背景
在传统的命令式编程模式下,程序都是按照人工编写的指令一条条顺序的同步执行,也就是说,只有当前指令运行完毕,下一条指令才开始执行。那么传统的命令式编程有有些线程处理模型呢?
首先是同步阻塞式,在这种模型下,只有阻塞操作完成后,程序才能够继续执行。而且阻塞会浪费资源,比如等待网络连接(数据库请求,其他服务请求),就会导致执行线程处于空闲状态。
第二种就是异步阻塞式,在这种方式下一般会通过线程池,创建很多线程,然后针对请求,分配空闲的线程来处理。每个处理线程当遇到阻塞操作时,还是会中断等待操作完成,不过相对于同步阻塞的模式,减少了任务的响应时间。通过增加并行度,提升了资源利用率。
第三种是异步非阻塞,通过回调方法来摒弃阻塞操作带来的资源浪费。不过回调函数会层层嵌套,导致回调噩梦(callback hell),让可读性变得很差。
为了利用第三种模型的优势,同时又让代码维护性更高,spring社区推出了spring flux响应式非阻塞编程。它默认的实现叫projectreactor。projectreactor是JVM的完全非阻塞响应式编程基础,具有高效的需求管理(以管理“背压”的形式).它提供了可组合的异步序列API Flux(用于[0…N]元素)和 Mono(用于[0 | 1]元素),广泛地实现了Reactive Extensions规范。
特点
响应式编程的特点包括以下几点。待会会通过例子给大家详细展示下。
- 可组合性&可读性
- 直到订阅才会发生任何事情
- 采用背压或通过其他方式消费者向生产者发出排放率过高的信号的能力
- 具体丰富的数据流运算符
- 高水平但高价值的抽象是并发性不可知的
实现
projectreactor引入了可组合的反应类型,它们实现Publisher同时也提供了丰富的操作符,尤其是 Flux 和Mono 。
Flux 表示一个0..N项的反应序列,可以有 完成信号、错误信息来结束整个流程。所以传输的数据为一个普通值、一个完成信号、一个错误信号。对应的方法为onNext()、onComplete()、onError()。
而一个Mono对象表示一个单值或空的(0..1)结果,可以认为是一种特殊的 Flux,最多可以发出一个普通值,同样包含onComplete()、onError()。
示例
- 静态数据创建
直接调用just()方法进行创建,也可以通过一个Stream或者一个Iterable对象(比如List)。还有通过Flux静态方法来生成,range方法(这个方法生成的是一个 Integer 序列,第一个参数表示起始数字,第二个参数表示,生成的个数,这里生成的数据就为1、2、3),empty() 方法就是生成一个空的序列。
Flux<String> flux1 = Flux.just("one", "two", "three");
Flux<String> flux2 = Flux.fromStream(Stream.of("one", "two", "three"));
List<String> iterable = Arrays.asList("one", "two", "three");
Flux<String> flux3 = Flux.fromIterable(iterable);
Flux<Integer> flux4 = Flux.range(1, 3);
//或者通过 #empty() 生成空数据
Flux<String> fluxEmpty = Flux.empty()
Mono 也有类似的创建方法,只是对于的 just() 方法是对应只是一个参数。而 justOrEmpty() 方法会对空值进行校验,选择调用 just() 或者 empty()。
//Mono 也是类型
Mono<String> monoEmpty = Mono.empty();
Mono<String> mono1 = Mono.just("one");
//justOrEmpty 可以保证传入参数为空时也不会报错
Mono<String> mono2 = Mono.justOrEmpty(null);
- 动态数据创建
动态数据创建方法主要有generate与create两种方法。
对于generate 方法,在Flux中有3个重载方法,不管是哪个方法都是会包含一个循环构造函数。在每个循环中,sink.next()方法最多被调用一次。比如在 flux_generate1 这个实例对应的方法。循环生成1~10的序列,当atomicInteger大于10的时候就调用complete()方法,发出信息通知订阅者。flux_generate2 实例对应的方法则将atomicInteger作为一个对象,在方法中进行传递,并且在最后打印在控制台上。
// generate 生成,调用 next 即生成数据,complete 则是完成了整个流程
// 一个循环中只允许调用 next 方式一次
AtomicInteger atomicInteger = new AtomicInteger();
Flux<Integer> flux_generate1 = Flux.generate(sink -> {
if(atomicInteger.incrementAndGet() > 10){
sink.complete();
}
sink.next(atomicInteger.get());
});
Flux<Integer> flux_generate2 = Flux.generate(() -> 0, (integer, sink) -> {
if (++integer > 10) {
sink.complete();
}
sink.next(integer);
return integer;
}, integer -> {
System.out.println("last integer value is " + integer);
});
执行过程解析
为了更好的理解flux的底层实现逻辑和编程思想,我们下面会给大家详细的演示下flux.create方法的执行。尤其是前面提到的直到订阅才会发生任何事情,这句话的真实含义。
flux.create((t) -> {
t.next("create");
t.next("create1");
}).subscribe(st->{
System.out.println(st);
});
上面是我们要执行的一段代码。通过debug我们可以看到如下的执行过程。
- Flux.create方法接受一个函数式接口Consumer作为输入参数,在我们这个例子中就是。
(t) -> {
t.next("create");
t.next("create1");
},
public static <T> Flux<T> create(Consumer<? super FluxSink<T>> emitter) {
return create(emitter, OverflowStrategy.BUFFER);
}
- 我们一路追踪下去,发现它把我们的函数式接口赋值给了Fluxcreate对象的一个属性source,然后就返回了。并没有执行这个函数式接口的逻辑。
FluxCreate(Consumer<? super FluxSink<T>> source, OverflowStrategy backpressure, FluxCreate.CreateMode createMode) {
this.source = (Consumer)Objects.requireNonNull(source, "source");
this.backpressure = (OverflowStrategy)Objects.requireNonNull(backpressure, "backpressure");
this.createMode = createMode;
}
- 那么什么时候执行我们的代码逻辑呢,接着向下看。subscribe方法也是接收了一个函数式接口。
(st->{
System.out.println(st);
})
public final Disposable subscribe(Consumer<? super T> consumer) {
Objects.requireNonNull(consumer, "consumer");
return this.subscribe(consumer, (Consumer)null, (Runnable)null);
}
- 下面我们看看调用subscribe后发生了什么。
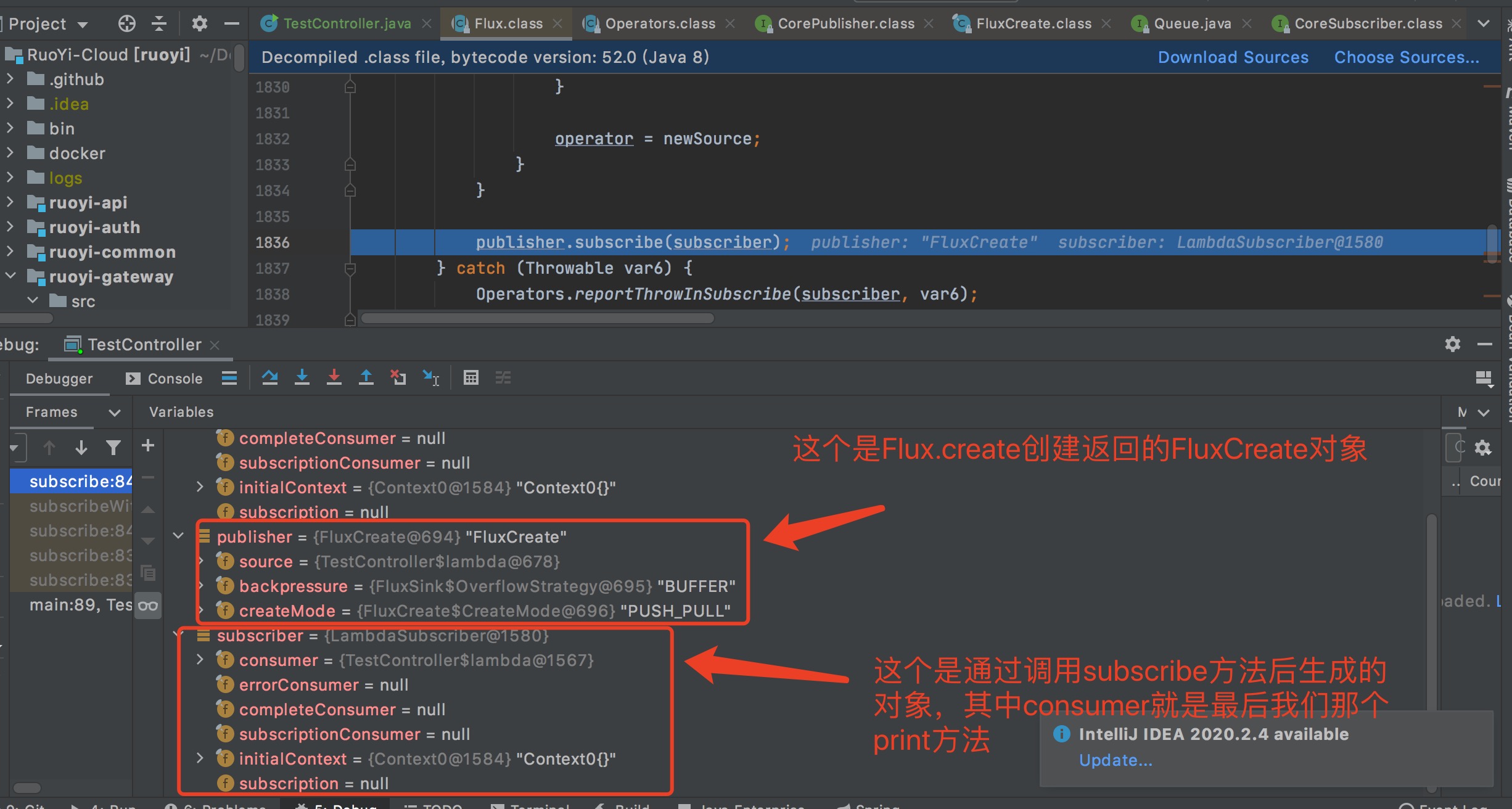
调用subscribe函数之1
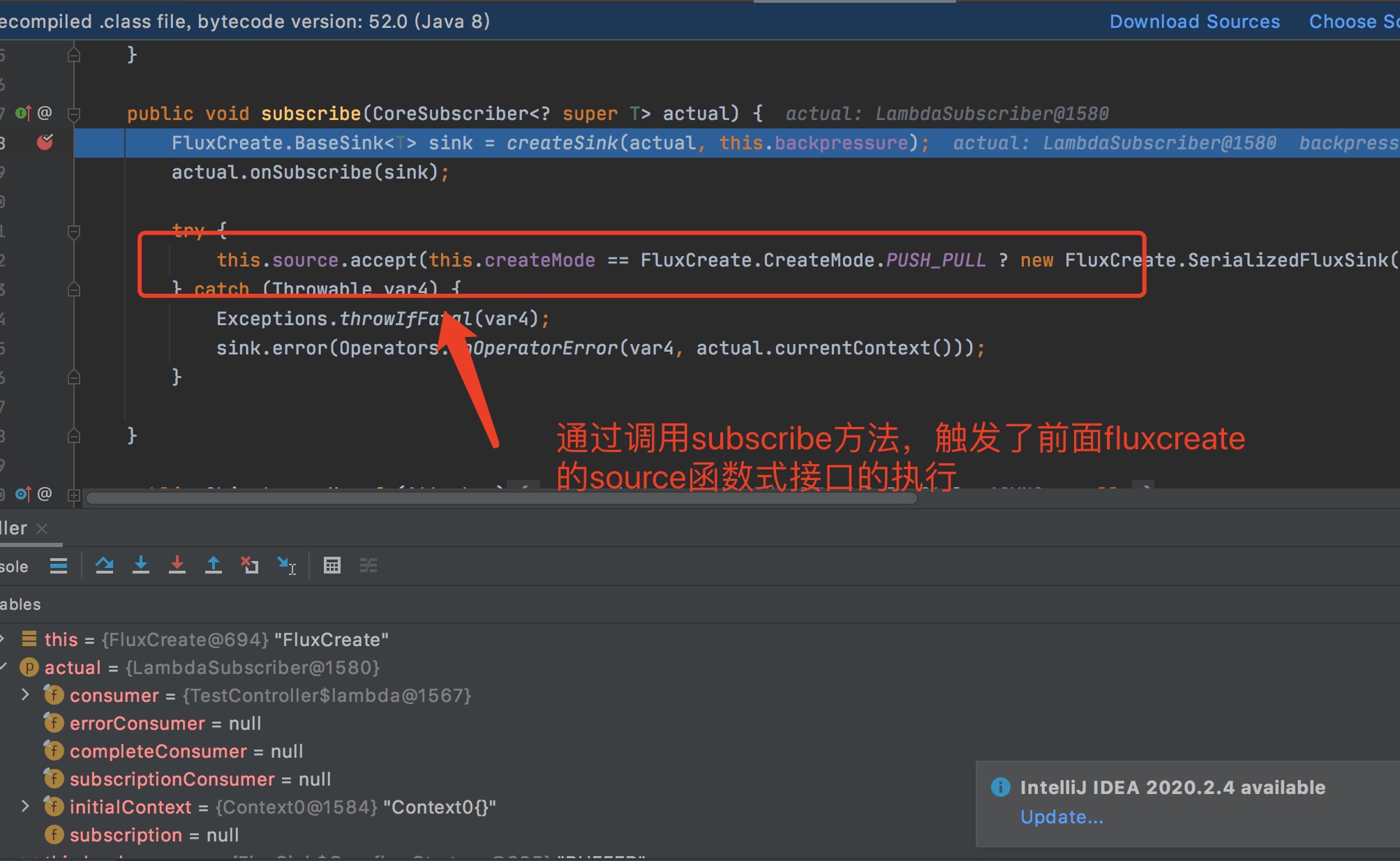
调用subscribe函数之2
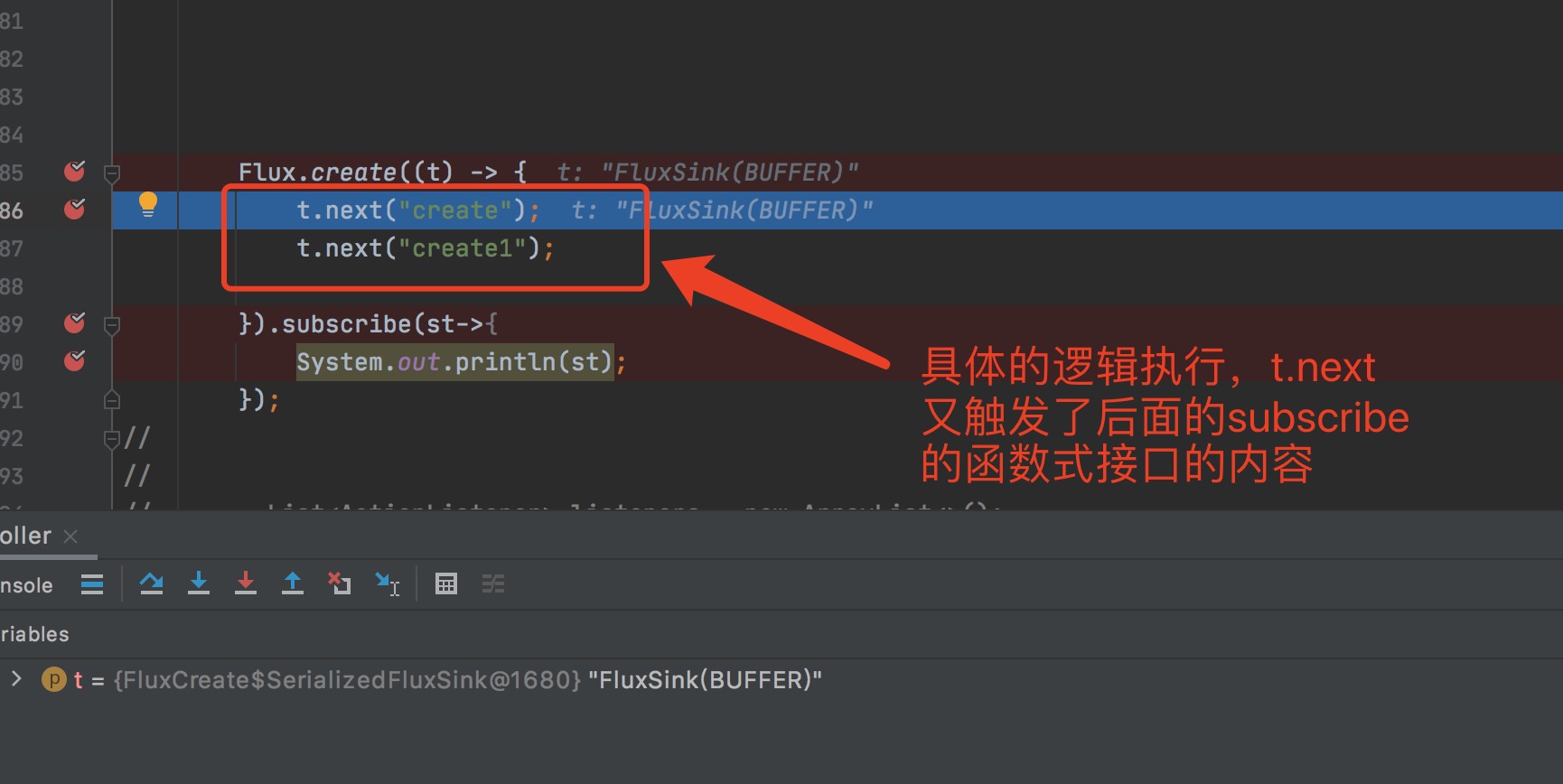
调用subscribe函数之3
没错就是通过subscribe出发了Flux.create里面的执行代码,而这个里面的每次next调用,又触发了后面的subscriber的执行,最终将结果打印出来。
Connected to the target VM, address: '127.0.0.1:53984', transport: 'socket'
create
create1
Disconnected from the target VM, address: '127.0.0.1:53984', transport: 'socket'
Process finished with exit code 0