本文转自雷锋网,如需转载请至雷锋网官网申请授权。
反向传播和基于梯度的优化是近年来机器学习(ML)取得重大突破的核心技术。
人们普遍认为,机器学习之所以能够快速发展,是因为研究者们使用了第三方框架(如PyTorch、TensorFlow)来解析ML代码。这些框架不仅具有自动微分(AD)功能,还为本地代码提供了基础的计算功能。而ML所依赖的这些软件框架都是围绕 AD 的反向模式所构建的。这主要是因为在ML中,当输入的梯度为海量时,可以通过反向模式的单次评估进行精确有效的评估。
自动微分算法分为正向模式和反向模式。但正向模式的特点是只需要对一个函数进行一次正向评估(即没有用到任何反向传播),计算成本明显降低。为此,来自剑桥与微软等机构的研究者们探索这种模式,展示了仅使用正向自动微分也能在一系列机器学习框架上实现稳定的梯度下降。

论文地址:https://arxiv.org/pdf/2202.08587v1.pdf他们认为,正向梯度有利于改变经典机器学习训练管道的计算复杂性,减少训练的时间和精力成本,影响机器学习的硬件设计,甚至对大脑中反向传播的生物学合理性产生影响。
1 自动微分的两种模式
首先,我们来简要回顾一下自动微分的两种基本模式。
正向模式
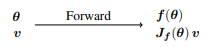
给定一个函数 f: θ∈R n,v∈R n,正向模式的AD会计算 f(θ) 和雅可比向量乘积Jf (θ) v,其中Jf (θ) ∈R m×n是f在θ处评估的所有偏导数的雅可比矩阵,v是扰动向量。对于 f : R n → R 的情况,在雅可比向量乘积对应的方向导数用 ∇f(θ)- v表示,即在θ处的梯度∇f对方向向量v的映射,代表沿着该方向的变化率。值得注意的是,正向模式在一次正向运行中同时评估了函数 f 及其雅可比向量乘积 Jf v。此外,获得 Jf v 不需要计算雅可比向量Jf,这一特点被称为无矩阵计算。
反向模式
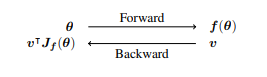
给定一个函数 f : R n → R m,数值 θ∈R n,v∈R m,AD反向模式会计算f(θ)和雅可比向量乘积v |Jf (θ),其中Jf∈R m×n是f在θ处求值的所有偏导数的雅可比矩阵,v∈R m是一个邻接的矢量。对于f : R n → R和v = 1的情况,反向模式计算梯度,即f对所有n个输入的偏导数∇f(θ)=h ∂f ∂θ1,. . . , ∂f ∂θn i| 。请注意,v |Jf 是在一次前向-后向评估中进行计算的,而不需要计算雅可比Jf 。
运行时间成本
两种AD模式的运行时间以运行正在微分的函数 f 所需时间的恒定倍数为界。反向模式的成本比正向模式高,因为它涉及到数据流的反转,而且需要保留正向过程中所有操作结果的记录,因为在接下来的反向过程中需要这些记录来评估导数。内存和计算成本特征最终取决于AD系统实现的功能,如利用稀疏性。成本可以通过假设基本操作的计算复杂性来分析,如存储、加法、乘法和非线性操作。将评估原始函数 f 所需的时间表示设为 runtime(f),我们可以将正向和反向模式所需的时间分别表示为 Rf×runtime(f) 和 Rb×runtime(f)。在实践中,Rf 通常在1到3之间,Rb通常在5到10之间,不过这些结果都与程序高度相关。
2 方法
正向梯度
定义1
给定一个函数 f : R n → R,他们将「正向梯度」 g : R n → R n 定义为:
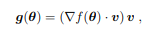
其中,θ∈R n 是评估梯度的关键点,v∈R n 是一个扰动向量,被视为一个多元随机变量v∼p(v),这样 v 的标量分量 vi 是独立的,对所有 i 都有零均值和单位方差,∇f(θ)-v∈R 是 f 在在 v 方向上 θ 点的方向导数。
简要地谈一下这个定义的由来。
如前所述,正向模式直接给我们提供了方向导数∇f(θ) - v = P i ∂f ∂θi vi,无需计算∇f。将 f 正向评估 n 次,方向向量取为标准基(独热码)向量ei∈R n,i=1 ... n,其中ei表示在第i个坐标上为1、其他地方为0的向量,这时,只用正向模式就可以计算∇f。
这样就可以分别评估f对每个输入∂f ∂θi的敏感性,把所有结果合并后就可以得到梯度∇f。为了获得比反向传播更优的运行时间优势,我们需要在每个优化迭代中运行一次正向模式。在一次正向运行中,我们可以将方向v理解为敏感度加权和中的权重向量,即P i ∂f ∂θi vi,尽管这没办法区分每个θi在最终总数中的贡献。因此,我们使用权重向量v将总体敏感度归因于每个单独的参数θi,与每个参数θi的权重vi成正比(例如,权重小的参数在总敏感度中的贡献小,权重大的参数贡献大)。
总之,每次评估正向梯度时,我们只需做以下工作:
- 对一个随机扰动向量v∼p(v)进行采样,其大小与f的第一个参数相同。
- 通过AD正向模式运行f函数,在一次正向运行中同时评估f(θ)和∇f(θ)-v,在此过程中无需计算∇f。得到的方向导数(∇f(θ)-v)是一个标量,并且由AD精确计算(不是近似值)。
- 将标量方向导数∇f(θ)-v与矢量v相乘,得到g(θ),即正向梯度。
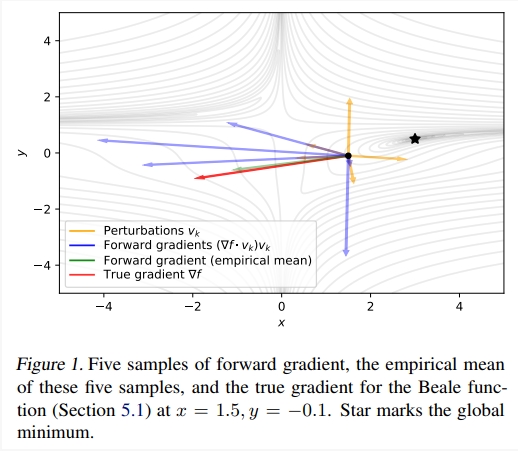
图 1 显示了 Beale函数的几个正向梯度的评估结果。我们可以看到扰动vk(橙色)如何在k∈[1,5]的情况下转化为正向梯度(∇f-vk)vk(蓝色),在受到指向限制时偶尔也会指向正确的梯度(红色)。绿色箭头表示通过平均正向梯度来评估蒙特卡洛梯度,即1 K PK k=1(∇f - vk)vk≈E[(∇f - v)v]。
正向梯度下降
他们构建了一个正向梯度下降(FGD)算法,用正向梯度g代替标准梯度下降中的梯度∇f(算法1)。
在实践中,他们使用小型随机版本,其中 ft 在每次迭代中都会发生变化,因为它会被训练中使用的每一小批数据影响。研究者注意到,算法 1 中的方向导数dt可以为正负数。如果为负数,正向梯度gt的方向会发生逆转,指向预料中的真实梯度。图1显示的两个vk样本,证明了这种行为。
在本文中,他们将范围限制在FGD上,单纯研究了这一基础算法,并将其与标准反向传播进行比较,不考虑动量或自适应学习率等其他各种干扰因素。笔者认为,正向梯度算法是可以应用到其他基于梯度算法的优化算法系列中的。

3 实验
研究者在PyTorch中执行正向AD来进行实验。他们发现,正向梯度与反向传播这两种方法在内存上没有实际差异(每个实验的差异都小于0.1%)。
逻辑回归
图 3 给出了多叉逻辑回归在MNIST数字分类上的几次运行结果。我们观察到,相比基本运行时间,正向梯度和反向传播的运行时间成本分别为 Rf=2.435 和 Rb=4.389,这与人们对典型AD系统的预期相符。
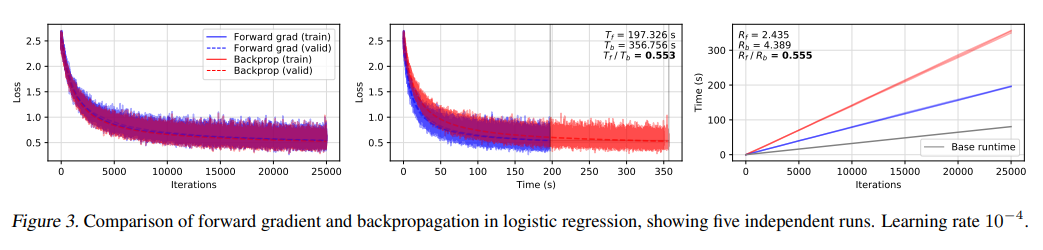
Rf/Rb=0.555和Tf/Tb=0.553的比率表明,在运行时间和损失性能方面,正向梯度大约比反向传播快两倍。
在简单的模型中,这些比率是一致的,因为这两种技术在空间行为的迭代损失上几乎相同,这意味着运行时收益几乎直接反映在每个时间空间的损失上。
多层神经网络
图4显示了用多层神经网络在不同学习率下进行MNIST分类的两个实验。他们使用了三个架构大小分别为1024、1024、10的全连接层。在这个模型架构中,他们观察到正向梯度和反向传播相对于基础运行时间的运行成本为Rf=2.468和Rb=4.165,相对测量 Rf/Rb 平均为0.592,与逻辑回归的情况大致相同。
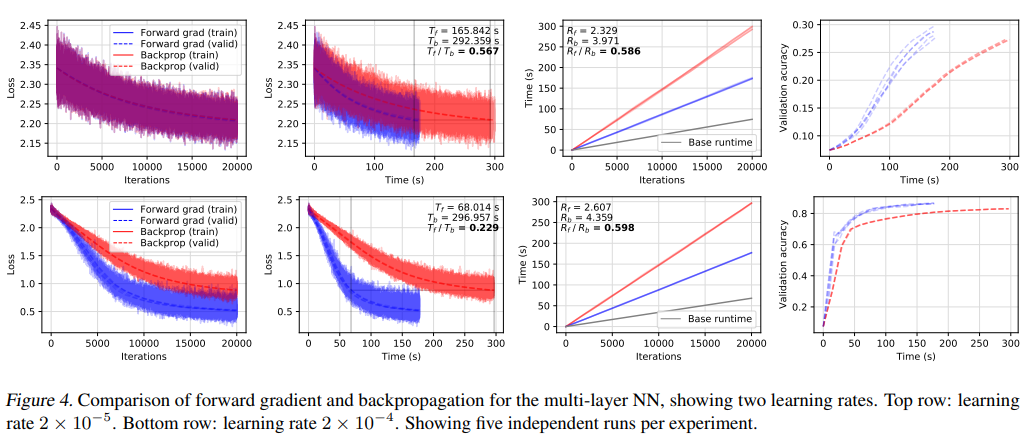
有趣的是,在第二个实验中(学习率为2×10-4),我们可以看到正向梯度在每个迭代损失图中都实现了快速的下降。作者认为,这种行为是由于常规SGD(反向传播)和正向SGD算法的随机性不同所导致的,因此他们推测:正向梯度引入的干扰可能有利于探索损失平面。
我们可以从时间曲线图看到,正向模式减少了运行时间。我们看到,损失性能指标Tf/Tb值为0.211,这表明在验证实验损失的过程中,正向梯度的速度是反向传播的四倍以上。
卷积神经网络
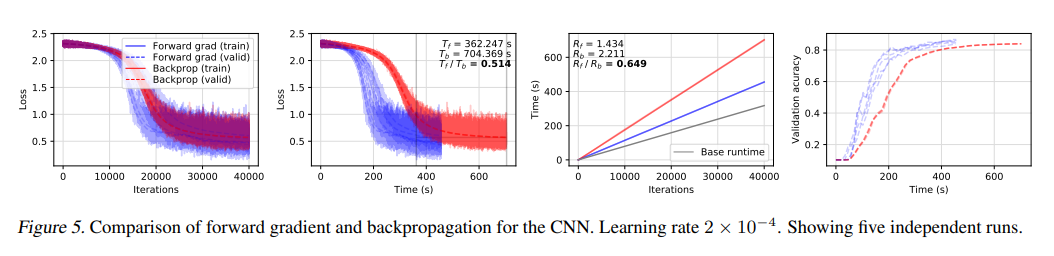
图 5 展示了一个卷积神经网络对同一MNIST分类任务的正向梯度和反向传播的比较。在这个架构中,他们观察到,相对于基本运行时间,正向AD的性能最好,其中正向模式的Rf=1.434,代表了在基本运行时间之上的开销只有 43%。Rb=2.211 的反向传播非常接近反向 AD 系统中所期待的理想情况。Rf/Rb=0.649 代表了正向AD运行时间相对于反向传播的一个显著优势。在损失空间,他们得到一个比率 Tf /Tb=0.514,这表明在验证损失的实验中,正向梯度的速度比反向传播的速度要快两倍。
可扩展性
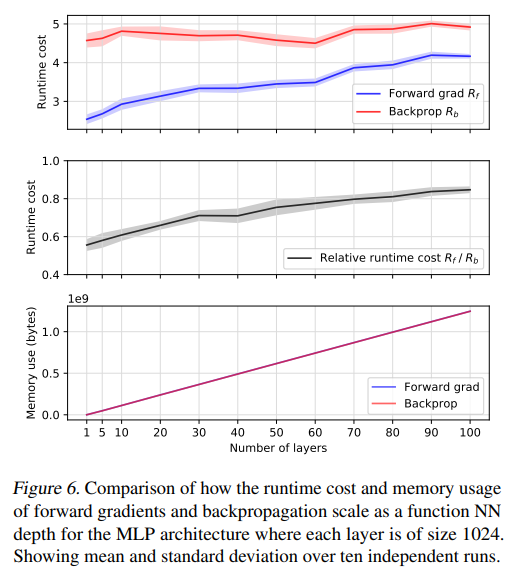
前面的几个结果表明:
- 不用反向传播也可以在一个典型的ML训练管道中进行训练,并且以一种竞争计算的方式来实现;
- 在相同参数(学习率和学习率衰减)的情况下,正向AD比反向传播所消耗的时间要少很多。
相对于基础运行时的成本,我们看到,对于大部分实验,反向传播在Rb∈[4,5]内,正向梯度在Rf∈[3,4]内。我们还观察到,正向梯度算法在整个范围内对运行都是有利的。Rf/Rb比率在10层以内保持在0.6以下,在100层时略高于0.8。重要的是,这两种方法在内存消耗上几乎没有差别。
4 结论
总的来说,这篇工作的几点贡献主要如下:
- 他们将「正向梯度」(forward gradient)定义为:一个无偏差的、基于正向自动微分且毫不涉及到反向传播的梯度估算器。
- 他们在PyTorch中从零开始,实现了正向模式的自动微分系统,且完全不依赖PyTorch中已有的反向传播。
- 他们把正向梯度模式应用在各类随机梯度下降(SGD)优化中,最后的结果充分证明了:一个典型的现代机器学习训练管道可以只使用自动微分正向传播来构建。
- 他们比较了正向梯度和反向传播的运行时间和损失消耗等等,证明了在一些情况下,正向梯度算法的速度比反向传播快两倍。