缓存 是我们写代码过程中常用的一种手段,是一种空间换时间的做法。就拿我们经常使用的 HTTP 协议,其中也存在强缓存和协商缓存两种缓存方式。当我们打开一个网站的时候,浏览器会查询该请求的响应头,通过判断响应头中是否有 Cache-Control、Last-Modified、ETag 等字段,来确定是否直接使用之前下载的资源缓存,而不是重新从服务器进行下载。
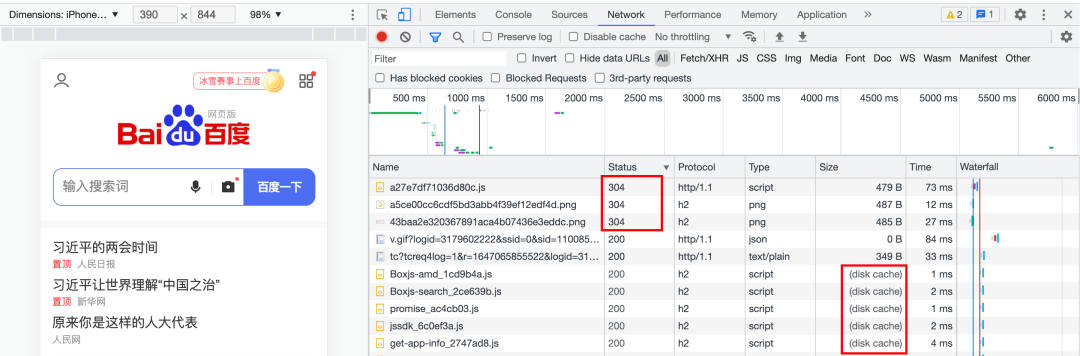
下面就是当我们访问百度时,某些资源命中了协商缓存,服务端返回 304 状态码,还有一部分资源命中了强缓存,直接读取了本地缓存。
但是,缓存并不是无限制的,会有大小的限制。无论是我们的 cookie(不同浏览器有所区别,一般在 4KB 左右),还是 localStorage(和 cookie 一样,不同浏览器有所区别,有些浏览器为 5MB,有些浏览器为 10MB),都会有大小限制。
这个时候就需要涉及到一种算法,需要将超出大小限制的缓存进行淘汰,一般的规则是淘汰掉最近没有被访问到的缓存,也就是今天要介绍的主角:LRU (Least recently used:最近最少使用)。当然除了 LRU,常见的缓存淘汰还有 FIFO(first-in, first-out:先进先出) 和 LFU(Least frequently used:最少使用)。
什么是 LRU?
LRU (Least recently used:最近最少使用)算法在缓存写满的时候,会根据所有数据的访问记录,淘汰掉未来被访问几率最低的数据。也就是说该算法认为,最近被访问过的数据,在将来被访问的几率最大。
为了方便理解 LRU 算法的全流程,画了一个简单的图:
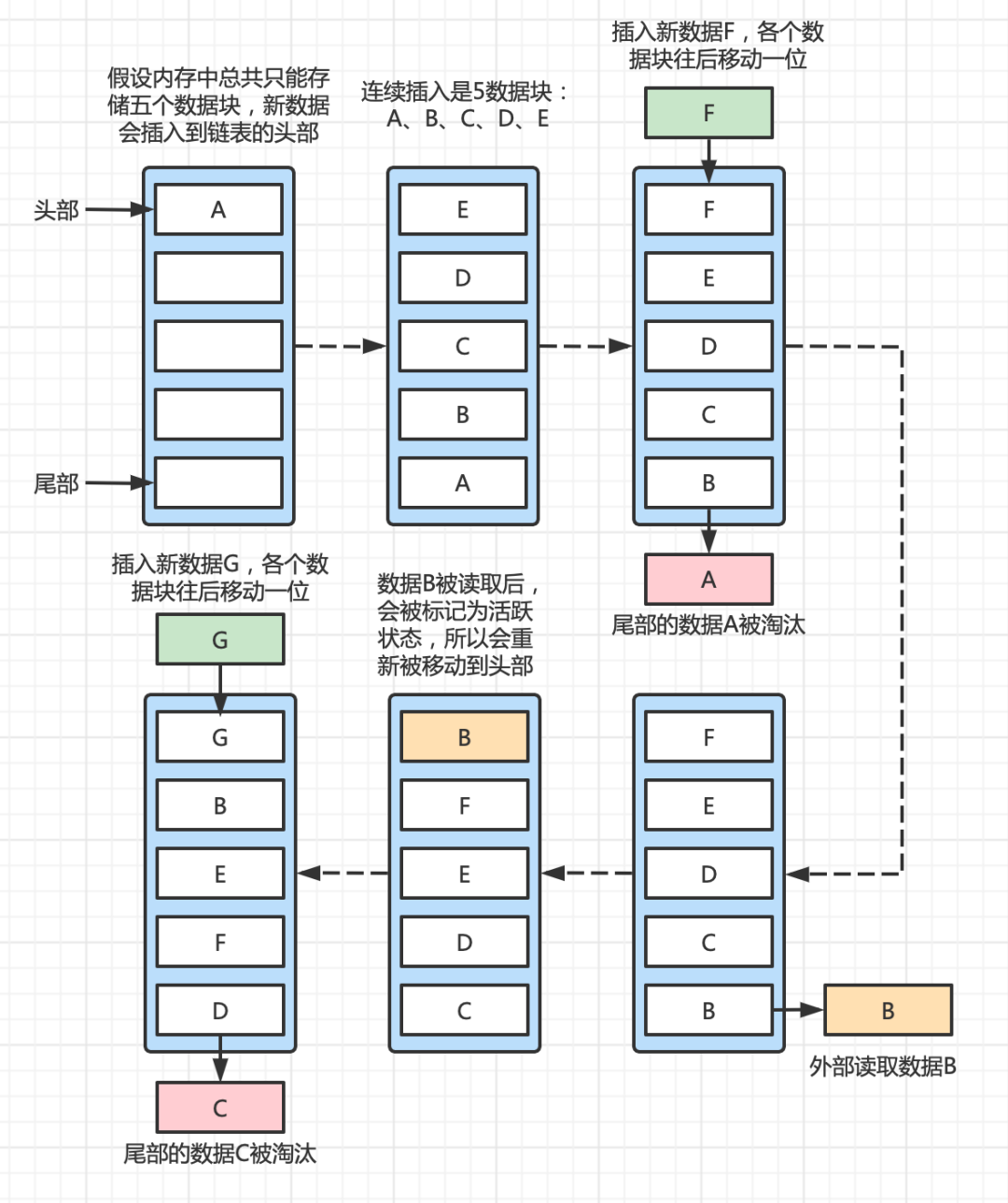
- 假设我们有一块内存,一共能够存储 5 数据块。
- 依次向内存存入A、B、C、D、E,此时内存已经存满。
- 再次插入新的数据时,会将在内存存放时间最久的数据A淘汰掉。
- 当我们在外部再次读取数据B时,已经处于末尾的B会被标记为活跃状态,提到头部,数据C就变成了存放时间最久的数据。
- 再次插入新的数据G,存放时间最久的数据C就会被淘汰掉。
算法实现
下面通过一段简单的代码来实现这个逻辑。
class LRUCache {
list = [] // 用于标记先后顺序
cache = {} // 用于缓存所有数据
capacity = 0 // 缓存的最大容量
constructor (capacity) {
// 存储 LRU 可缓存的最大容量
this.capacity = capacity
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
基本的结构如上所示,LRU需要实现的就是两个方法:get 和 put。
class LRUCache {
// 获取数据
get (key) { }
// 存储数据
put (key, value) { }
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
我们现在看看如何进行数据的存储:
class LRUCache {
// 存储数据
put (key, value) {
// 存储之前需要先判断长度是否达到上限
if (this.list.length >= this.capacity) {
// 由于每次存储后,都会将 key 放入 list 最后,
// 所以,需要取出第一个 key,并删除cache中的数据。
const latest = this.list.shift()
delete this.cache[latest]
}
// 写入缓存
this.cache[key] = value
// 写入缓存后,需要将 key 放入 list 的最后
this.list.push(key)
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
然后,在每次获取数据时,都需要更新 list,将当前获取的 key 放到 list 的最后。
class LRUCache {
// 获取数据
get (key) {
if (this.cache[key] !== undefined) {
// 如果 key 对应的缓存存在
// 在返回缓存之前,需要重新激活 key
this.active(key)
return this.cache[key]
}
return undefined
}
// 重新激活key,将指定 key 移动到 list 最后
active (key) {
// 先将 key 在 list 中删除
const idx = this.list.indexOf(key)
if (idx !== -1) {
this.list.splice(idx, 1)
}
// 然后将 key 放到 list 最后面
this.list.push(key)
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
这个时候,其实还没有完全实现,因为除了 get 操作,put 操作也需要将对应的 key 重新激活。
class LRUCache {
// 存储数据
put (key, value) {
if (this.cache[key]) {
// 如果该 key 之前存在,将 key 重新激活
this.active(key)
this.cache[key] = value
// 而且此时缓存的长度不会发生变化
// 所以不需要进行后续的长度判断,可以直接返回
return
}
// 存储之前需要先判断长度是否达到上限
if (this.list.length >= this.capacity) {
// 由于每次存储后,都会将 key 放入 list 最后,
// 所以,需要取出第一个 key,并删除cache中的数据。
const latest = this.list.shift()
delete this.cache[latest]
}
// 写入缓存
this.cache[key] = value
// 写入缓存后,需要将 key 放入 list 的最后
this.list.push(key)
}
}- 1.
- 2.
- 3.
- 4.
- 5.
- 6.
- 7.
- 8.
- 9.
- 10.
- 11.
- 12.
- 13.
- 14.
- 15.
- 16.
- 17.
- 18.
- 19.
- 20.
- 21.
- 22.
- 23.
- 24.
- 25.
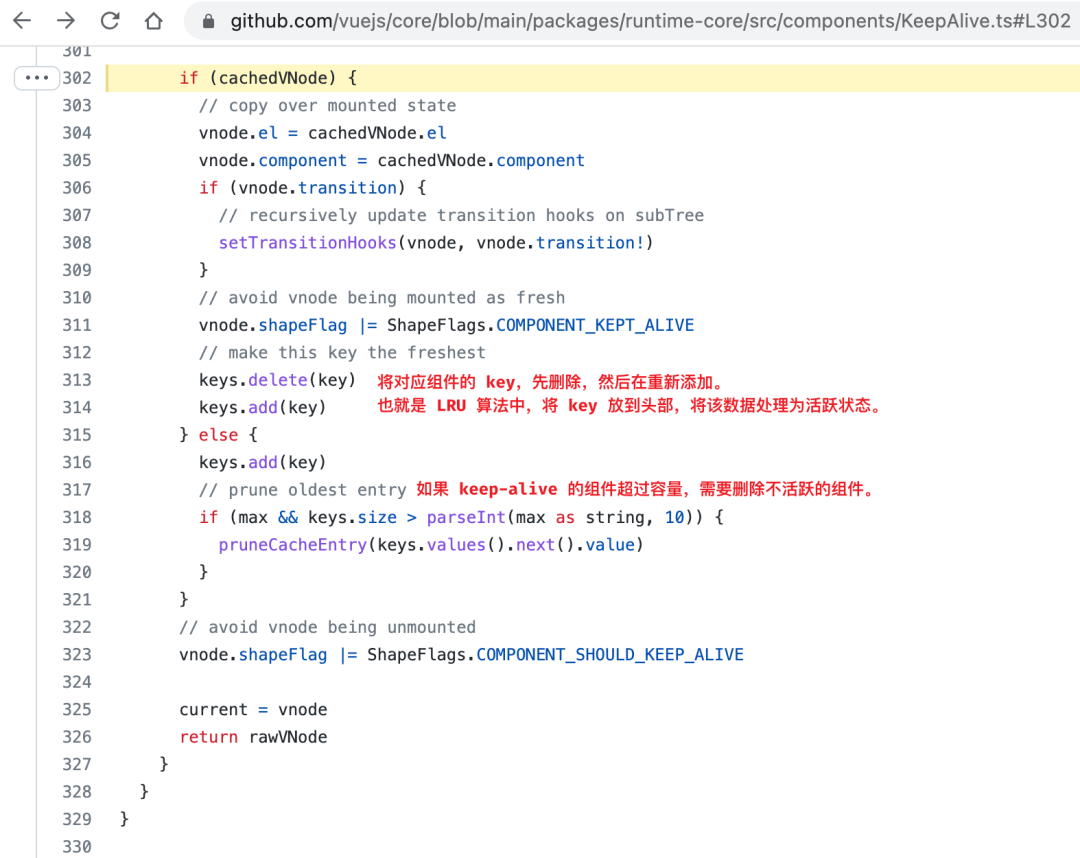
可能会有人觉得这种算法在前端没有什么应用场景,说起来,在 Vue 的内置组件 keep-alive 中就使用到了 LRU 算法。
后续应该还会继续介绍一下 LFU 算法,敬请期待。