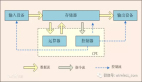
数据库和存储是密切相关的两个IT组件,很多数据库的问题有可能和存储的问题相关。不过在IT运维中,数据库和存储的运维管理一般属于两个互相独立的部门,因此二者的配合总是无法达到十分默契的程度。
数据库出现IO问题的时候,DBA总是希望能把问题推诿给存储,说是存储的IO能力不行。而存储专业后面已经没有背锅侠了,所以没办法再往后推,只能选择反击,自证自己没问题,问题一定出在数据库本身或者前面的应用。
存储管理员一般会用一份DBA看的云山雾罩的报告来证明存储本身没有问题。DBA也因为专业知识不够丰富而往往只能接受这个问题,集中精力去找前端应用的麻烦。这样的例子在实际生活中比比皆是,不过这种情况存在,对于企业的IT运维来说并不是一件好事情,很多这样的隐患都被这种退位埋藏下来,等到爆发的那一天一定是一件大事。
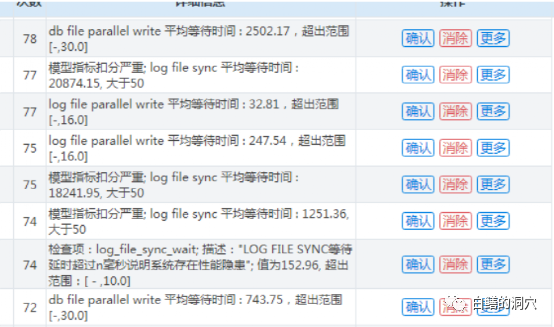
几年前遇到一个案例,客户的系统中的5套数据库突然依次宕机,后来重启后系统恢复正常。从D-SMART的历史数据看,存在大量的写IO的延时异常问题。
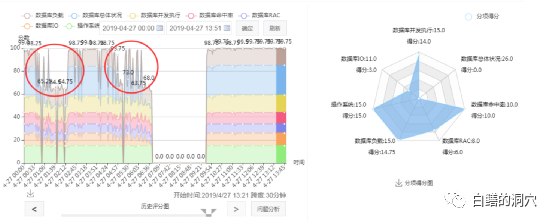
从健康模型上看,这个问题实际上在宕机前就已经比较严重了。IO存在十分严重的问题。通过工具进行了一下IO诊断。

诊断工具分析后端存储的IO性能存在问题。根据这种情况,我们认为存储的链路可能存在问题,报给客户后,客户也找存储厂商过来检查了一番。因为这件事发生在早上业务高峰,对企业的一个核心外网APP造成了严重的影响,因此大家都在推诿。存储厂商坚称存储绝对没有问题,因为数据重启后系统都很正常。我们通过D-SMART观察发现,数据看重启后,写IO的性能依然不是很正常,不过存储厂家坚称没问题。于是客户也就只能找了几条写的不好的SQL,让开发商整改了事了。
事后我和负责系统运维的主管沟通了了一下,提醒他注意一下存储的问题,我还是怀疑存储的硬件或者SAN网络的链路存在问题。不过那个哥们也没太把我的话当回事。一个多月后,同样的问题在此发生。上面大领导震怒,于是开展了排查工作,最终发现了存储中一条链路不稳定的隐患。
正是因为存储对于数据看来说十分重要,因此很多企业希望能够打通这一壁垒,让DBA也能十分直观的看到存储的情况。那么现在问题就来了,作为DBA,你想怎么去看存储系统呢?
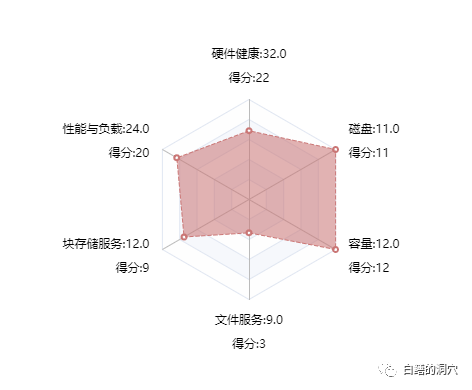
这是D-SMART的存储的健康模型,作为一个从数据库监控发展起来的运维工具,虽然现在D-SMART已经支持了大量的非数据库组件,不过这个系统的核心开发者是一群DBA,这种视角来看存储绝对是和大多数存储管理员不同的。硬件健康十分明确,任何软硬件一体化的IT基础设施的硬件健康是必须去监控的。
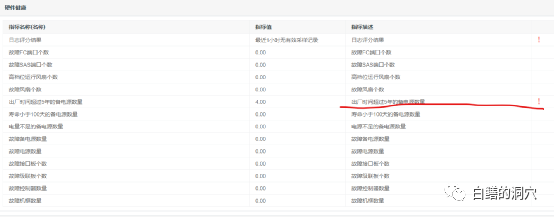
这套存储的硬件总体健康度还可以,不过有四个备电源出厂时间已经超过5年,存在老化的隐患,如果这是一套十分重要的存储系统,需要及时更换老化的备点,从而避免系统出问题。
当然磁盘的健康状态也是我们所关注的。现在的中高端存储系统的底层软件做的很好,某块磁盘故障虽然不会引起应用的问题,不过磁盘故障后的磁盘组的REBUILD还是会引起一些IO性能问题的。如果业务高峰期的IO十分大,这种磁盘引起的故障很可能会引发应用的性能问题。
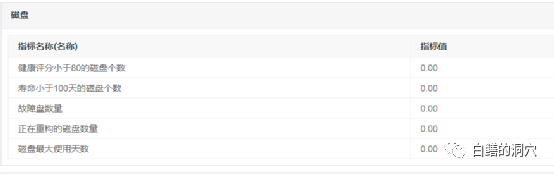
在磁盘方面我们选取了一些经过评估的指标,磁盘健康分是对磁盘的SMART数据进行综合评估后的结果,有些高端存储中也自带评估值。另外容量、性能、负载等也是我们关注的磁盘的指标。除了这些指标之外,我们还需要根据以往DBA的经验来构建一些存储的故障告警的模型,因为存储系统十分复杂,某些硬件健康可能会带来哪些后果,哪些可能会影响数据库的健康,这些问题作为DBA实际上并不清楚。
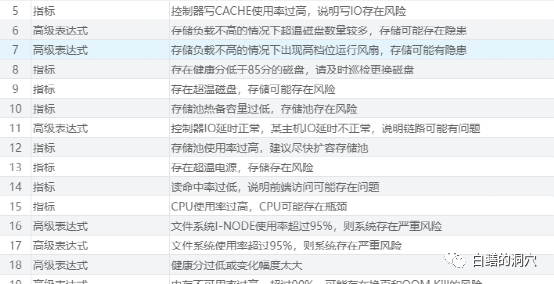
基于上述原因,DBA监控存储系统,需要总结一系列的经验,通过这些经验来帮助我们发现存储中存在的问题,否则DBA就会像一个土老帽一样,在存储工程师的厚厚的报告中败下阵来。实际上,在绝大多数的IT运维甩锅行动中,DBA很少能够战胜存储管理员。
比如说,“如果控制器IO延时正常,某个主机延时异常,那么可能说明问题是在链路上”,这一点仔细想一想,任何一个DBA都能想清楚吧。实际上,存储管理员很清楚这一点,不过他们不会告诉DBA,而是很可能会找个时间,偷偷的把有问题的链路找出来,然后换掉。另外如果出现“IO负载不高,但是存在大量转速过高的风扇”,那是不是意味着存储存在隐患呢?
实际上,我们需要大量的积累类似的运维经验,从而可以从一些很可能存储管理员都没有意识到的现象中看出存储可能存在的问题。如果DBA能够掌握这些主动,在这场运维甩锅大赛中,会占据主动。
当然,今天讲的背锅侠的事情大多数都是玩笑话,一个IT团队中,DBA和存储管理员是协作最多的,他们紧密的配合才能让我们的数据库系统变得更为稳定。而在一个企业中,能够用DBA比较容易看懂的方式来监控存储系统,绝对是十分必要的。希望今天我分享的这些内容会给大家带来一些启发。