













大家好! 我是来自深圳技术大学FSR实验室的同学,标题FFH就是FSRlab For Harmony!并且我也正在参加OpenHarmony成长计划从论文到开源提交研究,以后我们也会陆续在这个社区记录学习心得和体会。
引言
在涉及到网络远程通信的过程中,序列化传递的数据是不可避免的。
序列化(Serialization)其实就是将要传递的数据以及数据结构转化为位字符串(bit-string),而反序列化(Deserialization)就是将为位字符串重新转换为原始数据以及相应数据结构。
对于序列化其实有规范分类,一种是文本及二进制序列化规范(Textual and Binary Serialization Specififications),还有一种是无模式及模式驱动规范(Schema-less and Schema-driven Serialization Specififications),下面我们简单了解一下这两个规范分类。
文本及二进制序列化规范(Textual and Binary Serialization Specififications)
如果序列化规范产生的位字符串对应于文本编码中的字符序列,如对应ASCII、EBCDIC/CCSID 037或UTF-8,则序列化规范称为文本序列化规范(Textual Serialization Specififications),否则序列化规范称为二进制序列化规范(Binary Serialization Specififications)。
下图是用这两种规范分别序列化3.1415926535的例子:


文本序列化规范(Textual Serialization Specififications)
我们可以将文本序列化规范视为具备特定文本编码(如UTF-8)规则内的一组约定。用于操作该文本编码格式的计算机工具可以方便的处理对应序列化后的位字符串。
比如上图用两种规范序列化3.1415926535。
文本表示法将十进制数字编码为一个 96 bit长的数字字符序列 ,我序列化后的位字符串可以使用对应的文本编辑器(比如这里是UTF-8编码格式的编辑器)轻松地检查和处理,可读性较高。
二进制序列化规范(Binary Serialization Specififications)
还是上图用二进制规范序列化3.1415926535。
从图中序列化后的位字符串来看, 二进制序列化表示法根据其符号、指数和尾数对十进制数进行编码。所得到的位字符串只有 32 bit长。
差异及应用
从序列化后的数据占用的空间来看——二进制序列化规范比文本序列化规范表示法小三倍。然而, 我们无法使用通用的基于文本的工具来处理它,二进制序列化规范需要一个比较详细的协议来定义被序列化后的二进制流的每个字节的含义是什么。因为这个规范处理的数据空间占用比较小,因此传输效率比较高,但是可读性较低,一般用于需要数据传输效率非常高的场景。
JSON,XML以及 BSON,ProtocolBuffers是常用的序列化手段,前面两个是基于文本序列化规范的,后面两个是基于二进制序列化规范的。但是,无论是文本格式还是二进制格式,存储的都是二进制。
模式驱动及无模式序列化规范(Schema-less and Schema-driven Serialization Specififications)
如果序列化规范生成的位字符串可以在事先不了解其原始数据及其数据结构的情况下进行反序列化,则称这种规范是模式序列化规范的。否则,则称为模式驱动序列化规范。
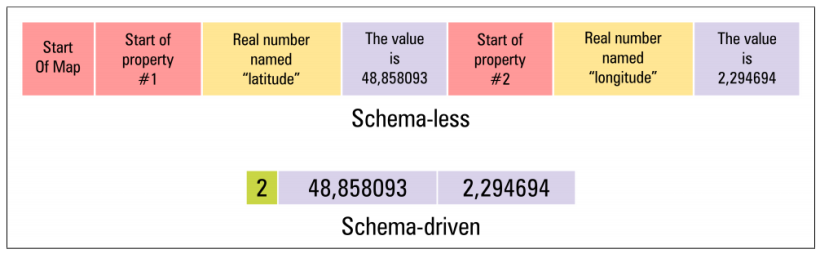
下图是两种规范分别序列化两个哈希映射的例子:

模式驱动序列化规范(Schema-driven Serialization Specififications)
模式驱动序列化规范Schema-driven Serialization Specififications)的特点就是在我们传递数据的时候,我们要事先约定传递的数据结构信息,并且将结构信息编码到序列化生成的位字符串中。
比如上图的例子是序列化两个映射。
{
"latitude":48858093,
"longitude":2294694
}
模式驱动列化后位字符串的(底部)除了作为整数前缀的映射的长度,省略了大多数自描述性信息。如果没有提前约定相关的源数据结构信息,接收者无法处理模式驱动下的位字符串,也就是不知道如何转换为原始数据结构。
无模式序列化规范(Schema-less Serialization Specififications)
还是上图的例子,无模式序列化规范(顶部)是自描述性的,原始数据结构的信息和原始数据都用不同的属性区别开来。所以数据接收者不需要提前约定,就可以对序列化后的位字符串进行处理。
差异及应用
从上面的介绍我们可以看到,模式驱动序列化规范序列化后会产生的相对节省很多空间的位字符串。因此,网络要求高效的系统倾向于采用模式驱动的序列化规范。模式驱动的序列化规范通常与空间效率有关,因此往往是二进制的。然而,也有人提出了一个基于文本JSON兼容的模式驱动序列化规范。
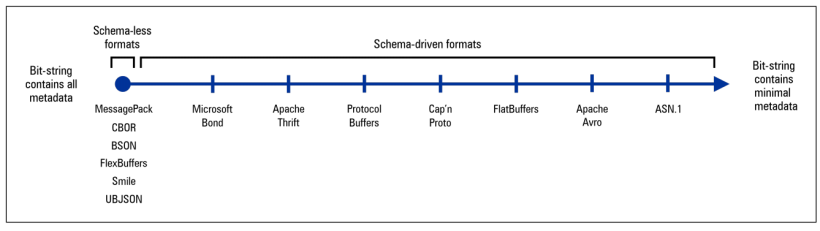
上图中表示的是用不同的序列化技术,分别序列化相同数据后,对位字符串信息量大小进行排序。(越往右信息量越小)。
我们可以根据上图直观地看到序列化后的位字符串包含的信息量,来比较无模式和模式驱动的序列化规范。
最左边的处理方法序列化后的位字符串的信息量是最大的,都是无模式序列化规范(Schema-less Serialization Specififications),比如BSON,Smile,FlexBuffers等,因为最大地保留了原始数据及其结构的信息描述。最右边的信息量是最小的,比如ASN.1,因为他们把非常多的结构信息已经在规范中提前约定,因此不需要写入序列化后的位字符串中。
存在即是合理,这些模式都没有最好最坏,每种模式都可以在特定的场景发挥对应场景需要的作用。



























