtimer_set_expires_range_ns(&timeout->timer, *time, range_ns);
return timeout;
}
时间轮
所以问题终于聚焦到我们本文的主题上了。
hrtimers,是Linux下一个高分辨率的定时器。hrtimer结构(也就是上面代码的&timeout->timer),其中有一个function参数,会接受一个回调函数,在定时器触发时,将会被调用。
在聊高分辨率的定时器之前,得首先聊一下低分辨率的定时器。在早期的Linux版本中,定时器是基于CPU的HZ来实现的,也就是tick周期。
很明显的,这个tick的周期的最小值,就是1/CPU主频。不过现在的CPU主频都是GHz来算了,所以精度相对来说还不错,能达到纳秒级别。
1GHz=1000MHz,1MHz=1000kHz,1kHz=1000Hz
一个jiffy = 1/HZ
低分辨率的定时器,还有一个非常著名的时间轮算法,将定时任务散列在长度有限的环形数组中。然后,在此基础上再参考日常生活中水表的方式,通过低刻度走得快的轮子带动高一级刻度轮子走动的方法,像齿轮一样带动更高级别的齿轮,这样就可以避免轮子过大的问题。
其实这个也很好理解。假如我们把1天的时间,每一秒都刻在钟表上,需要86400个刻度。但其实,我们的钟表只需要60个刻度就能完成一天的循环。
Linux的定时器,将时间轮分为了9层,可以说精度很高了。
#define WHEEL_SIZE (LVL_SIZE * LVL_DEPTH)
/* Level depth */
#if HZ > 100
# define LVL_DEPTH 9
# else
# define LVL_DEPTH 8
#endif
这些细节很多,我们抽另外的文章讲解,别忘了关注xjjdog。
hrtimer
相比较低精度(也不算低了)的时间轮设计,hrtimer又做了哪些,才称之为高精度呢?
组织hrtimer的,其实是一棵红黑树(timerqueue_node),这是在比较了hash、跳表、堆等数据结构基础上的最终选择。高精度的代码几乎全是重写的,大多数能够实现O(1)时间复杂度的操作。
高精度定时器的主要任务,不是实现时间片上的精度,而是在执行增删改查的时候,能够提供稳定、快速的功能。即使是排序,也应该尽量的减少时间耗费,因为调度代码执行时间的不稳定,同样会影响整个调度系统的稳定性。
timerqueue_head结构在红黑树的基础上,增加了一个next字段,用于保存树中最先到期的定时器节点,算是对红黑树小小的改造。这些改造在效率上都是立竿见影的,效果就像B+ Tree对B Tree的改造一样。
从下面这些结构体,可以大体看出红黑树的组织方式。
struct timerqueue_node {
struct rb_node node;
ktime_t expires;
};
struct timerqueue_head {
struct rb_root_cached rb_root;
};
struct rb_root_cached {
struct rb_root rb_root;
struct rb_node *rb_leftmost;
};
struct rb_node {
unsigned long __rb_parent_color;
struct rb_node *rb_right;
struct rb_node *rb_left;
} __attribute__((aligned(sizeof(long))));
我们再来看一下hrtimer的结构体,发现里面有一个_softexpires,同时,它的成员变量node里,也有一个叫做expires的变量。
struct hrtimer {
struct timerqueue_node node;
ktime_t _softexpires;
enum hrtimer_restart (*function)(struct hrtimer *);
struct hrtimer_clock_base *base;
u8 state;
u8 is_rel;
u8 is_soft;
u8 is_hard;
};
这是hrtimer为了增加调度的效率所做的一些妥协。它表示,我们的任务,可以在_softexpires和expires之间的任何时刻到期。expires被称作硬到期时间,是任务到期的最后时间。有了这样的设计,就可以避免进程被hrtimer频繁的唤醒,减少contextswitch。
我们可以从perf得到的hrtimer_set_expires_range_ns函数中窥探到这两个时间点的设定。这本质上也是一种对时间齐功能。
static inline void hrtimer_set_expires_range_ns(struct hrtimer *timer, ktime_t time, u64 delta)
{
timer->_softexpires = time;
timer->node.expires = ktime_add_safe(time, ns_to_ktime(delta));
}
delta的设定非常有意思,在不同的硬件设备上,它的值都不同,表示最小的调度精度。这也是我们最上面的Java程序,在执行的时候,引起时间抖动的根本原因。
End
聊到这里,我想你应该能够想到,世界上根本就没有准确的调度。只不过随着主频的增加,我们可以将精度控制在一定范围内。
且不说时间本身准不准,仅仅是这时间片的细分,就使得目前的PC机,在微观世界上的时间误差将变的无比巨大,进行高频率的的精度调度几乎是不可能完成的事。
世界上最准的钟表,每150亿年才会减少一秒。但1秒也是时间,我们依然能够用语言表达出来。纠结准实时性是一个永远没有尽头的答案,除非我们能够操纵原子。再加上任务调度代码本身耗时的不确定性,目前的调度器维持在纳秒精度,已经算是一个奇迹。
世界本身就是人粗略的观测,何况是人所造出的机器呢。
作者简介:小姐姐味道 (xjjdog),一个不允许程序员走弯路的公众号。聚焦基础架构和Linux。十年架构,日百亿流量,与你探讨高并发世界,给你不一样的味道。我的个人微信xjjdog0,欢迎添加好友,进一步交流。