大家好,我是一哥。
ETL 和 ELT 有很多共同点,从本质上讲,每种集成方法都可以将数据从源端抽取到数据仓库中,两者的区别在于数据在哪里进行转换。 接下来,我们一起详细地分析一下 ETL 和 ELT各自的优缺点,看看在你们现在的业务中用哪种方式处理数据比较合适。
1.ETL

ETL - 抽取、转换、加载
从不同的数据源抽取信息,将其转换为根据业务定义的格式,然后将其加载到其他数据库或数据仓库中。另一种 ETL 集成方法是反向 ETL,它将结构化数据从数据仓库中加载到业务数据库中,如我们常用数据仓库加工好的报表,推送到报表系统的数据库中。
2.ELT

ELT - 抽取、加载、转换
同样的从一个或多个数据源中抽取数据,然后将其加载到目标数据仓库中,此时不需要进行数据格式的转换。在 ELT 过程中,数据的转换发生在目标数据仓库中。ELT 对远程资源的要求较少,只需要它们的原始数据即可。
3.ELT的演变
ELT 已经存在了一段时间,但 Hadoop 等大数据技术出现后,更加活跃了。像以前转换 PB 级原始数据这样的大型任务无法处理,现在可以被分成小作业,进行处理,然后再加载到目标数据库中。同时,处理能力也提高了,尤其是以私有云集群的方式,把处理、加工数据可以在一个数据仓库中完成了。
4.ELT的工作原理
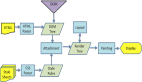
与 ETL 不同,ELT是从多个数据源收集信息,将其加载到数据仓库(或者数据湖)中,然后将其转换为可操作的商业智能的过程。
抽取——在ELT和ETL两种数据管理方法中的原理相似。一般我们会采用增量抽取,对于一些维表数据量比较小的也会采用全量抽取。
加载——这是 ELT 和 ETL 开始不同的地方了。ELT 不是在抽取大量原始数据的过程中将其转换,而是将所有数据都加在到湖仓中,然后统一进行转换,这样做加快了抽取的效率,但也意味着数据变得有用之前还有很多工作要做。
转换——数据湖或数据仓库对数据进行规范化,将部分或全部数据保留在湖仓中,并可用于定制报告。存储海量数据的开销更高,但也是为了后续能够更加快速的进行数据挖掘和报表展现,也就是我们常说的用空间换时间。
5.什么时候我们选择ELT
这取决于公司现有的网络和技术架构、预算以及它已经利用云和大数据技术的程度。如果是有下面三个需求场景时,那么ELT就是正确的选择~
(1)当抽取速度是第一选择时
因为 ELT 不必等待数据在抽取过程中进行转换后再加载,那么抽取过程要快得多。
(2)当需要随时访问原始数据时
有很多场景,我们需要保留所有历史数据,分析师可以根据时间、销售模式、季节性趋势或任何对业务变得重要的新兴指标进行挖掘。由于数据在加载之前未进行转换,因此您可以访问所有原始数据。比如,数据仓库一般都有一个原始数据层,很多数据科学家更喜欢访问原始数据,而业务用户更喜欢使用分析后的应用层或者模型层数据。
(3)当需要随时可扩展数据湖仓时
当您使用 Hadoop 或云数据仓库等数据处理引擎时,ELT 可以利用本机处理能力实现更高的可扩展性。
6.数据湖是不是很好的ELT落脚点
首先,我们思考一下数仓为什么会出现?其实是数据量的飞速增长,以至于当时的数据存储计算引擎,不能很好的满足分析需求;于是数仓概念和经典的理论出现了,很好的解决了当时的问题,用“规范+存储”来解决了当时的问题。
那么现在大数据时代,随着技术的不断发展,很多新技术出现了,大批量的存储和计算不再是那么难了,那么我们放弃数仓那一套是否可行呢?从一哥现在处理的业务看,如果你的业务系统相对较单一,没有几十个业务系统每天往数仓里灌数据,那么数据湖可以满足你的需求,并且对于“数据驱动”更“敏捷”。如果一线的业务系统较复杂,那么现在使用数据湖也会一不小心会变成“数据沼泽”。
数据湖治理策略没有明确前,还不要急着就上数据湖,并不是适用于每个公司的业务场景的!
7.结语
ELT和ETL都有各自的应用场景,可以说现在大数据环境下,很多已经是ELT架构了,所以这也是我近几年一直不看好很多厂商在推“拖拉拽”的ETL工具或者平台,未来肯定是需要一种通用语言来实现所有的ELT过程。
同样,数据湖是趋势,但现在依然不成熟,不要看网上很多一线大厂的技术文章中提到了很多数据湖的概念和技术应用,但是请结合自己公司的业务场景,暂时先谨慎选择!
本文转载自微信公众号「数据社」,可以通过以下二维码关注。转载本文请联系数据社公众号。