Gne[1]发布以后,大家自动化抓取新闻正文页的需求被解决了。但随之而来的,不断有同学希望能出一个抓取列表页的工具,于是,就有了今天的 GneList。
GneList 是什么
GneList是一个浏览器插件,专门用来生成列表页的 XPath。使用这个 XPath,你可以快速获取到列表页中的每一个条目。
GneList 怎么用?
GneList 的使用非常简单,几乎不需要说明。
- 打开带有列表的页面
- 点击插件
- 输入名字,点击开始抓取
- 鼠标点击列表的前两项,GneList 会自动选中所有项
- 点击提交按钮
- 去数据库查看 XPath
怎么安装 GneList?
GneList 由两个部分组成:插件端与后端。
插件端的下载地址:https://github.com/GeneralNewsExtractor/GneList/releases/download/0.1/GneList.zip
后端的代码:https://github.com/GeneralNewsExtractor/GneListBackend ,并且后端依赖 MongoDB。
安装后端
首先确保你有一个可以连接的 MongoDB,我们假设它的 URI 是:mongodb://localhost。从 Github上面 clone 后端的代码:https://github.com/GeneralNewsExtractor/GneListBackend.git。
进入后端代码的根目录中的 config 文件夹中,你会发现一个local.yml文件。打开它,第一行填写 MongoDB 的 URI 地址,第二行是数据库名,第三行是集合名。插件生成的 XPath 会保存在这里供你的下游调用。
改好配置文件以后,回到后端的根目录,分别执行如下命令(你需要先安装 Pipenv):
pipenv install
pipenv shell
export local # 你自己创建的 yml文件的名字
uvicorn main:app --port 8800 --host 0.0.0.0 # 使用8800端口
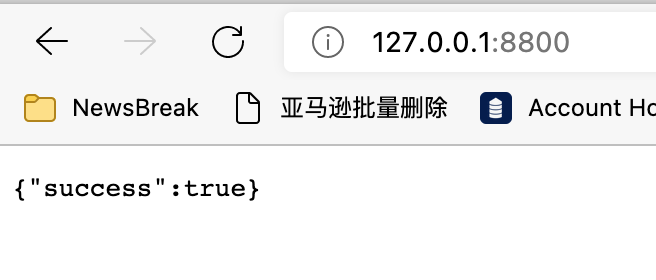
命令执行完成后,如果你使用浏览器访问http://127.0.0.1:8800,应该会看到下图的内容,说明后端搭建成功。
安装插件
GneList 插件支持所有基于 Chromium 内核的浏览器,包括但不限于 Chrome/Chromium/Edge。
从上面的地址下载GneList.zip后,把它解压到任何一个文件夹中,如下图所示:
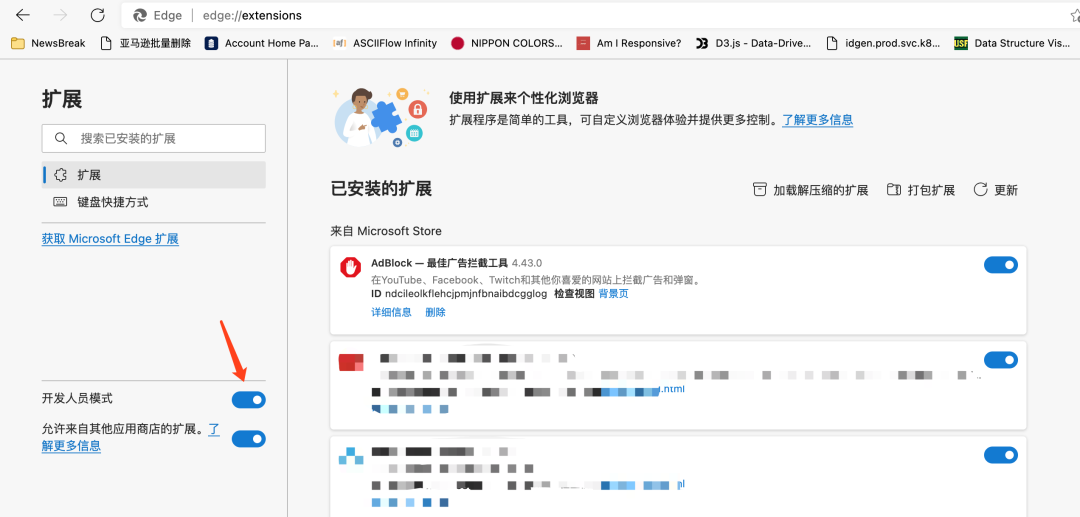
然后打开你的浏览器的插件管理页面,启动开发人员模式,例如下图是我在 Edge 中开启开发人员模式的方法。
然后点击右上角的加载解压缩的扩展,选中GneList文件夹。完成。
现在,刷新已有的列表页,或者重新开一个新的列表页,然后点击插件,试用一下吧。
管理配置页面
在插件上右键,选择扩展选项。Chrome 上面,名字可能是叫做选项或者英文Options。可以打开如下图所示的页面:
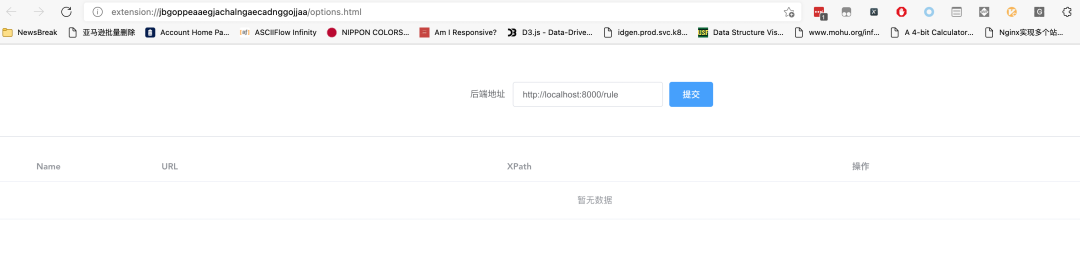
如果你没有启动后端,或者后端地址不是http://127.0.0.1:8800(例如你把后端部署在服务器上,需要使用 IP 或者域名来访问,或者端口不是8800),那么这个页面应该如上图所示。
你可以把输入框中的地址改为后端地址/rule,例如http://123.56.78.99:8888/rule。然后点击提交按钮。接下来刷新页面,你就可以看到如下图所示的内容:
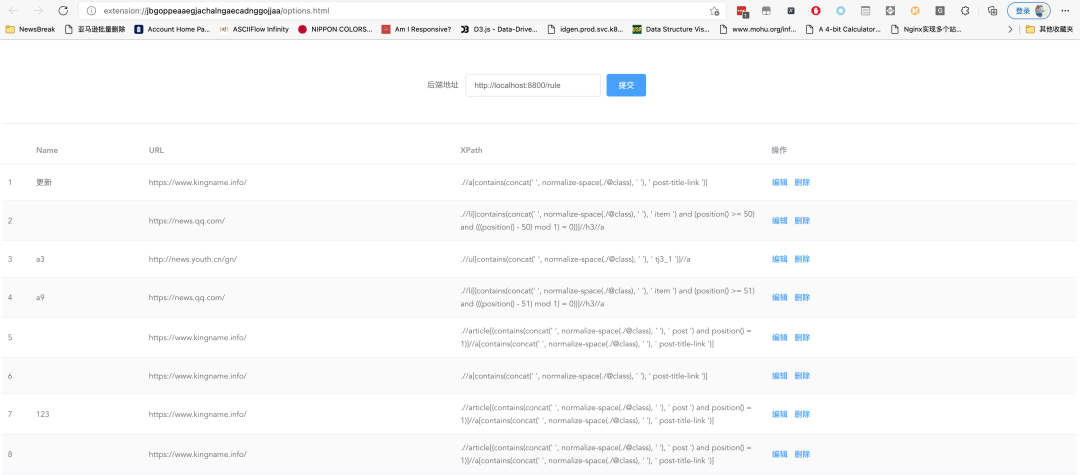
这个页面显示了你已经添加的所有网站的XPath,你可以对他们进行修改或者删除。
Q&A
为什么插件生成的 XPath 这么奇怪?
因为这些 XPath 是从 CssSelector 转成的 XPath,我用了一个第三方的 JavaScript 包。那个包转出来的就是这么奇怪。但不影响它的功能。我后面会更换更好的包,让 XPath 变得更好看。
我的爬虫怎么使用这些 XPath?
还记得一开始配置的 MongoDB 吗?让你的爬虫去里面读取就可以了。
为什么我启动插件以后,点网页上面的元素第一次没有反应?
第一次点击的时候,如果发现没有生成红框框,就多点一下。看到红框框了再点第二个元素。
GneList 的原理是什么?
接下来的几篇文章,我会介绍 GneList 的原理。如果你等不及的话,也可以到 Github上查看源代码[2]。GneList 与 Gne 一样,他们是站在其他优秀开源项目的肩膀上做出来的,尤其是受到 web-scraper-chrome-extension[3]的启发。因此,GneList也是完全开源的,允许非商业使用。
参考文献
[1] Gne: https://github.com/GeneralNewsExtractor/GeneralNewsExtractor
[2] 源代码: https://github.com/GeneralNewsExtractor/GneList
[3] web-scraper-chrome-extension: https://github.com/martinsbalodis/web-scraper-chrome-extension