













一、URL 简介
在阐述地址推送性能的具体优化之前,我们有必要先了解一下与之息息相关的内容—— URL。
1.定义
在不谈及 Dubbo 时,我们大多数人对 URL 这个概念并不会感到陌生。统一资源定位器 (RFC1738――Uniform Resource Locators (URL))应该是最广为人知的一个 RFC 规范,它的定义也非常简单。
因特网上的可用资源可以用简单字符串来表示,该文档就是描述了这种字符串的语法和语义。而这些字符串则被称为:“统一资源定位器”(URL)。
一个标准的 URL 格式至多可以包含如下的几个部分:
protocol://username:password@host:port/path?key=value&key=value
一些典型 URL:
http://www.facebook.com/friends?param1=value1¶m2=value2
https://username:password@10.20.130.230:8080/list?version=1.0.0
ftp://username:password@192.168.1.7:21/1/read.txt
当然,也有一些不太符合常规的 URL,也被归类到了 URL 之中:
192.168.1.3:20880
url protocol = null, url host = 192.168.1.3, port = 20880, url path = null
file:///home/user1/router.js?type=script
url protocol = file, url host = null, url path = home/user1/router.js
file://home/user1/router.js?type=script<br>
url protocol = file, url host = home, url path = user1/router.js
file:///D:/1/router.js?type=script
url protocol = file, url host = null, url path = D:/1/router.js
file:/D:/1/router.js?type=script
同上 file:///D:/1/router.js?type=script
/home/user1/router.js?type=script
url protocol = null, url host = null, url path = home/user1/router.js
home/user1/router.js?type=script
url protocol = null, url host = home, url path = user1/router.js
2.Dubbo 中的 URL
在Dubbo 中,也使用了类似的 URL,主要用于在各个扩展点之间传递数据,组成此 URL 对象的具体参数如下:
- protocol:一般是 Ddubbo 中的各种协议 如:Dubbo thrift http zk。
- username/password:用户名/密码。
- host/port:主机/端口。
- path:接口名称。
- parameters:参数键值对。
一些典型的 Dubbo URL
dubbo://192.168.1.6:20880/moe.cnkirito.sample.HelloService?timeout=3000
描述一个 dubbo 协议的服务
zookeeper://127.0.0.1:2181/org.apache.dubbo.registry.RegistryService?application=demo-consumer&dubbo=2.0.2&interface=org.apache.dubbo.registry.RegistryService&pid=1214&qos.port=33333×tamp=1545721981946
描述一个 zookeeper 注册中心
consumer://30.5.120.217/org.apache.dubbo.demo.DemoService?application=demo-consumer&category=consumers&check=false&dubbo=2.0.2&interface=org.apache.dubbo.demo.DemoService&methods=sayHello&pid=1209&qos.port=33333&side=consumer×tamp=1545721827784
描述一个消费者
可以说,任意的一个领域中的一个实现都可以认为是一类 URL,Dubbo 使用 URL 来统一描述了元数据,配置信息,贯穿在整个框架之中。
二、Dubbo 2.7
1.URL 结构
在 Dubbo 2.7 中,URL 的结构非常简单,一个类就涵盖了所有内容,如下图所示。

2.地址推送模型
接下来我们再来看看 Dubbo 2.7 中的地址推送模型方案,主要性能问题由下列过程引起:
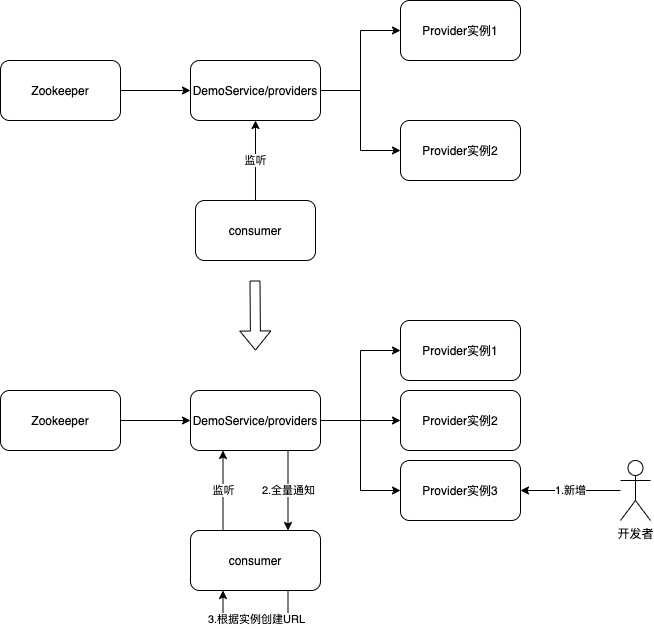
上图中主要的流程为:
(1)用户新增/删除 DemoService 的某个具体 Provider 实例(常见于扩容缩容、网络波动等原因);
(2)ZooKeeper 将 DemoService 下所有实例推送给 Consumer 端;
(3)Consumer 端根据 Zookeeper 推送的数据重新全量生成 URL。
根据该方案可以看出在 Provider 实例数量较小时,Consumer 端的影响比较小,但当某个接口有大量 Provider 实例时,便会有大量不必要的 URL 创建过程。
而 Dubbo 3.0 中则主要针对上述推送流程进行了一系列的优化,接下来我们便对其进行具体的讲解。
三、Dubbo 3.0
1.URL 结构
当然,地址推送模型的优化依然离不开 URL 的优化,下图是 Dubbo 3.0 中优化地址推送模型的过程中使用的新的 URL 结构。
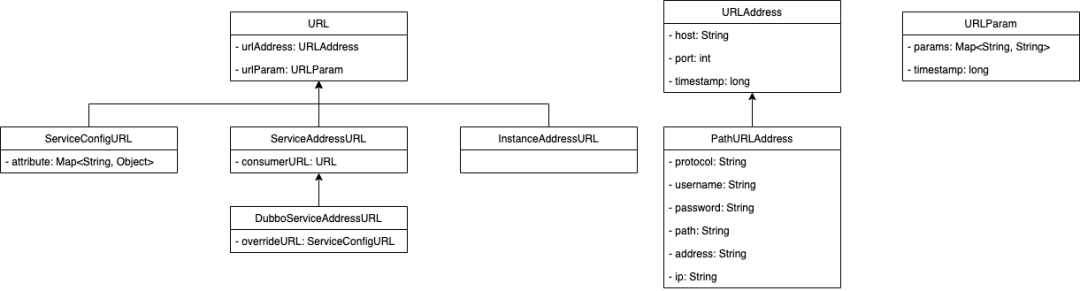
根据上图我们可以看出,在 Dubbo 2.7 的 URL 中的几个重要属性在 Dubbo 3.0 中已经不存在了,取而代之的是 URLAddress 和 URLParam 两个类。原来的 parameters 属性被移动到了 URLParam 中的 params,其他的属性则移动到了 URLAddress 及其子类中。
再来介绍 URL 新增的 3 个子类,其中 InstanceAddressURL 属于应用级接口地址,本篇章中不做介绍。
而 ServiceConfigURL 及 ServiceAddressURL 主要的差别就是,ServiceConfigURL 是程序读取配置文件时生成的 URL。而 ServiceAddressURL 则是注册中心推送一些信息(如 providers)过来时生成的 URL。
在这里我们顺便提一下为什么会有 DubboServiceAddressURL 这个子类,按照目前的结构来看,ServiceAddressURL 只有这一个子类,所以完全可以将他们两个的属性全都放到 ServiceAddressURL 中,那么为什么还要有这个子类呢?其实是 Dubbo 3.0 为了兼容 HSF 框架所设计的,抽象出了一个 ServiceAddressURL,而 HSF 框架则可以继承这个类,使用 HSFServiceAddressURL,当然,这个类目前没有体现出来,所以此处我们简单一提,不过多讲解。
那么,我们接下来就讨论一下 Dubbo 3.0 为什么要改为此种数据结构,并且该结构和地址推送模型的优化有何关联性吧!
2.地址推送模型的优化
- URL 结构上的优化
我们在上小节中的类图里看到虽然原来的属性都被移到了 URLAddress 和 URLParam 里,但是 URL 的子类依然多了几个属性,这几个属性自然也是为了优化而新增的,那么这里就讲讲这几个属性的作用。
ServiceConfigURL:这个子类中新增了 attribute 这个属性,这个属性主要是针对 URLParam 的 params 做了冗余,仅仅只是将 value 的类型从 String 改为了 Object,减少了代码中每次获取 parameters 的格式转换消耗。
ServiceAddressURL:这个子类及其对应的其他子类中则新增了 overrideURL 和 consumerURL 属性。其中 consumerURL 是针对 consumer 端的配置信息,overrideURL 则是在 Dubbo Admin 上进行动态配置时写入的值,当我们调用 URL 的 getParameter() 方法时,优先级为 overrideURL > consumerURL > urlParam。在 Dubbo 2.7 时,动态配置属性会替换 URL 中的属性,及当你有大量 URL 时消耗也是不可忽视的,而此处的 overrideURL 则避免了这种消耗,因为所有 URL 都会共同使用同一个对象。
- 多级缓存
缓存是 Dubbo 3.0 在 URL 上做的优化的重点,同时这部分也是直接针对地址推送模型所做的优化,那么接下来我们就开始来介绍一下多级缓存的具体实现。
首先,多级缓存主要体现在 CacheableFailbackRegistry 这个类之中,它直接继承于 FailbackRegistry,以 Zookeeper 为例,我们看看 Dubbo 2.7 和 Dubbo 3.0 继承结构的区别。
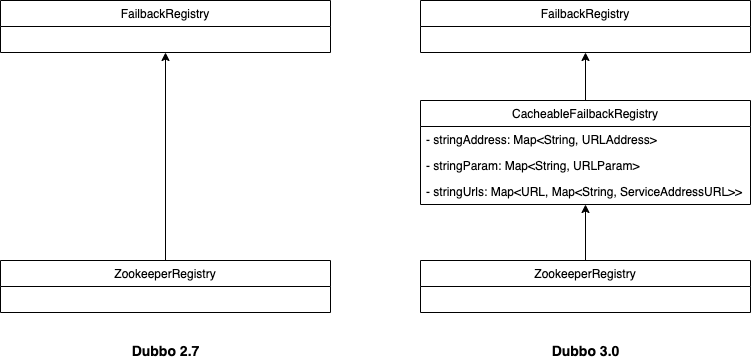
可以看到在 CacheableFailbackRegistry 缓存中,我们新增了 3 个缓存属性 stringAddress,stringParam 和 stringUrls。我们通过下图来描述这 3 个缓存的具体使用场景。
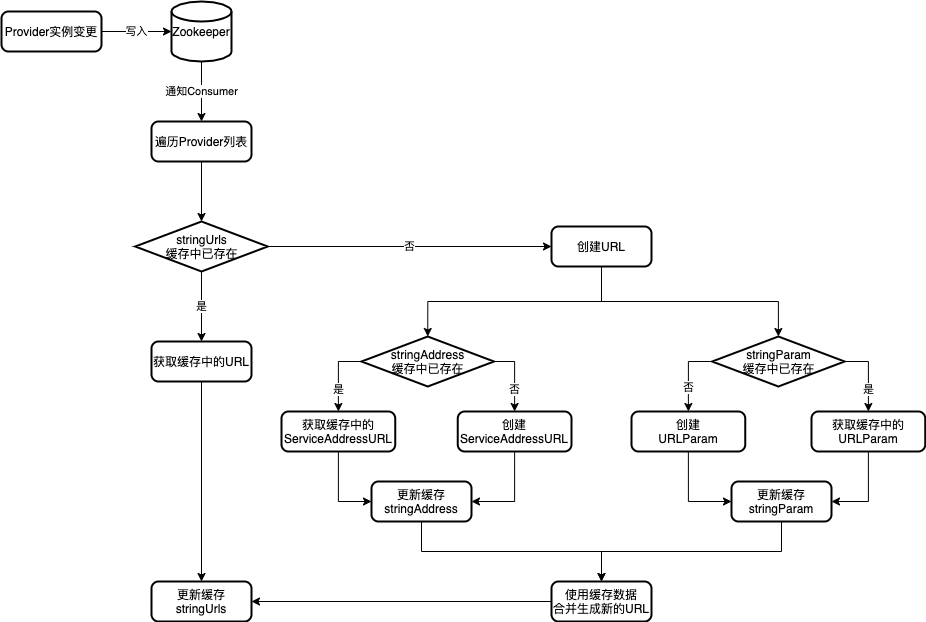
在该方案下,我们使用了 3 个纬度的缓存数据(URL 字符串缓存、URL 地址缓存、URL 参数缓存),这样一来,在大部分情况下都能有效利用到缓存中的数据,减少了 Zookeeper 重复通知的消耗。
- 延迟通知
除了上面提到的优化之外,其实另外还有两个小小的优化。
第一个是解析 URL 时可以直接使用编码后的 URL 字符串字节进行解析,而在 Dubbo 2.7 中,所有编码后的 URL 字符串都需要经过解码才可以正常解析为 URL 对象。该方式也直接减少了 URL 解码过程的开销。
第二个则是 URL 变更后的通知机制增加了延迟,下图以Zookeeper为例讲解了实现细节。
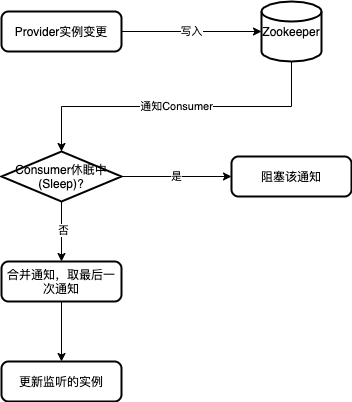
在该方案中,当 Consumer 接收 Zookeeper 的变更通知后会主动休眠一段时间,而这段时间内的变更在休眠结束后只会保留最后一次变更,Consumer 便会使用最后一次变更来进行监听实例的更新,以此方法来减少大量 URL 的创建开销。
- 字符串重用
在旧版本实现中,不同的 URL 中属性相同的字符串会存储在堆内不同的地址中,如 protocol、path 等,当有大量 provider 的情况下,Consumer 端的堆内会存在大量的重复字符串,导致内存利用率低下,所以此处提供了另一个优化方式,即字符串重用。
而它的实现方式也非常的简单,让我们来看看对应的代码片段。
public class URLItemCache {
private static final Map<String, String> PATH_CACHE = new LRUCache<>(10000);
private static final Map<String, String> PROTOCOL_CACHE = new ConcurrentHashMap<>();
// 省略无关代码片段
public static String checkProtocol(String _protocol) {
if (_protocol == null) {
return _protocol;
}
String cachedProtocol = PROTOCOL_CACHE.putIfAbsent(_protocol, _protocol);
if (cachedProtocol != null) {
return cachedProtocol;
}
return _protocol;
}
public static String checkPath(String _path) {
if (_path == null) {
return _path;
}
String cachedPath = PATH_CACHE.putIfAbsent(_path, _path);
if (cachedPath != null) {
return cachedPath;
}
return _path;
}
}
由如上代码片段可以得知,字符串重用即为简单地使用了 Map 来存储对应的缓存值,当你使用了相同的字符串时,便会从 Map 中获取早已存在的对象返回给调用方,由此便可以减少堆内存中重复的字符串数以达到优化的效果。
3.优化结果
这里优化结果我引用了《Dubbo 3.0 前瞻:服务发现支持百万集群,带来可伸缩微服务架构》这篇文章中的两副图来说明,下图模拟了在 220 万个 Provider 接口的情况下,接口数据不断变更导致的 Consumer 端的消耗,我们看到整个 Consumer 端几乎被 Full GC 占满了,严重影响了性能。
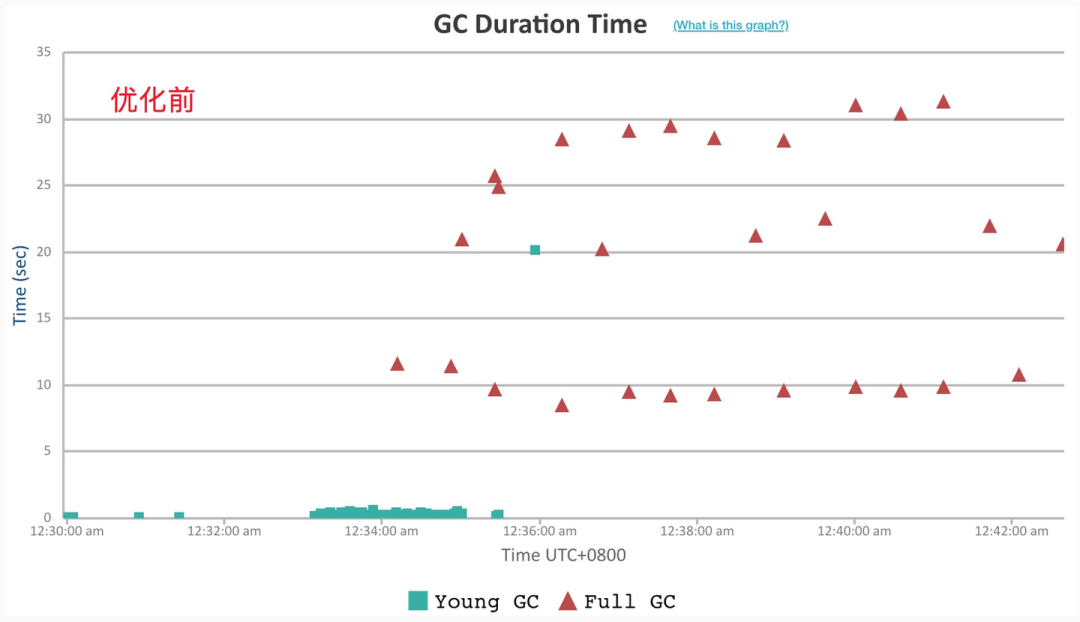
那么我们再来看看 Dubbo 3.0 中对 URL 进行优化后同一个环境下的压测结果,如下图所示。
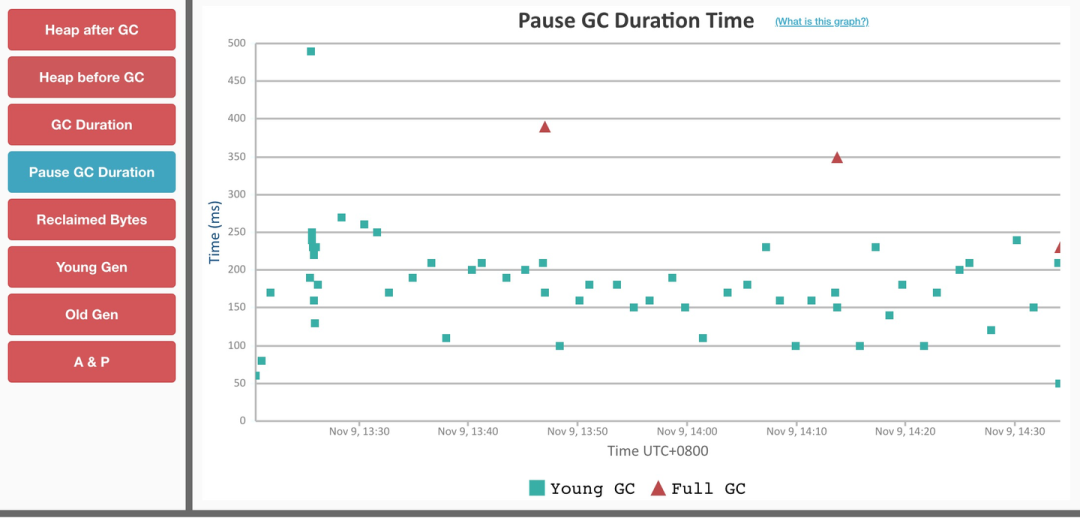
我们明显可以看到 Full GC 的频率减少到了只有 3 次,大大提升了性能。当然,该文章中还有其他方面的对比,此处便不一一引用了,感兴趣的读者可以自行去阅读该文章。
作者介绍:
吴治国,Apache Dubbo 社区活跃贡献者



















