













生成式 transformer 在合成高保真和高分辨率图像方面得到了快速普及。但迄今为止最好的生成式 transformer 模型仍是将图像视为一系列 token,并按照光栅扫描顺序(即逐行)解码图像。然而这种策略既不是最优的,也不高效。
近日,来自谷歌研究院的研究者提出了一种使用双向 transformer 解码器的新型图像合成模型 MaskGIT。在训练期间,MaskGIT 通过关注各个方向的 token 来学习预测随机掩码 token。在推理阶段,模型首先同时生成图像的所有 token,然后以上一次生成为条件迭代地细化图像。实验表明,MaskGIT 在 ImageNet 数据集上显著优于 SOTA transformer 模型,并将自回归解码的速度提高了 64 倍。

论文地址:https://arxiv.org/abs/2202.04200
此外,该研究还表明 MaskGIT 可以轻松扩展到各种图像编辑任务,例如修复、外推和图像处理。
相关研究
先前的模型 VQVAE 提出分两个阶段在潜在空间中生成图像。
第一个阶段称为 tokenization,其中尝试将图像压缩到离散的潜在空间中,这一阶段主要包含三个部分:
一个编码器 E ,负责学习将图像 x∈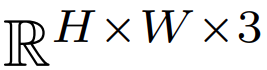 tokenize 成潜在嵌入 E(x);一个用于最近邻查找 codebook
tokenize 成潜在嵌入 E(x);一个用于最近邻查找 codebook 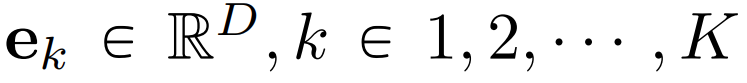 ,以将嵌入量化为视觉 token;一个解码器 G,它根据视觉 token e 预测重建图像
,以将嵌入量化为视觉 token;一个解码器 G,它根据视觉 token e 预测重建图像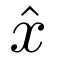 。
。
第二个阶段首先使用深度自回归模型预测视觉 token 的潜在先验,然后使用第一阶段的解码器将 token 序列映射到图像像素中。
这种两阶段范式是很有效的,因此几种常用的方法都遵循了这种范式,例如 DALL-E、VQGAN。其中,VQGAN 在第一阶段增加了对抗性损失和感知损失以提高图像保真度。
MaskGIT
上述使用两阶段范式的方法由于仍然采用自回归模型,因此第二阶段的解码时间与 token 序列长度成比例。而本研究的目标是设计一种利用并行解码和双向生成的新图像合成范式,遵循上述两阶段方案并改进第二阶段。第一阶段采用与 VQGAN 模型相同的设置,并将潜在的改进留给未来工作的 tokenization 步骤;对于第二阶段,研究者提出通过掩码视觉 token 建模(Masked Visual Token Modeling,MVTM 学习双向 transformer。
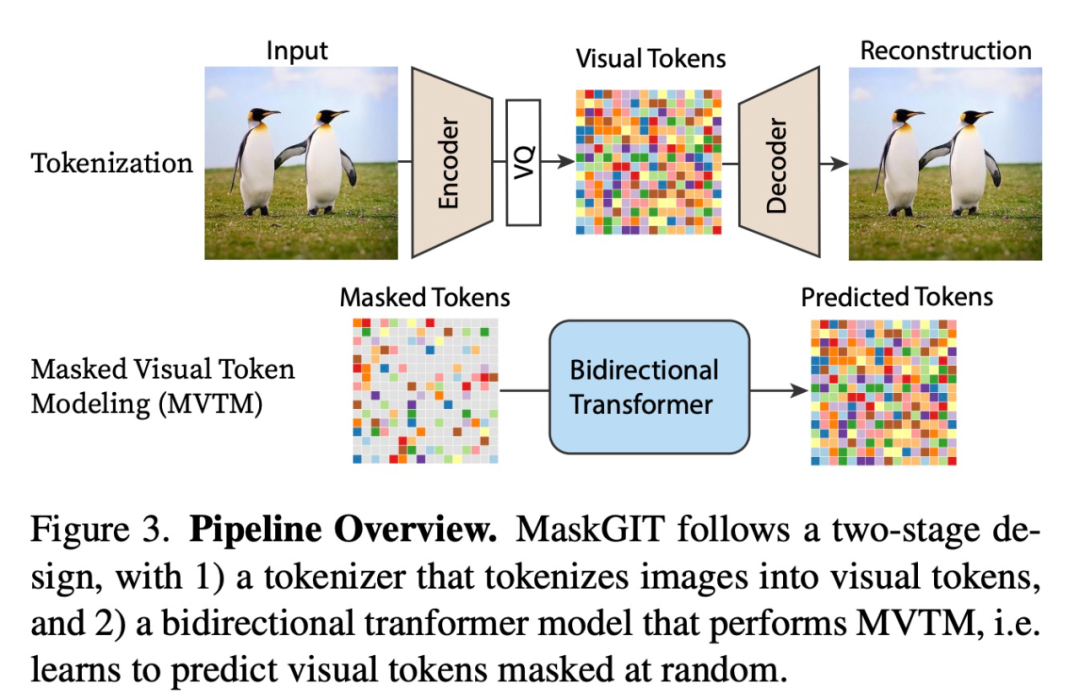
训练中的 MVTM
该研究用 表示将图像输入到 VQ 编码器获得的潜在 token,其中 N 是重构后的 token 矩阵的长度,
表示将图像输入到 VQ 编码器获得的潜在 token,其中 N 是重构后的 token 矩阵的长度, 是对应的二进制掩码。在训练期间,该研究采样 token 的子集,并用一个特殊的 [MASK] token 替代它们。如果 m_i=1,就用 [MASK] 取代 token y_i;如果 m_i=0,y_i 保留。
是对应的二进制掩码。在训练期间,该研究采样 token 的子集,并用一个特殊的 [MASK] token 替代它们。如果 m_i=1,就用 [MASK] 取代 token y_i;如果 m_i=0,y_i 保留。
采样过程由掩码调度函数(mask scheduling function) 进行参数化,然后按照如下步骤:
进行参数化,然后按照如下步骤:
首先从 0 到 1 采样一个比率,然后在 Y 中统一选择 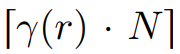 个 token 来放置掩码,其中 N 是长度。掩码调度显著影响了图像的生成质量。
个 token 来放置掩码,其中 N 是长度。掩码调度显著影响了图像的生成质量。
迭代解码
在自回归解码中,token 是根据先前生成的输出顺序生成的。这个过程是不可并行的,而图像的 token 长度通常比语言长得多,因此速度非常慢。该研究提出了一种新型解码方法,其中图像中的所有 token 都是同时并行生成的,这基于 MTVM 的双向自注意力。
理论上讲,该模型能够推断出所有 token 并在单次传递中生成整个图像,但训练任务的不一致给该研究带来了挑战。为了在推理时生成图像,该研究从一个空白 canvas 开始,所有 token 都被掩码,即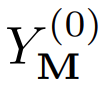 。该研究提出的迭代解码方法,每次迭代的算法运行步骤如下:
。该研究提出的迭代解码方法,每次迭代的算法运行步骤如下:
1. 预测2. 采样3. 掩码调度4. 掩码
掩码设计
研究者发现图像的生成质量受到掩码设计的显著影响。该方法通过一个掩码调度函数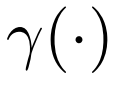 对掩码过程进行建模,该函数负责计算给定潜在 token 的掩码比率。在推理期间,函数
对掩码过程进行建模,该函数负责计算给定潜在 token 的掩码比率。在推理期间,函数 用
用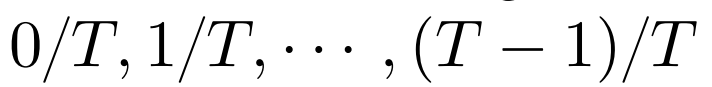 的输入代表解码的进度;在训练期间,该研究在 [0,1) 中随机采样一个比率 r 来模拟各种解码场景。
的输入代表解码的进度;在训练期间,该研究在 [0,1) 中随机采样一个比率 r 来模拟各种解码场景。
实验
该研究从质量、效率和灵活性方面对 MaskGIT 在图像生成方面进行了实验评估。
类条件图像合成
该研究在 ImageNet 256 X 256 和 ImageNet 512 X 512 上评估了 MaskGIT 模型在类条件(class-conditional)图像合成任务上的性能,主要结果如下表 1 所示。
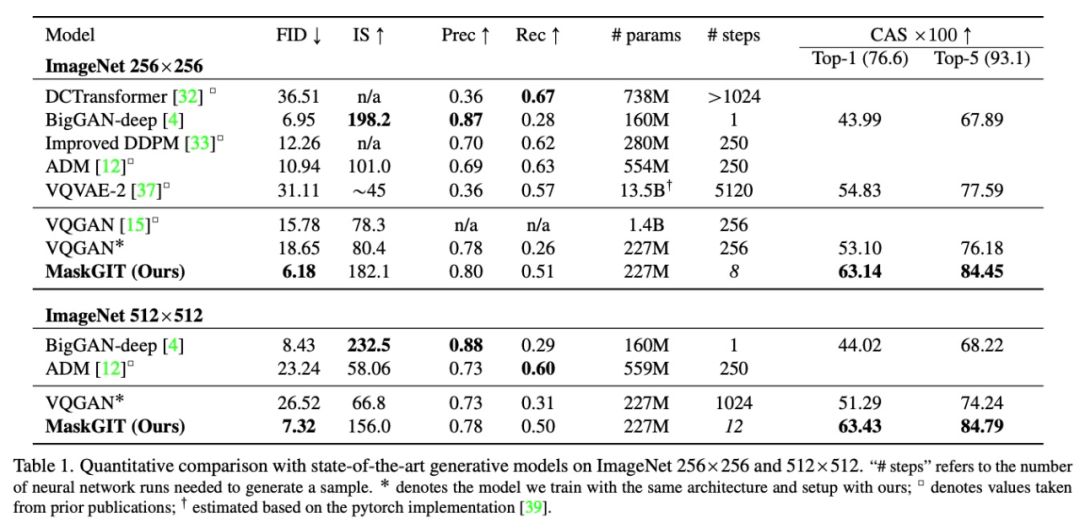
质量。在 ImageNet 256 X 256 上,不使用任何特殊的采样策略,MaskGIT 在 FID 和 IS 方面都显著优于 VQGAN。
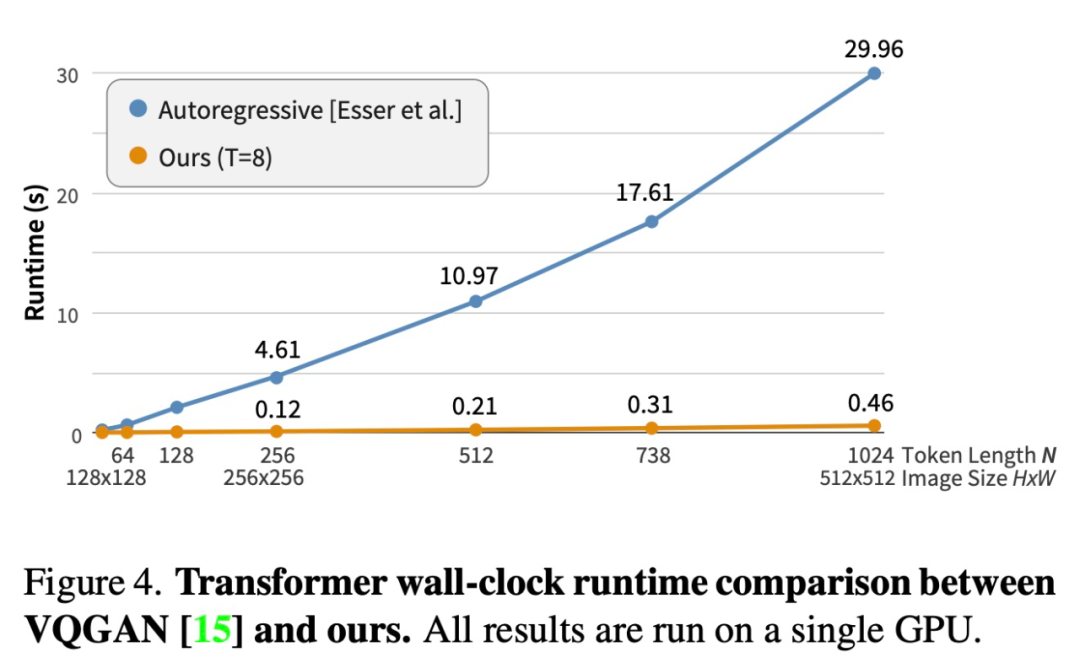
速度。该研究通过评估每个模型生成样本所需的步骤数(前向传递)来评估模型速度。如表 1 所示,在所有基于非 GAN 的模型中,MaskGIT 在两种分辨率上所需的步骤最少。
为了进一步证实 MaskGIT 和自回归模型之间的速度差异,该研究对 MaskGIT 和 VQGAN 的解码过程进行了运行时比较。如下图 4 所示,MaskGIT 将 VQGAN 显著加速了 30-64 倍,随着图像分辨率(以及输入 token 长度)的增加,加速变得更加明显。
多样性。除了样本质量外,该研究还将分类准确率得分 (CAS) 和 Precision/Recall 作为评估样本多样性的两个指标。与 BigGAN 的样本相比,MaskGIT 的样本更加多样化,具有更多种光照、姿态、规模和语境,如下图 5 所示。

图像编辑应用
该研究展示了 MaskGIT 在三个图像编辑任务上的直接应用:类条件图像编辑、图像修复和图像扩展(outpainting)。如果将任务看作对初始二进制掩码 M MaskGIT 在其迭代解码中使用约束,那么这三个任务几乎都可以轻松地转换为 MaskGIT 可以处理的任务。
该研究表明,无需修改架构或任何特定于任务的训练,MaskGIT 就能够在所有三个应用程序上产生非常优秀的结果。此外,MaskGIT 在图像修复和扩展方面获得了与专用模型相当的性能。
在类条件图像编辑任务上,该研究定义了一个新的类条件图像编辑任务来展示 MaskGIT 的灵活性。模型在给定类的边界框内重新生成特定内容,同时保留语境,即框外的内容。由于违背了预测顺序,因此自回归方法是不可行的。
然而,对于 MaskGIT,如果将边界框区域视为迭代解码算法的初始掩码的输入,这个问题就迎刃而解了。下图 6 给出了一些示例结果。

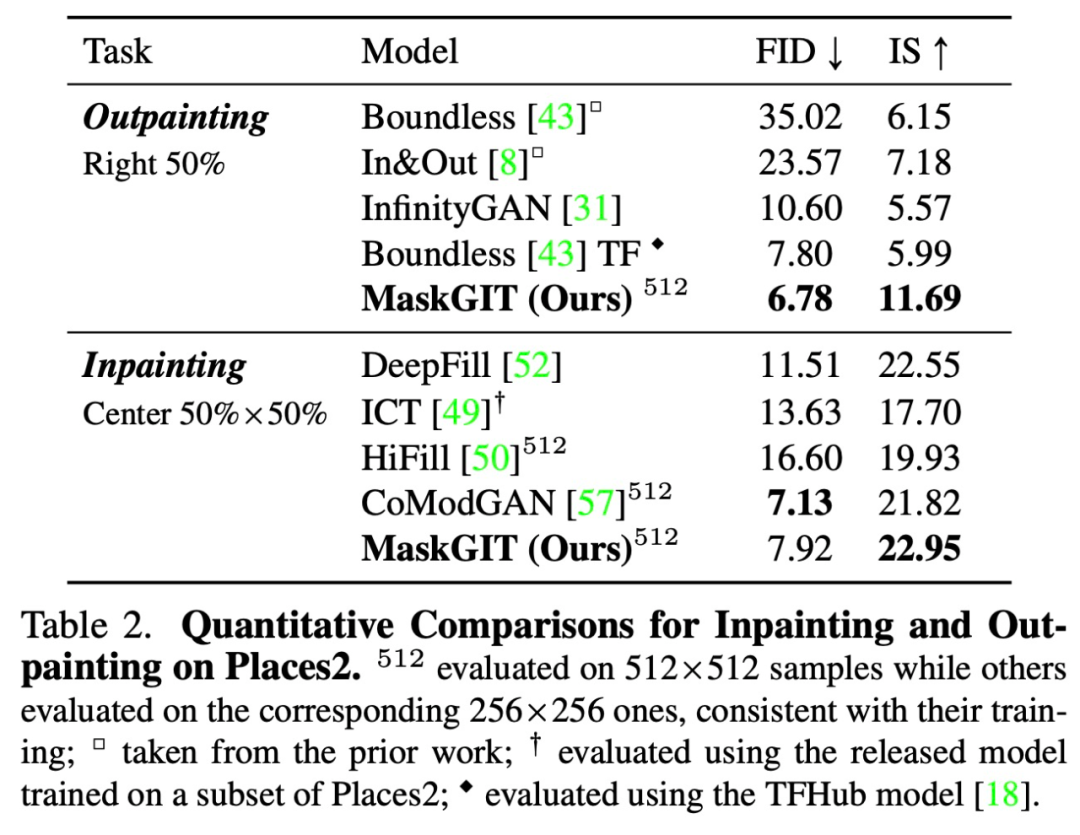
表 2 比较了几种方法的定量结果。MaskGIT 在 FID 和 IS 中均以显著优势击败 DeepFill 和 HiFill,同时获得接近 SOTA 修复方法 CoModGAN 的分数。
如下图 7 所示,MaskGIT 还能够在给定相同输入和不同种子的情况下合成不同的结果。

消融实验
为了验证新设计的效用,该研究在 ImageNet 256×256 的默认设置上进行了消融实验。MaskGIT 的一个关键设计是用于训练和迭代解码的掩码调度函数,实验结果如下表 3 和图 8 所示。
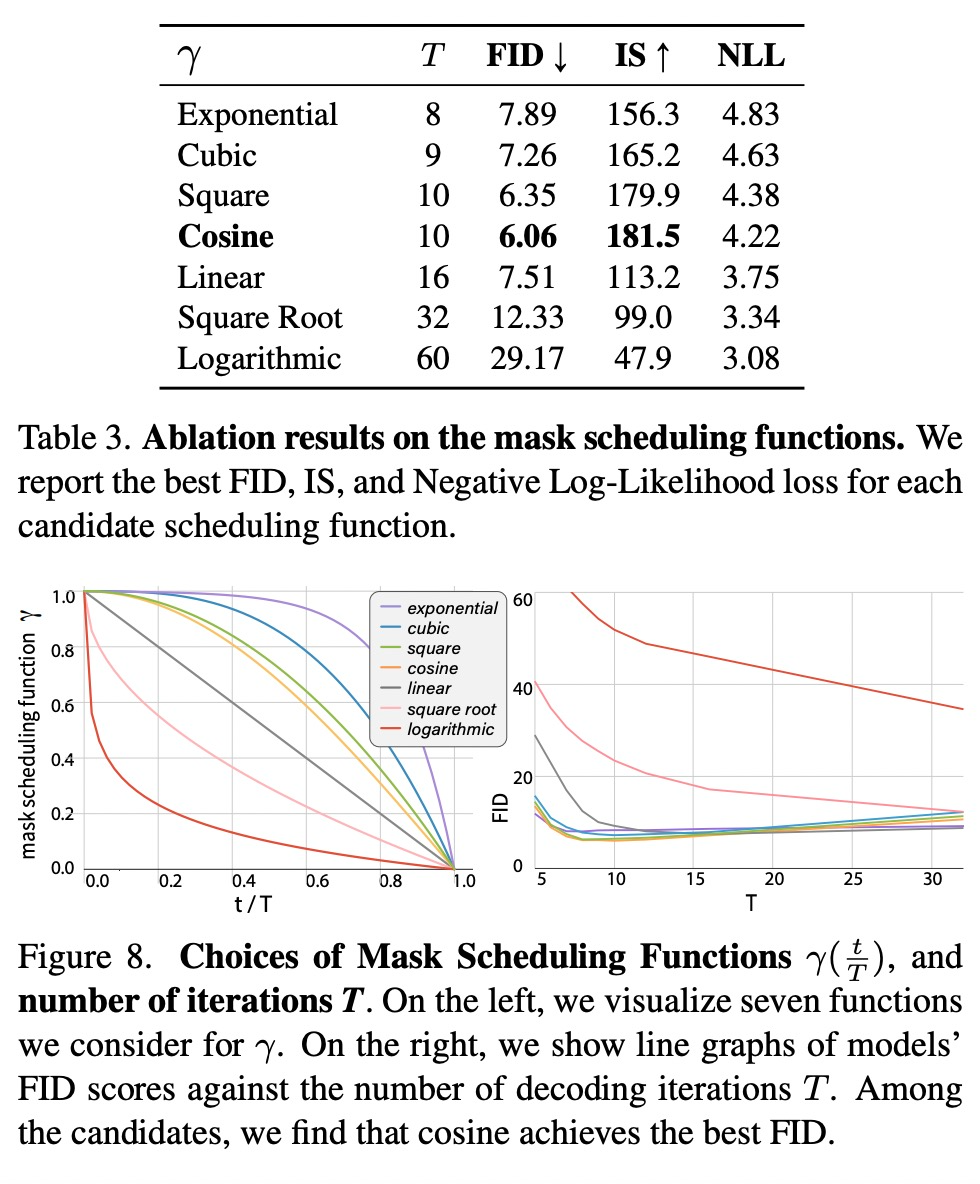
值得注意的是,如图 8 所示,在相同的设置下,更多的迭代不一定更好:随着迭代次数 T 的增加,除了对数函数在整个过程中都表现不佳以外,其他所有函数都达到了一个「sweet spot」位置,即模型的性能在再次恶化之前达到峰值。



























