算力、数据和算法是引导现代机器学习(ML)进步的三个基本因素。
人工智能技术近年来的发展不仅仰仗于大数据和算法,更是算力不断增强的结果。据了解从 2012 年到 2018 年,用于训练大型模型的计算能力已增长了 30 万倍,并且约每三个半月翻一番。
人工神经网络在上世纪 80 年代就被提出,但由于算力的限制经历数年寒冬。不过由于技术的发展,这一限制得到突破,GPU、CPU 和 AI 加速芯片不断被推出。
随着深度学习的出现,算力需求呈现指数级增长。2018 年 Bert 横空出世,谷歌、微软、英伟达等巨头纷纷推出自己的大模型,将其视为下一个 AI 领域的必争的高地,例如谷歌发布首个万亿级模型 Switch Transformer、英伟达与微软联合发布了 5300 亿参数的 MT-NLG……
大模型伴随而来的是大算力,我们不禁会问,深度学习时代以来ML算力需求增加了多少?未来,随着模型的扩展,算力还能跟得上吗?
近日来自阿伯丁大学、MIT 等机构的研究者对 ML 三要素中的算力需求进行了研究。他们发现,在 2010 年之前训练所需的算力增长符合摩尔定律,大约每 20 个月翻一番。自 2010 年代初深度学习问世以来,训练所需的算力快速增长,大约每 6 个月翻一番。2015 年末,随着大规模 ML 模型的出现,训练算力的需求提高了 10 到 100 倍,出现了一种新的趋势。

- 论文地址:https://arxiv.org/pdf/2202.05924.pdf
- GitHub 地址:https://github.com/ML-Progress/Compute-Trends
基于上述发现,研究者将 ML 所需算力历史分为三个阶段:前深度学习时代;深度学习时代;大规模时代。总的来说,该论文详细研究了里程碑式 ML 模型随时间变化的算力需求。
本文贡献如下:
- 收集了 123 个具有里程碑意义的 ML 系统数据集,并对算力进行了注释;
- 初步将算力趋势划分为三个不同的阶段;
- 对算力结果进行检查,讨论了与以前工作的不同之处。
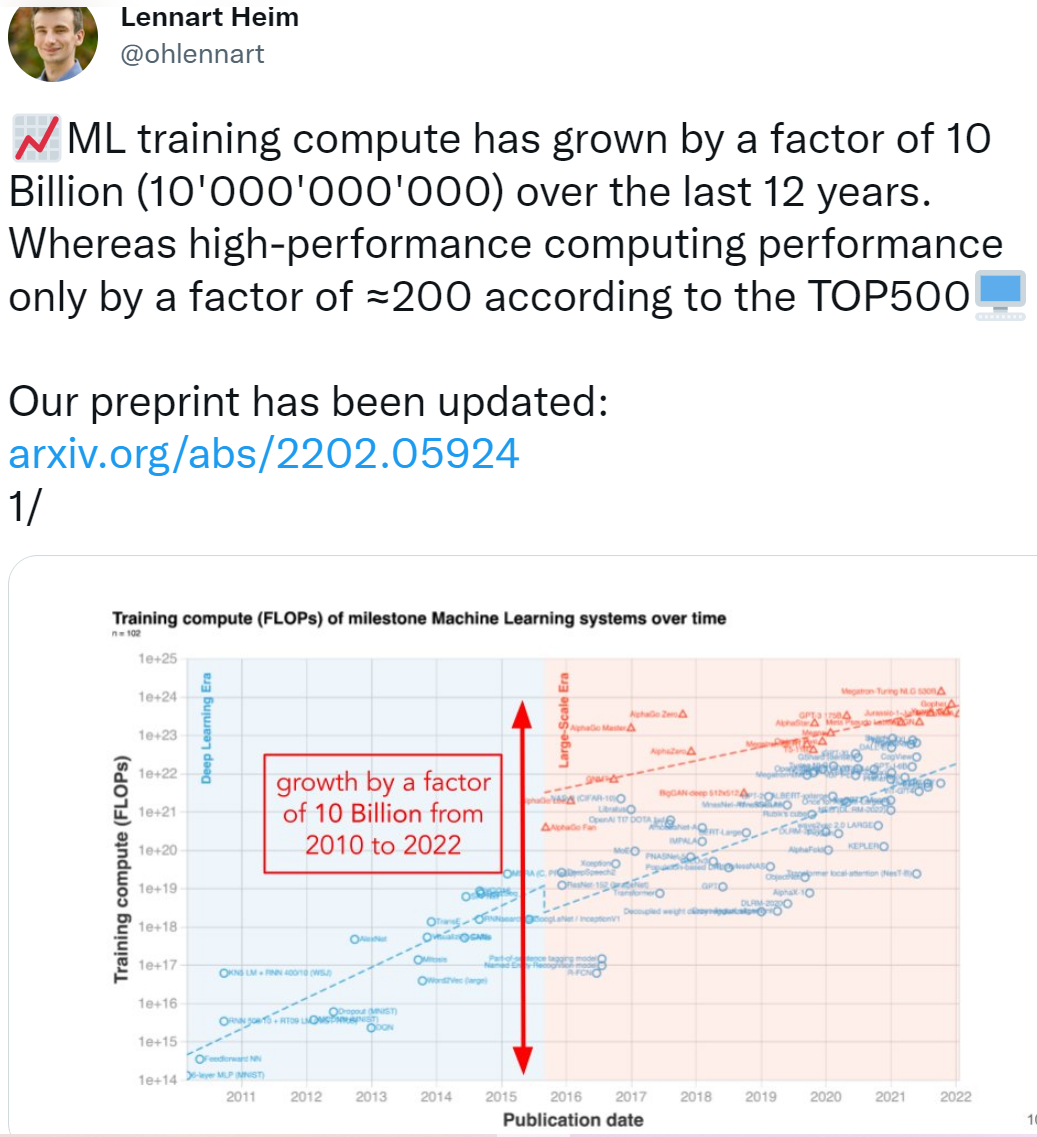
论文作者之一 Lennart Heim 表示:在过去的 12 年里(2010-2022 年),ML 训练算力增长了 100 亿倍。
以往工作
此前就有关于算力的研究,2018 年 Amodei 、Hernandez 介绍了两种评估算力的方法,他们基于 15 个 ML 系统分析了所需算力趋势。他们发现,从 2012 年到 2018 年,ML 训练所需算力 3.4 个月翻一番。
2019 年 Sastry 等人添加了 2012 年以前的 10 篇论文补充了上述分析。他们发现从 1959 年到 2012 年,大约 2 年时间,训练所需算力翻一番。
2021 年 Lyzhov 扩展了 Amodei 和 Hernandez 的数据集,他认为在 2018 年之后算力增长停滞。特别是,作者发现 2020 年计算最密集的模型(GPT-3)只需要比 2017 年计算最密集的模型(AlphaGo Zero)多 1.5 倍的计算量。
下图很好的总结了上述研究:2012-2018 年,大约 3.4 个月算力翻一番(Amodei 、Hernandez 研究);1959-2018 年,大约需要 2 年算力翻一番(Sastry 等人);2018-2020 年,需要超过 2 年算力翻一番(Lyzhov 研究)。

在类似的研究中,2021 年 Sevilla 等人调查了可训练参数数量趋势。他们发现,从 2000 年到 2021 年,所有应用领域的参数倍增时间为 18 到 24 个月。对于语言模型,他们发现在 2016 年到 2018 年之间发生了不连续性,其中参数的倍增时间加快到 4 到 8 个月。
此外,2021 年 Desislavov 等人研究了计算机视觉和自然语言处理系统中所需推理算力。但该研究与之前的工作相比,数据集更加全面,该研究数据集包含的 ML 模型比以前的数据多三倍,并且包含了 2022 年的最新数据。
趋势解读
研究者根据三个不同的时代和三种不同的趋势来解读他们整理的数据。简单来说,在深度学习起飞前,有一个缓慢增长的时代。大约在 2010 年,这一趋势加速并且此后一直没有放缓。另外,2015 至 2016 年大规模模型出现了一个新趋势,即增长速度相似,但超越以往两个数量级(orders of magnitude, OOM)。具体可见下图 1 和表 2。
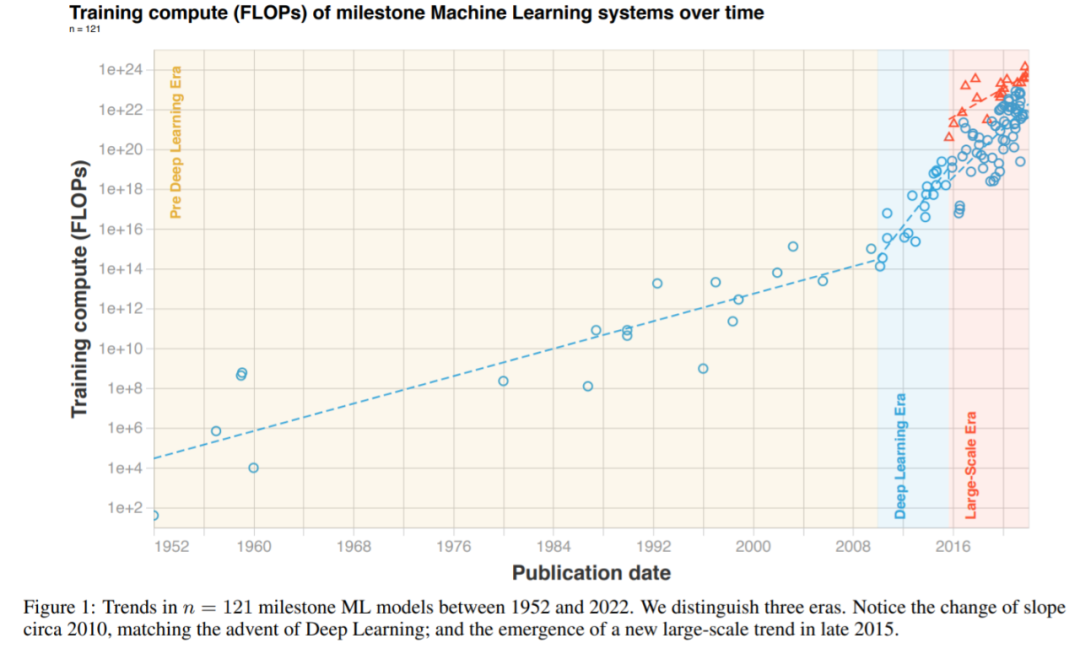
图 1:1952 年以来,里程碑式 ML 系统随时间推移的训练算力(FLOPs)变化。
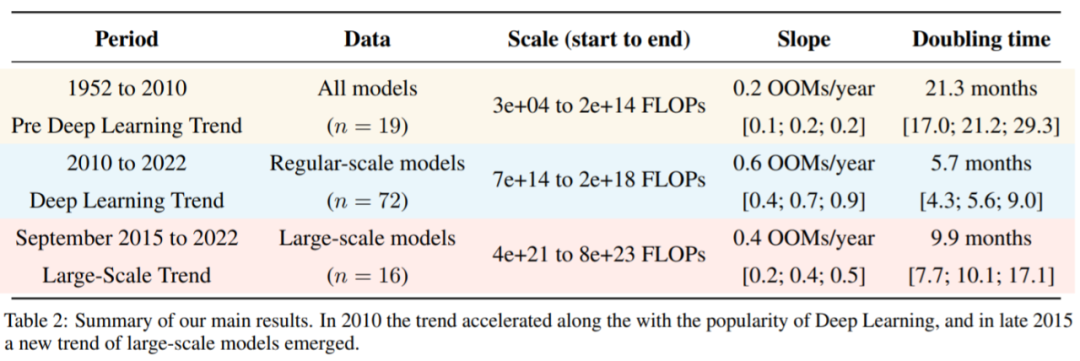
表 2:不同阶段的趋势。
研究者首先讨论了 2010 至 2012 年左右向深度学习的过渡,然后是 2015 至 2016 年左右大规模模型的出现。他们执行了一些替代性分析以从其他角度检查自己的结论。
此外,研究者在附录 B 中讨论了创纪录模式的趋势,在附录 C 中谈论了不同 ML 领域的趋势。
向深度学习的过渡
与 Amodei & Hernandez (2018) 的结果一致,研究者发现深度学习出现前后的两种截然不同的趋势机制。深度学习出现之前,训练 ML 系统需要的算力每 17 至 29 个月翻一番。深度学习出现之后,整体趋势加速,算力每 4 至 9 个月翻一番。深度学习之前的趋势大致符合摩尔定律,根据该定律,集成电路上可以容纳的晶体管数量大约每隔 18 至 24 个月翻一番,通常简化为每两年翻一番。
目前不清楚深度学习时代何时开始的,从前(Pre-)深度学习到深度学习时代的过渡中没有出现明显的间断。
此外,如果将深度学习时代的开始定为 2010 或 2012 年,研究者的结果几乎没有变化,具体如下表 3 所示。
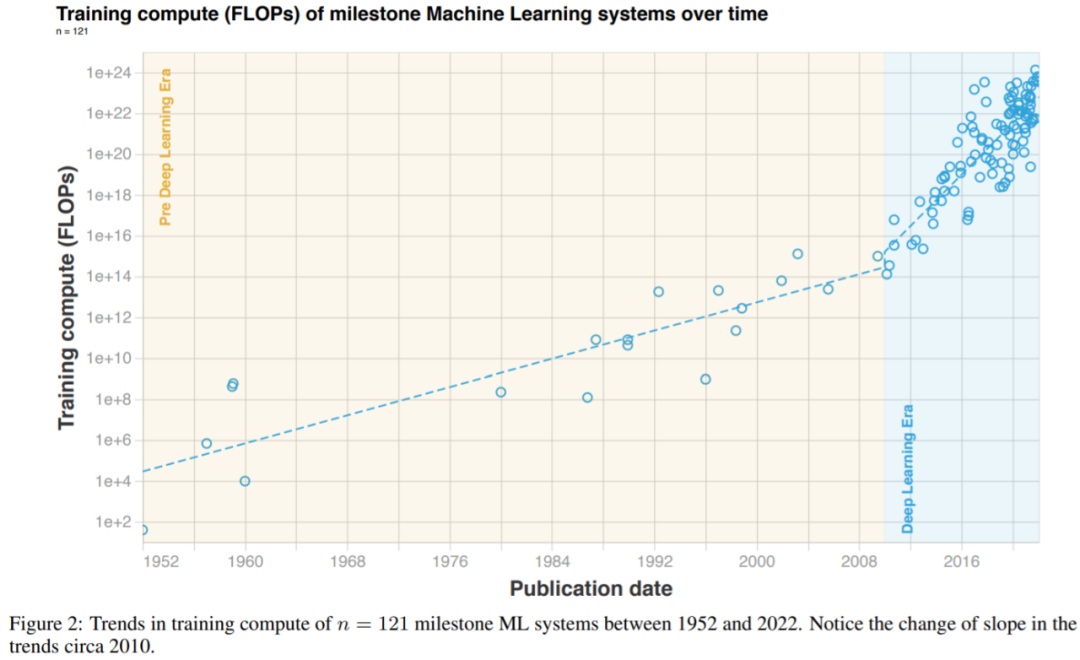
图 2:1952 至 2022 年期间,里程碑式 ML 系统的算力变化趋势。请特别注意 2010 年左右的坡度变化。
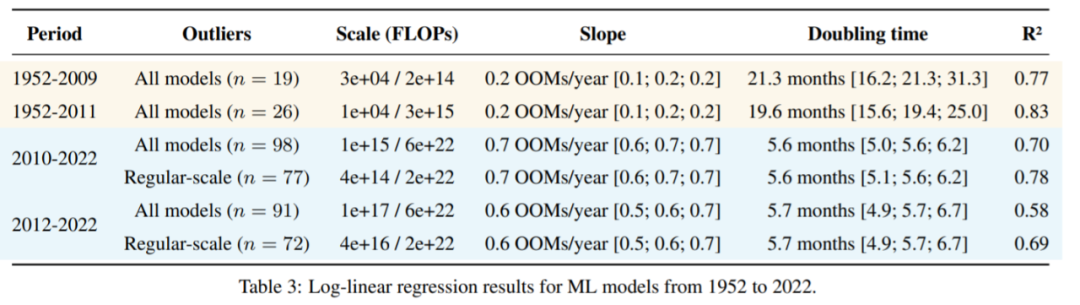
表 3:1952 至 2022 年 ML 模型的对数线性回归结果。
大规模时代的趋势
数据显示,大约 2015 至 2016 年左右,大规模模型出现了一个新趋势,具体可见下图 3。这一趋势始于 2015 年底 AlphaGo 的出现并一直延续至今。期间,这些大规模模型由科技巨擘训练,他们拥有的更多训练预算打破了以往的趋势。
需要注意,研究者在确定哪些系统属于这一新的大规模趋势时做了直观的决定,并证明它们是相对于邻近模型超出了某个 Z-value 阈值的模型,方法细节详见附录 A。附录 F 讨论了大规模模型在哪些方法截然不同。
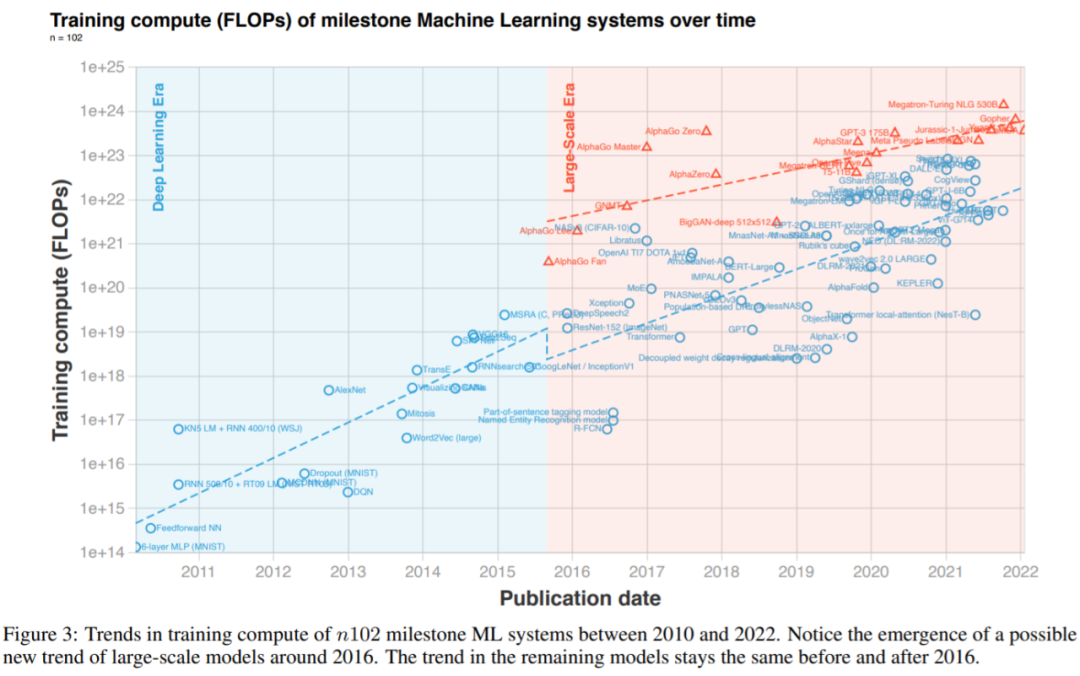
图 3:2010 至 2022 年里程碑式 ML 系统的算力变化趋势。
不过,常规规模模型的趋势依然没有受到影响。2016 年前后趋势是连续的,具有相同的坡度变化,每 5 至 6 个月翻一番。大规模模型算力增加趋势显然更慢,每 9 至 10 个月翻一番。研究者表示,由于关于这些模型的数据有限,所以明显的减速可能是噪声的影响。
研究者的结果与 Amodei & Hernandez (2018) 形成鲜明对比,后者发现 2012 至 2018 年算力翻一番用时更短 ——3.4 个月。结果也与 Lyzhov (2021) 的不同,他们发现 2018 至 2020 年算力翻一番用的时间更长 ——2 年以上。研究者理解了这些不一致的地方,原因在于其他人的分析使用了有限的数据样本并假定单一趋势,自己则是分别研究了大规模和常规规模的模型。
并且,由于大规模趋势仅在近期出现,因而以往的分析无法区分这两类不同的趋势。
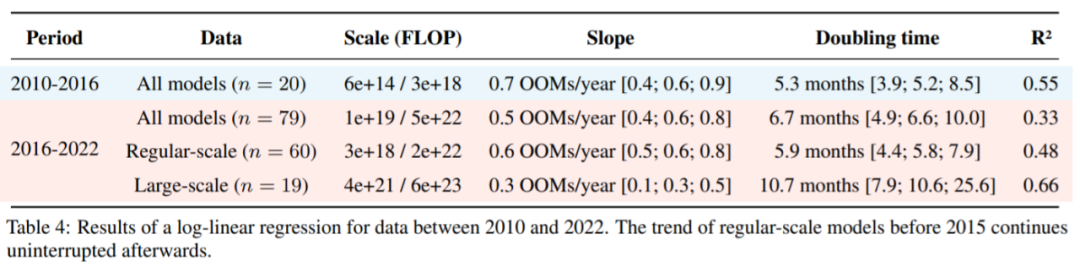
2010 至 2022 年数据的对数线性回归结果。2015 年之前常规规模模型的趋势在之后保持不变。