Reddit 论坛里经常有各种 AI 技术的讨论,最近有网友分享了一个开源库,号称只需要添加几行代码,模型的运行速度可以提升 10 倍以上!
文章的标题为「几乎没人知道的如何很容易地优化 AI 模型」。

一切看着都很正常,一个简单的技术分享帖子,但网友却不买账,他们认为这是无耻的「自我营销」行为。
Reddit 网站甚至还给讨论帖打上了「Shameless Self Promo」的标签。
所以,这到底是一场单纯的技术分享,还是哗众取宠的营销?
技术分享也有错?
楼主在帖子中写道,现在只需要添加几行代码,你模型的运行速度就可以提升 10 倍甚至更多,但你可能根本没有意识到怎么做。
他总结了一下目前的 AI 研究情况:
人工智能应用就像雨后春笋一样快速增长,并且越来越多的人开始加入人工智能世界,楼主也是 AI 大军中的一员。但问题是,开发人员只专注于 AI,清洗数据和训练模型。几乎没有人有硬件、编译器、计算、云等方面的背景。结果就导致了开发人员花了很多时间来提高他们软件的准确性和性能,而他们所有努力的成果都有可能被错误的软硬件耦合选择所抵消。
这个问题困扰了他很久,所以就和 Nebuly 的几个哥们儿(都曾在麻省理工学院、ETH 和 EPFL 工作过),在一个名为 nebullvm 的开源库中投入了大量精力,开发了一个让任何开发者都能使用 DL 编译器技术,即使你对硬件一无所知。
它的工作流程就是通过测试多个 DL 编译器,并选择最佳的编译器将你的 AI 模型与你的机器(GPU、CPU 等)进行最佳匹配,从而将你的 DL 模型的速度提高5-20 倍。所有这一切工作只需几行代码即可完成。
并且库也是开源的:https://github.com/nebuly-ai/nebullvm
在遭到网友大量的评价后,楼主又在帖子中贴出一段声明。他表示,这个帖子完全是关于一个开源库的,并且自推出以来在 GitHub 上一直很受欢迎(仅在第一天就有 250 多颗星)。不幸的是,这篇文章被贴上了「无耻的自我宣传」的标签,而对技术问题的回答也被其他评论所掩盖。
他恳请那些真正尝试过这个库的人再对这个帖子进行评论。
网友评价
发帖人可能也没想到,技术分享贴并没有取到预期的效果,而是被广大网友「骂」上了热搜。
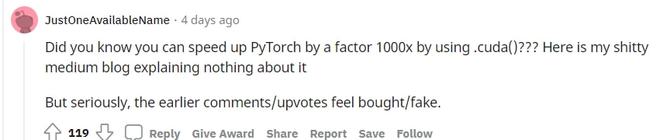
高赞网友表示,Reddit 能不能制定某种规则,反对像这样明显的自我吹嘘的营销伎俩。并且还举了一个规则例子:
人工智能很好,但使用我们的[此处插入平台/工具/库],它可以[1-10]x[更好、更快、更容易]。
我虽然喜欢了解新的库,但我讨厌从营销人员那里了解它们。
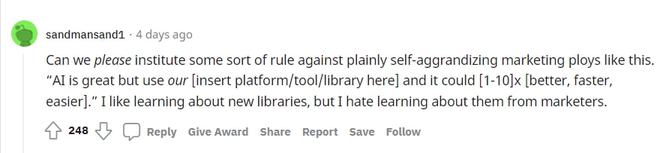
下面回复的一个网友也表示,太多科技媒体不懂技术了,他们可能都不知道在 PyTorch 里面使用 .cuda ()可以直接提升 1000 倍模型速度?
并怀疑早期的评论和点赞都是买的网络水军。
更直接的网友表示,这纯属垃圾信息,不知道这些天 reddit 发生了什么。
也有网友举了最近的另一个帖子当例子:虽然有 931 个点赞,但高赞评论几乎都是负面评价。
整个项目只是「我的朋友/我的母亲认为我做了什么与我实际做了什么」的备忘录。
对于管理层和投资者来说,这是一个漂亮的视觉效果。对于实际工作的人来说,这几乎是毫无意义的。大多数开发者使用命令行和文本的原因是你要处理如此多的数据,而视觉效果只是一个障碍而非帮助;
也有网友持不同意见:如果你考虑到有多高比例的潜水和这个 subreddit 上的人实际上并不是以 ML 为职业,也有很多学生和软件工程师,或者对这个话题有切身兴趣的人,他们只是想通过在这里盲目地支持一些东西来感觉自己是「社区」的一部分,尽管公平地说,他们也并不真正倾向于拥有必要的经验来进行批评。
还有网友表示,他知道这篇文章是一个广告,有点像「他们用错误的工具来告诉你有一个更好的方法」,但说实话,我没有看到足够的人做上述工作。我看到更多的是人们在速度上下功夫,或者如何在代码上打补丁,尽管这对 SLA 来说不是必要的。分析性能不需要很大工作量,主要是因为很多从业者来自软件工程背景,他们认为可以努力和取得进展的内容就是运行速度。
也有网友讨论技术内核,认为这只是通过 TensorRT(或其他现有的深度学习编译器)运行模型,这个项目实际上是「无事生非」。
惹民愤的库
根据 GitHub 库的 Readme 文件中可以了解到,nebullvm 是一个 All-in-one 的库,用户可以在一行代码中测试多个 DL 编译器,并将 DL 模型的推理速度提高5-20 倍。
这个资源库包含了开源的 nebullvm 包,这个开源项目旨在将所有的开源 AI 编译器统一到同一个易于使用的界面下。
作者表示,他们设计的东西超级容易使用:你只需要输入 DL 模型,就会自动得到一个优化的模型版本,用于对目标硬件进行优化。
据作者所知,目前还没有开源的库来结合市场上的各种 DL 编译器来找出最适合用户模型的编译器。他们相信,这个库可以做出强有力的贡献,使人工智能开发者越来越容易使他们的模型更有效率,而不需要花费过多的时间。
目前支持的框架包括 PyTorch 和 Tensorflow,支持的 DL 编译器包括 OpenVINO(Intel 机器), TensorRT(Nvidia GPU)和 Apache TVM。
使用方法也很简单,首先使用 pip 安装。
然后使用 nebullvm 导入 torch 或 tensorflow 的模型,以 pyTorch 为例,几行代码即可完成优化。

根据作者提供的信息和 GitHub Stars 数量来看,这个库还是靠谱的。
Reddit 网友可能是看了太多 AI 模型的夸张宣传,都发泄在了作者身上,作者也表示很无辜。科学本就是「事实求是」,才能更好地发展。
你站库作者还是 Reddit 网友?