最近,DeepMind又在强化学习领域整了个新活。
用通俗的中文来阐述,DeepMind研究者认为人类获取知识技能,更多来自于「传授」而非「训练」。
也就是说,这个全新智能体可以通过观察单个人类演示来快速学习新行为,而无需使用人工数据进行预训练。

日后你惹出祸来,不把为师说出来就行
文化传授是一种全领域通用的社会技能,它让智能体之间能以高保真度和召回率实时获取和使用彼此的经验信息。
人类社群里,正是基于此技能的积累过程,推动了累积的文化进化,在代际之间扩展了人类的技能、工具和知识。
数千年来,从航海路线到数学,从社会规范到艺术品,人类发现、进化并积累了丰富的文化知识。
定义为有效地将经验信息从一个人传递给另一个人的文化传授,是人类能力呈指数级增长的积累过程。
大到辛巴达环游七海,小到办公室同事教你用打印机。这些或显或隐的经验性技能,都是以社会性习得的「传授」、而非像如今「训练」AI的方式来传递的。
AI如果能用这种「传授」方式获得知识,不管是人机交互、还是AI自身的智能扩展,效率都将更上层楼。
为此,DeepMind利用深度强化学习技术开发了一种在人工智能体中产生零样本、高召回率的文化传授的方法。
经过训练后,人工智能体可以推断和回忆专家展示过的指引性知识。这一知识转移是实时发生的,并且可以概括以前未见过的大量任务。
给AI「传授」文化
DeepMind研究团队在程序生成的3D世界中训练和测试人工智能。
这个3D 世界中包含的彩色球形目标,嵌入在充满障碍的复杂地形中。行为者必须以正确的顺序导航抵达目标,而每种情景里目标的位置都会随机变化。
由于无法猜测顺序,因此单纯的探索策略会产生很大的惩罚。作为文化传授信息的来源,研究团队生成了一个「专家机器人」脚本,它能始终以正确的顺序触达目标。

对于一个复杂的世界来说,探测任务旨在对跳跃或蹲下的行为以及围绕垂直障碍物的导航进行清晰的演示。
在所有的探测中,人类的运动模式总是以目标为导向,接近最佳状态(不会产生任何分数惩罚),但显然与脚本机器人不同,在最初的几秒钟里需要时间来定位,并且不总是两次采取完全相同的路径。
智能体(蓝色)将跟随一个专家(红色)在世界中寻找目标,并跨越不同地形和障碍物,在专家离开之后智能体将继续完成任务。

专家为智能体

专家为人类
需要注意的是,视频中的轨迹只是为了让人类观察者方便跟踪,对于智能体来说是不可见的。
方法实现和结果
DeepMind研究团队通过排除法确定了文化传授出现所需的、最小数据量级的训练成分表,这个「入门工具包」被研究者称为 MEDAL-ADR。

这些训练成分包括「记忆存储」 (M)、「专家退出」 (ED)、「对专家的注意力偏见」 (AL) 和「自动域随机化」 (ADR)。
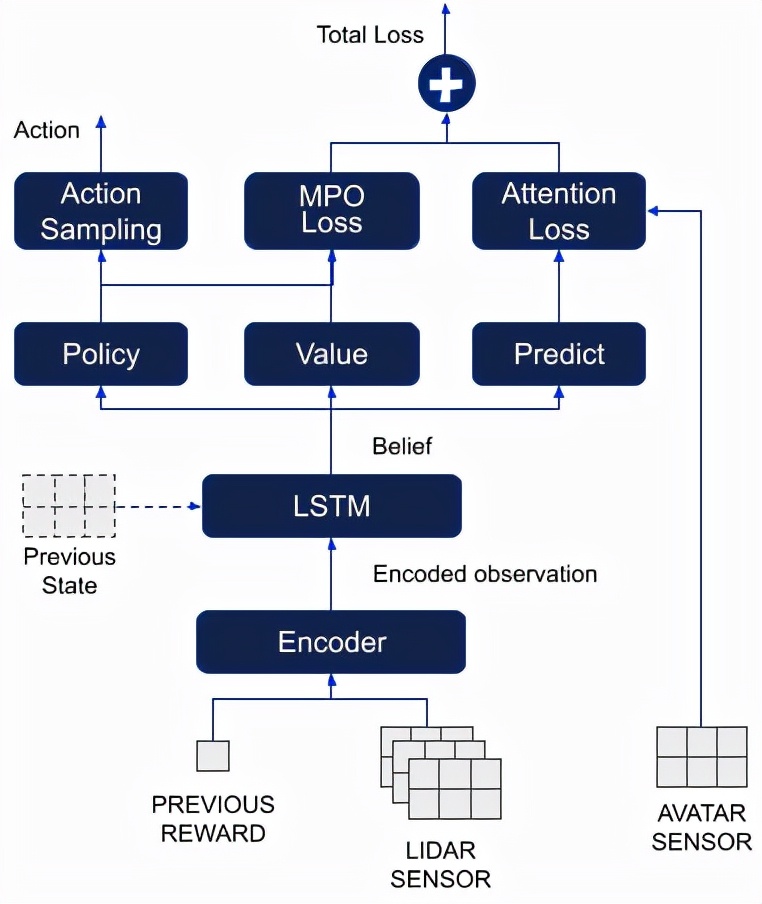
智能体的结构
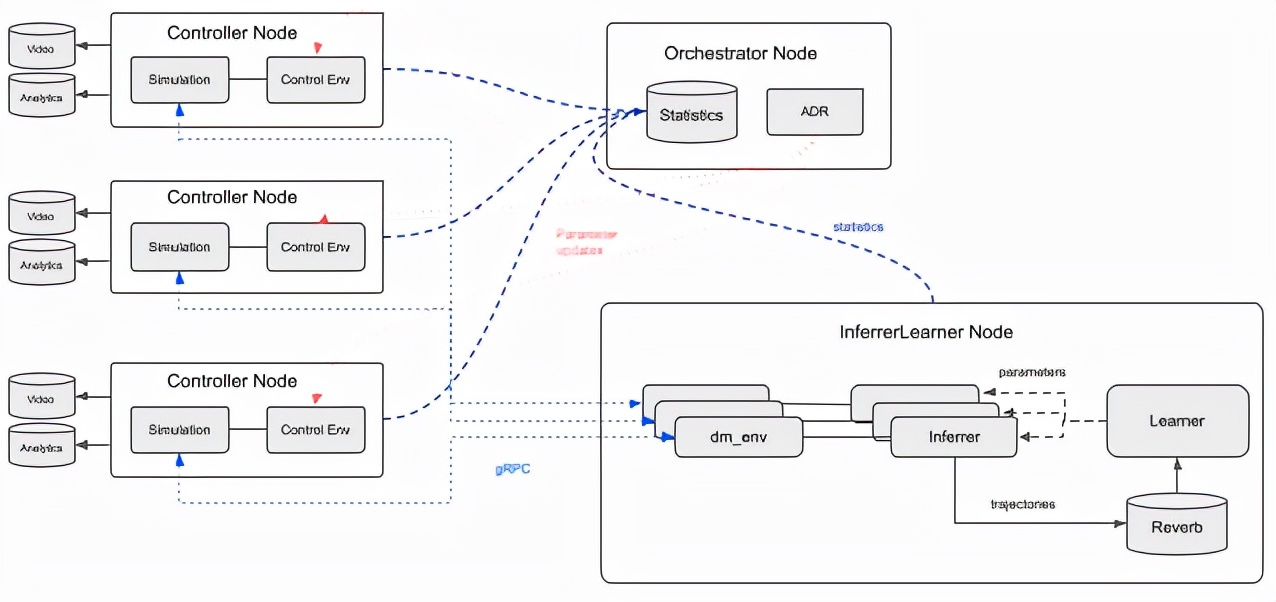
训练架构
为了更好地感知世界,DeepMind给智能体安装了一圈激光雷达传感器。
通过从身上全方位地发出射线,智能体就能get到与障碍物之间的距离了。

在训练期间,智能体会在某个时间点出现的社会学习行为的进展。

训练8.6亿步:初始探索

训练15.9亿步:模仿

训练18.2亿步:记忆

训练26.7亿步:独立
泛化:世界空间
世界空间的参数是由地形的大小和颠簸程度以及障碍物的密度决定的。
为了量化空间普适性,DeepMind通过障碍物密度和世界大小的笛卡尔乘积来生成游戏地图。
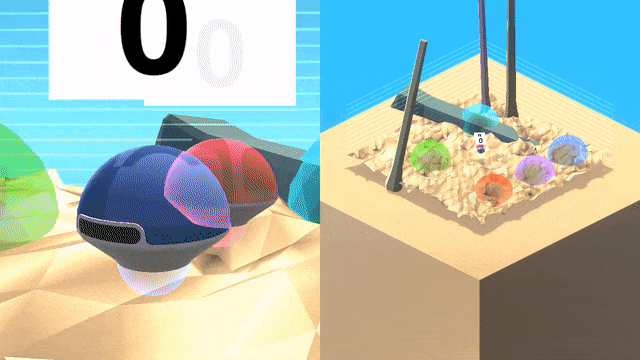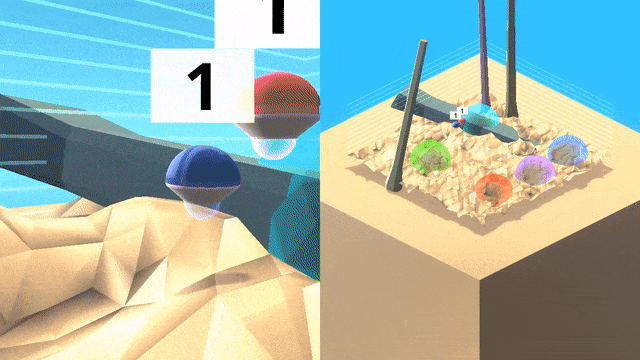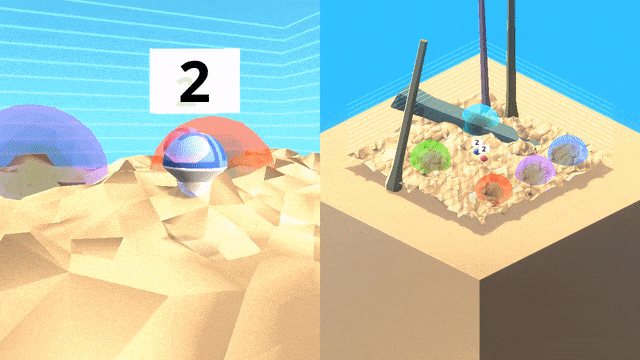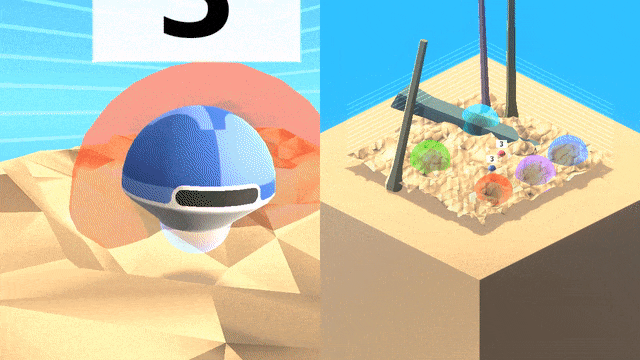
障碍物复杂度: 1.0,地形复杂度: 1.0
泛化:游戏空间
游戏空间是由世界上的目标数量以及它们之间的正确导航路径所包含的交叉点数量来定义的。
为了量化空间普适性,DeepMind在「N-目标,M-交叉」游戏的规则内生成智能体的任务。

目标球体:5,路径交叉:4
泛化:专家空间
专家的空间是由专家在世界范围内采取的速度和行动分布来定义的。
专家可以是脚本化的机器人,也可以是具有更真实和多样化运动模式的人类玩家。
为了量化空间普适性,DeepMind利用运动速度和动作噪声的笛卡尔乘积,生成了与专家机器人的行为。

噪声: 0.5,最大速度: 13.0

噪声: 0.0,最大速度: 17.0
可以看到,没有噪声时机器人会直奔目标,而添加了噪声之后则会有明显的「犹豫」。而当专家的速度设置得过快时,智能体到后面就已经要完全追不上了。
经过反复测试,DeepMind开发的智能体在一系列具有挑战性的任务中都要优于所对比的控制变量,包括最先进的方法ME-AL。
此外,文化传授在知识转输中的泛化程度出人意料地好,并且人工智能体在专家退出后很久还能回忆起示范。
研究团队观察人工智能体的「大脑」,发现了负责编码社会信息和目标状态的、具有惊人可解释性的「神经元」。
总而言之,DeepMind开发的流程能训练出足够灵活、高召回率、实时文化传授的智能体,而无需在训练流水线中使用人工数据。这为文化演进成为开发通用人工智能的算法铺平了道路。
开发团队
Lei Zhang是DeepMind为此项目新组建的「通用文化智能团队」(Cultural General Intelligence Team)的成员。

他是多伦多大学电气工程博士,本科、硕学位也均在多伦多大学获得。
在深度强化学习、通用模型、卷积神经网络、循环神经网络、分布式训练、特征探测算法等领域有成就。
曾是OpenAI机械手解决魔方难题团队的成员,现是DeepMind研究科学家。